LMFlow#
一个可扩展、便捷且高效的大型机器学习模型微调工具箱,旨在实现用户友好、快速可靠,并向整个社区开放。
支持常见骨干模型(LLaMA、Galactica、GPT-2等)
使用LoRA技术参数极少(LLaMA 33B模型仅需25MB存储空间)
在7B/33B模型上与ChatGPT表现相当。
整个流程(数据、模型、调优、推理)都是开源的。
简介#
大型基础模型(如扩展语言模型)的显著成就,展示了它们超越传统方法、实现类人智能的卓越能力。尽管这些模型的可及性日益提高,但仍需针对特定任务进行微调,同时保持其整体AI能力。我们很高兴推出轻量级工具包,该工具包采用精心设计且易于扩展的API。该工具简化了公开基础模型的微调和推理流程,以最大化其效能。
我们已经对该工具包进行了全面测试,并很高兴在Github上将其开源。
功能#
任务调优#
任务调优的目标是提升语言模型在特定领域(如医学或数学)的熟练度。通过这种方式,模型能够获取领域专业知识,从而更好地适应目标主题。
例如,如果使用医疗数据集进行任务调优,语言模型可以获取可应用于其他医疗数据集的医学知识。
为了强调其重要性,我们在PubMedQA和MedMCQA数据集上对LLaMA模型进行了任务调优,并评估了它们的性能。我们观察到在领域内(PubMedQA、MedMCQA)和领域外(MedQA-USMLE)数据集上都有显著改进。
PubMedQA |
MedQA-USMLE |
MedMCQA |
平均 |
|
|---|---|---|---|---|
人类 (通过) |
60.0 |
50.0 |
||
人类(专家) |
78.0 |
87.0 |
90.0 |
85.0 |
InstructGPT 175B |
73.2 |
46.0 |
44.0 |
54.4 |
ChatGPT |
63.9 |
57.0 |
44.7 |
55.2 |
LLaMA 7B |
5.2 |
27.1 |
24.3 |
18.9 |
LLaMA 33B |
1.8 |
43.4 |
30.3 |
25.2 |
任务调优的LLaMA 7B(完整版) |
75.1 |
44.5 |
49.9 |
56.5 |
任务调优的LLaMA 33B (LoRA) |
74 |
51.3 |
50.2 |
58.5 |
此外,我们还测试了MMLU性能,以进一步验证任务调优技术在领域外的鲁棒性。
MMLU任务 |
解剖学 |
临床知识 |
大学生物学 |
大学医学 |
医学遗传学 |
专业医学 |
|---|---|---|---|---|---|---|
LLaMA 33B |
39.2 |
40.3 |
44.4 |
32.9 |
36 |
43.0 |
Galactica 30B |
32.5 |
26 |
30.5 |
25.4 |
39 |
23.1 |
Galactica 120B |
58.5 |
59.2 |
68.7 |
57.2 |
68.0 |
59.6 |
OPT 175B |
28.9 |
21.9 |
30.6 |
- |
35.0 |
27.9 |
BLOOM 176B |
37 |
29.8 |
28.5 |
- |
36.0 |
25.4 |
Gopher 280B |
56.3 |
67.2 |
70.8 |
60.1 |
69.0 |
64.0 |
GPT3.5 175B |
56.3 |
69.8 |
72.2 |
61.3 |
70 |
70.2 |
任务调优的LLaMA 33B (LoRA) |
51.8 |
65.2 |
70.1 |
58.3 |
65.6 |
66.5 |
指令调优#
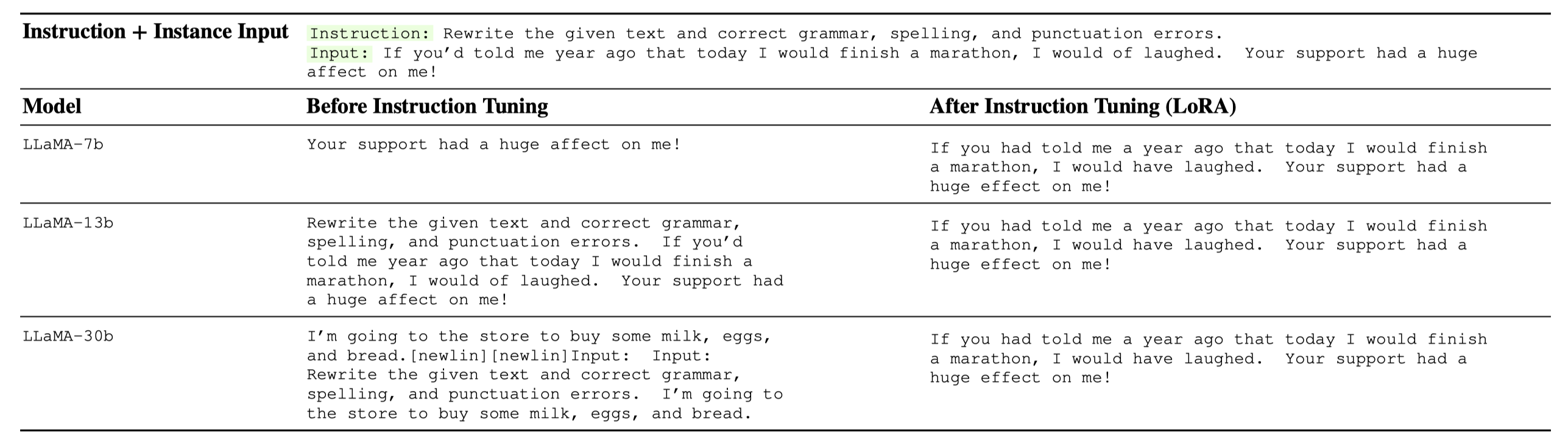
指令调优是一种通过训练语言模型遵循自然语言命令或指令来提高其性能的技术。这包括人类语言中常见的正负示例、提示、约束和其他元素。指令调优的主要目标是提升模型在多项任务上的表现能力,并更有效地泛化到新任务或未见过的任务。这是通过教导模型理解并整合与当前任务相关的各种语言线索和约束来实现的。指令调优是自然语言处理、机器学习及相关领域中广泛使用的强大技术。通过提升语言模型理解和遵循自然语言命令的能力,这种方法可以帮助在广泛应用中释放新的性能和生产效率水平。
我们在下方列出了一些示例。完整的示例列表保存为一个Jsonl文件。






安装#
该软件包可以通过以下命令从源代码安装:
git clone https://github.com/OptimalScale/LMFlow.git
conda create -n lmflow python=3.9 -y
conda activate lmflow
conda install mpi4py
pip install -e .
检查点#
我们已经准备了经过调优的LLaMA模型(包括任务调优和指令调优)。
请参考README。
内容#
愿景#
大家好!我们很高兴地宣布即将发布我们的代码仓库,其中包含完整的LLM训练流程,让用户能够快速构建自己的语言模型并进行高效训练。
我们的代码仓库不仅仅是一个简单的模型;它包含了完整的训练流程、模型优化和测试工具。您可以用它来构建各种类型的语言模型,包括对话模型、问答模型和文本生成模型等。
此外,我们的目标是创建一个开放民主的大语言模型共享平台,让人们可以分享他们的检查点和经验,共同提升社区技能。我们欢迎所有对大语言模型感兴趣的人参与进来,与我们一起建设一个开放友好的社区!
无论您是初学者还是专家,我们相信您都能从这个平台中受益。让我们一起努力,打造一个充满活力与创新的LLM社区!
![]()

引用#
@misc{lmflow,
author = {Shizhe Diao and Rui Pan and Hanze Dong and KaShun Shum and Jipeng Zhang and Wei Xiong and Tong Zhang},
title = {LMFlow: An Extensible Toolkit for Finetuning and Inference of Large Foundation Models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://optimalscale.github.io/LMFlow/}},
}
免责声明#
本软件包旨在为大模型调优提供一个高效且用户友好的流程。其功能仅供参考,由用户自行决定使用。但需注意,数据及预训练模型的准备工作完全由用户负责。本软件包不保证用户准备组件的准确性、完整性、适用性或合法性。用户必须知晓并承担与模型及数据准备相关的所有风险与责任,在使用本软件包前应寻求法律、商业及技术建议。对于因用户不当准备数据及预训练模型导致的直接、间接、特殊、附带或结果性损害,本流程概不负责。
必须重点强调的是,模型生成的结果基于概率模型,与此流程无直接关联。本流程不保证结果的准确性、可靠性、适用性及合法性。因此,用户必须充分认知结果相关的风险与责任,在依赖模型生成结果前应寻求法律、商业及技术建议。对于用户因依赖模型结果而导致的任何直接、间接、特殊、附带或衍生损害,本流程概不负责。
支持#
如需任何帮助,请提交一个Github issue。