贡献流程#
欢迎来到AdalFlow社区!
我们努力使过程简单明了,但它总有改进的空间。 在Discord或Github Discussion上分享您的建议。
快速开始#
Github issues 是找到你第一个任务的最佳地方。寻找标记为 good first issue 的任务。
按照开发要点设置您的环境并开始编码、测试和文档编写。
查看PR和审查流程以完成审查和迭代过程。 我们的目标是最大化您的学习和库的质量。
注意
你可以使用👍来表示你希望解决某个特定问题。
第一部分:结构化#
为了更深入地了解,我们将解释我们的仓库结构、问题跟踪和标签系统。
仓库结构#
我们的仓库有一个清晰的结构,分为六个子目录:
.
├── .github/
├── adalflow/
│ ├── adalflow/
│ ├── tests/
| ├── pyproject.toml
├── docs/
| |── pyproject.toml
├── tutorials/
├── use_cases/
├── benchmarks/
├── notebooks/
| ├── tutorials/
| ├── use_cases/
| ├── benchmarks/
├── .env_example
├── .gitignore
├── .pre-commit-config.yaml
├── LICENSE.md
├── README.md
├── poetry.lock
├── pyproject.toml
/adalflow目录包含 AdalFlow 库的源代码,包括其实现、测试和一个专用的 pyproject.toml 文件。/docs目录存放了 AdalFlow 库的文档,并且包含了它自己的 pyproject.toml 文件。 我们使用 reStructuredText 来编写文档。更多详情,请参考./docs目录下的 README.md。此外,它还包括以下目录:
/tutorials: 包含AdalFlow库的教程,针对每个核心功能或类。/use_cases: 涵盖各种用例,可能是端到端的应用程序,甚至包括自动优化。/benchmarks: 包括用于评估该库与其他库或框架的基准测试。
/notebooks目录包含所有用于 教程、用例 和 基准测试 的笔记本。
问题与标签系统#
我们使用问题来管理错误、功能和讨论。 为了组织它们,我们精心设计了15个标签。
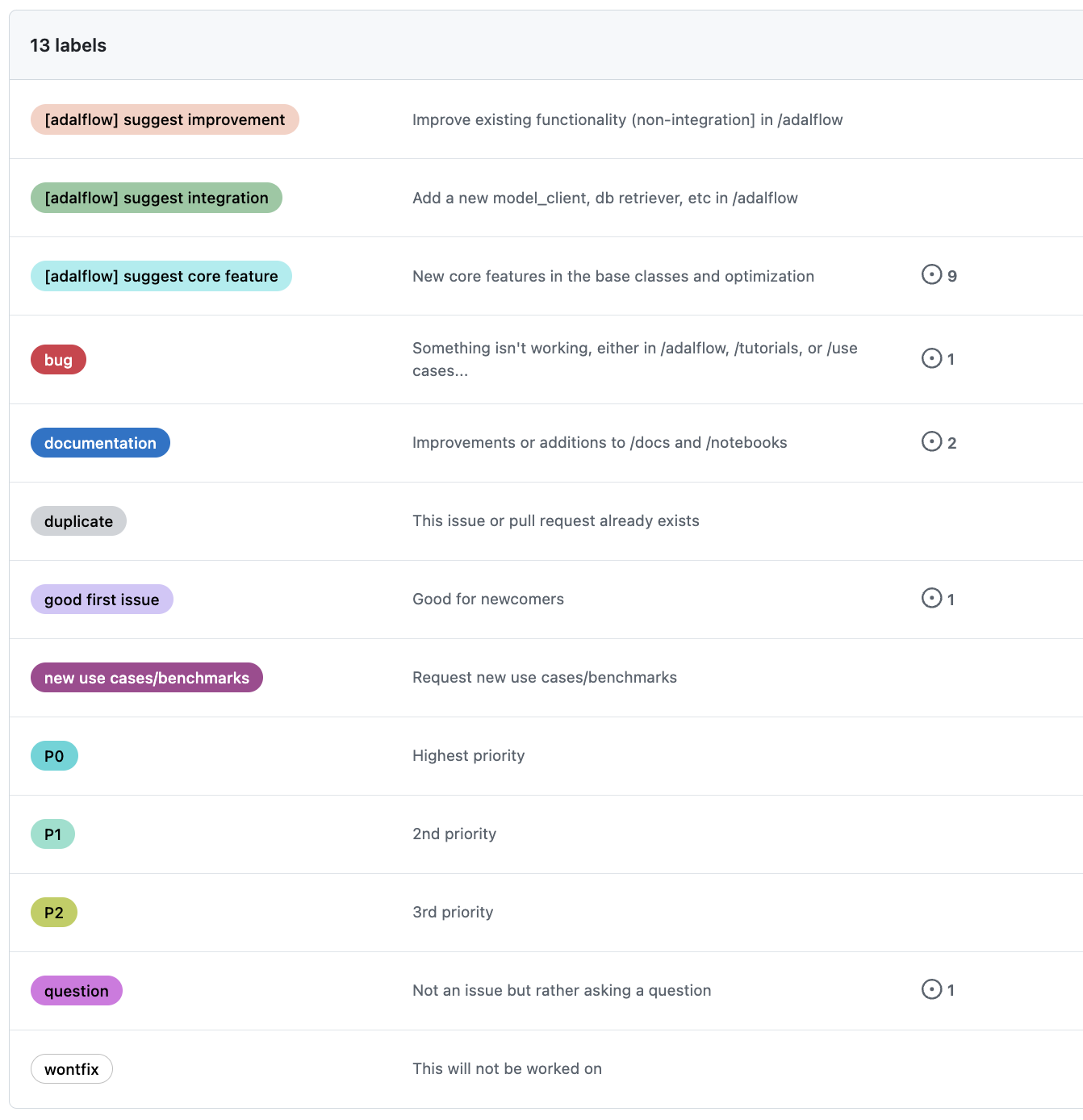
类型: 问题的类型,例如错误、功能或讨论。#
我们并行使用三类标签:
问题类型:共有7种类型的问题。
[adalflow]表示问题与AdalFlow源代码在/adalflow目录中有关。
在此目录中,
/adalflow包含源代码,/tests包含测试代码。 这里的3个标签包括:integration,improvement,core feature。我们使用
bug来标记所有目录中与代码相关的问题。documentation用于/docs,/tutorials,/use_cases,/benchmarks, 和/notebooks目录中的项目。new use cases/benchmarks用于/use_cases和/benchmarks中的问题。question用于一般查询。
如何继续:有4个标签。
good first issue适用于新贡献者的任务。wontfix表示库中不会解决的问题。duplicate表示已经在其他地方跟踪的问题。help wanted表示需要优先信号、讨论和pr。
优先级:有3个级别。
P0用于最高优先级的问题。P1用于中等优先级。P2用于最低优先级。
注意
以上14个标签均可用于问题和PR。
ready-for-pr专用于问题,表示该问题已准备好进行PR。ready-to-go专属于PR,表示PR已准备好合并。
下表将提供所有内容的快速概览。
问题类型(7个标签) |
如何继续(3个标签) |
优先级(3个标签) |
|---|---|---|
[adalflow] 建议集成 |
||
[adalflow] 建议改进 |
不会修复 |
P0 |
[adalflow] 建议核心功能 |
好的第一个问题 |
|
新用例/基准 |
重复(聚合)并关闭一个 |
P1 |
[adalflow] 错误 |
需要帮助 |
P2 |
问题 |
|
|
文档 |
|
如何创建一个问题#
我们创建了五个模板,以便您轻松创建问题。
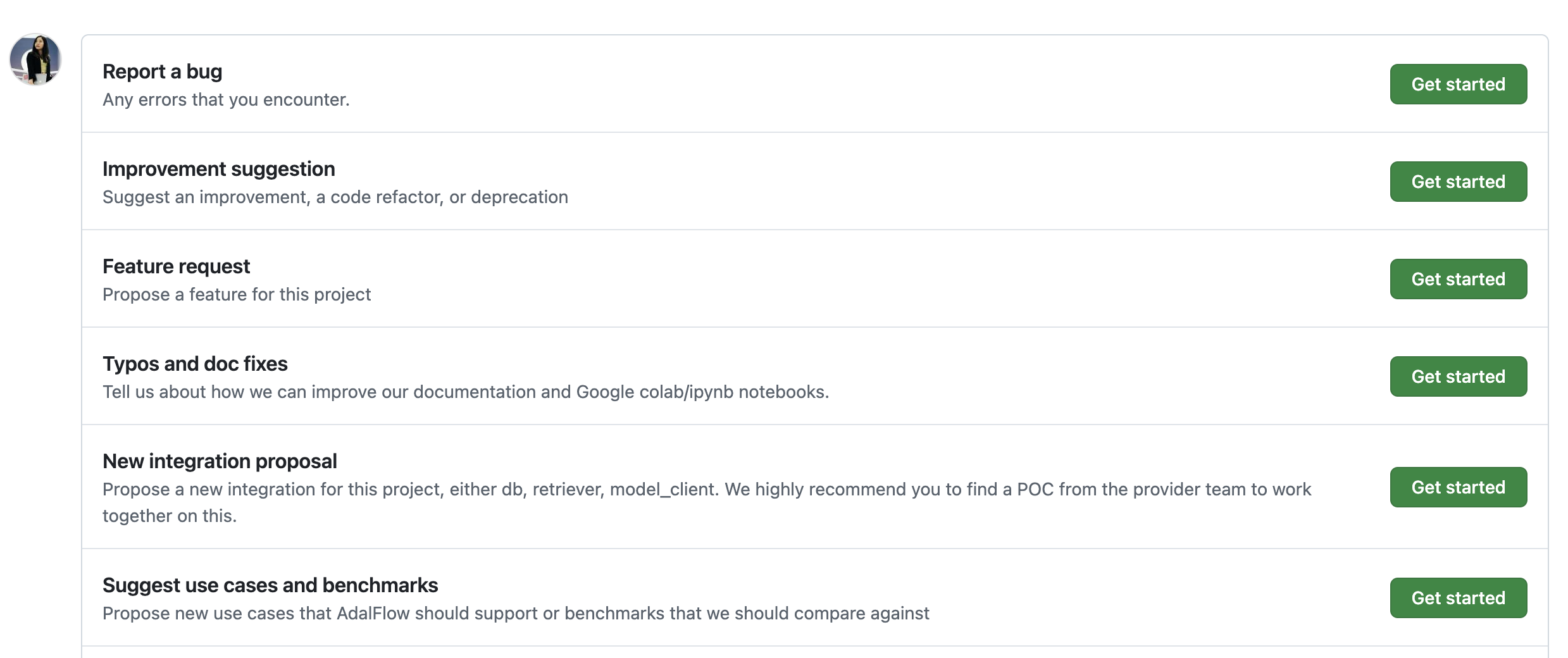
创建问题的五个模板#
每个模板会自动为问题分配相关标签。
如何分配优先级#
虽然我们的团队根据我们的最佳判断来标记优先级,但我们也欢迎社区的意见,以帮助我们确定问题的优先级。
你可以使用👍来表示某个问题对你有多重要。
我们将考虑# of 👍 / time_period作为设置优先级的额外信号。
第二部分:贡献内容#
本节提供了关于每个问题如何与我们的代码库相关的更多详细信息。 我们将包括示例PR以帮助澄清这些联系。
下表提供了快速概览。 更多关于每种贡献类型的详细信息见第三部分。
标签 |
贡献建议 |
示例问题/拉取请求 |
|---|---|---|
[adalflow] 错误 |
修复在问题中报告的错误,可能与 /adalflow 代码或 /tutorials/user_cases/benchmarks 相关。 |
|
[adalflow] 建议集成 |
添加与模型推理SDKs(model_client)或数据库检索器(retriever)或工具或其他库/框架的新集成。 |
Ollama集成请求 和 PR 97。这通常涉及测试、教程和文档。 |
[adalflow] 建议改进 |
增强现有功能以提高性能或可用性,可能与/adalflow代码或/tutorials/user_cases/benchmarks相关。 |
|
[adalflow] 建议核心功能 |
在/adalflow目录中开发新的核心功能,例如text_splitter或memory。 |
|
新的使用案例/基准测试 |
为adalflow设计基准测试或提出新的使用案例。 |
|
文档 |
改进/docs或/notebooks目录下的现有文档,或为现有代码创建新文档。 |
|
问题 |
回答用户查询或提供关于库的澄清。 |
第三部分:贡献步骤#
一旦你确定了想要贡献的内容,按照以下步骤来确保你的贡献质量:
跟踪它。 如果问题尚未存在,请创建一个问题。
学习足够的背景知识。 阅读AdalFlow内外的相关文档和代码。 这包括:
这将帮助你理解贡献所需的一切。 我们将在下一节中为每种类型的贡献提供示例。
对于集成,你需要了解相关的SDK和API。
对于文档,你需要了解文档的结构和写作风格。
创建解决方案提案并收集意见。 在问题评论中写下你的解决方案提案。 或者,你可以使用像
Google Doc或Colab这样的公开访问工具来分享你的提案。 AdalFlow 团队和社区将在你开始编码之前进行审查并提供反馈。 当提案准备好进行PR时,团队和核心贡献者可以将其标记为ready-for-pr。 这一步对于复杂功能尤为重要。你也可以在我们的 Discord 上讨论你的提案。开始工作。 遵循PR和审查流程,开始编码、测试、文档编写和审查。
集成一个模型客户端#
所有现有的模型客户端都位于/adalflow/adalflow/components/model_client目录中。 教程模型客户端将帮助您理解基类及其设计方式。
一般来说,OpenAI SDK 正逐渐成为行业标准。 你可以通过这两者之间的差异来衡量你的目标SDK。 但总的来说,OPENAI 集成包括:编码、测试、文档。
编码包括:
一个继承自基类 ModelClient 的 OpenAIClient 类。
在adalflow/pyproject.toml文件中将sdk包添加为可选包。
在adalflow/adalflow/utils/lazy_import.py文件中将sdk包添加为延迟导入。
在adalflow/adalflow/components/model_client/__init__.py文件中调用延迟导入。
在adalflow/adalflow/__init__.py文件中导入新的客户端,以便我们可以直接从adalflow包中调用它。
测试包括:
在adalflow/tests/目录中创建一个测试文件test_XX_client.py。你可以使用test_openai_client.py作为参考。
将包添加到adalflow/pyproject.toml文件中的[tool.poetry.group.test.dependencies]部分。
在测试文件中为新客户端添加测试用例。
按照adalflow/tests/README.md中的说明运行测试。
文档包括:
在tutorials目录中添加如何使用新客户端的示例。你可以使用tutorials/ollama_client_note.py作为参考。
确保你在根目录的pyproject.toml文件中的[tool.poetry.dependencies]部分添加了新的客户端包。
确保API参考在docs目录中正确呈现。 例如,对于ollama_client,你需要在docs/source/apis/components/index.rst文件中添加以下行:
components.model_client.ollama_client
在根目录的.env_example文件中添加示例API配置。
这个ollama_client PR是一个很好的例子,展示了如何集成一个新的模型客户端。
集成数据库检索器#
所有现有的retrievers都位于/adalflow/adalflow/components/retriever目录中。 教程retriever将帮助您理解基类及其设计方式。
这个过程与集成模型客户端非常相似。对于文档,请确保在retriever中添加一个示例。
这个qdrant_retriever PR是一个很好的例子,展示了如何集成一个新的数据库检索器。
为现有/新教程/用例/基准添加笔记本#
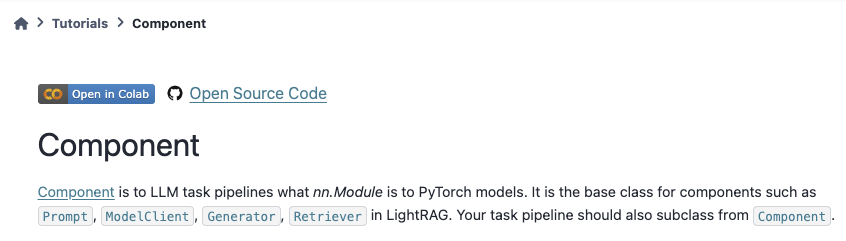
注意
关于如何添加新笔记本,请遵循notebooks目录中的README.md。
教程
在我们的文档中,每个教程都附有两个代码文件:一个在/tutorials中的XX_note.py和一个在/notebooks/tutorials中的adalflow_XX.ipynb。 你可以帮助添加教程中缺失的代码文件,并确保像上图那样在文档中链接它们。 这里是一个添加新教程的示例问题和拉取请求:Issue 192 和 PR 261。
使用案例
在我们的文档中,每个use_cases都附有/use_cases中的源代码和/notebooks/use_cases中的笔记本。对于我们现有的用例,我们并不总是有相应的笔记本。您可以帮助为现有的用例添加缺失的笔记本。
基准测试
到目前为止,我们仍在处理/benchmarks目录中的代码。我们需要帮助来添加文档以及代码。
第四部分:拉取请求流程#
准备代码库#
在开始拉取请求之前,您需要按照以下步骤和这个Github官方分叉指南进行操作:
Fork 仓库。 你可以通过点击仓库页面右上角的 Fork 按钮来 fork 仓库。
克隆仓库。 您可以在终端中运行以下命令来克隆仓库:
git clone your_forked_repository_url
同步你的分支。 同时,确保你的仓库与原始所有者的仓库保持同步。你可以通过运行以下命令来实现:
git remote -v
你将不会在列表中看到我们的仓库。你可以通过运行以下命令来添加它:
git remote add upstream https://github.com/SylphAI-Inc/AdalFlow.git
现在,当你运行 git remote -v 时,你将看到上游仓库。 然后,我们可以通过运行以下命令将你的分支与上游仓库同步:
git fetch upstream git checkout main git merge upstream/main
注意:`fetch` 将从上游仓库获取更改,但不会将它们合并到你的本地分支。`merge` 将把上游仓库的更改合并到你的本地分支。 更多详细信息,请参考 Github 官方同步分支指南。
创建一个新分支。 创建一个新分支以确保您的更改与主代码库隔离。您可以通过运行以下命令来实现:
git checkout -b
_ 同样,您始终可以使用步骤3来将您的分支与上游仓库同步。 此外,您可以使用以下命令进行同步:
git fetch --all --prune git rebase upstream/main # 按照git的指示解决冲突 git push origin your_branch_name
处理你的PR#
设置预提交钩子。 我们在根目录中有一个.pre-commit-config.yaml文件。 确保你已经设置了预提交钩子。我们建议你在poetry环境中进行设置。 以下步骤将帮助你设置根poetry环境和预提交钩子: 如果你还没有安装poetry,请先安装:
pip install poetry
你可以通过运行以下命令来安装依赖项:
poetry install然后你可以通过运行以下命令来激活环境:
poetry shell然后,通过运行以下命令来安装预提交钩子:
pre-commit install现在,即使你不在poetry环境中,下次你也可以从`/adalflow`目录开始提交更改。 如果你有更多问题,可以参考预提交官方指南。
提交您的更改。 一旦您完成了更改,您可以通过运行以下命令来提交它们:
git add . git commit -m "您的提交信息" git push origin your_branch_name
如果您遇到“权限被拒绝”的问题,您可以参考这个medium博客寻求帮助。
创建一个拉取请求。 前往你在Github上的分叉仓库,点击新建拉取请求按钮。确保你为基础分支和比较分支选择了正确的分支。 这里我们有一个默认的PR模板供你填写。
填写PR模板。 确保你填写了PR模板中的必要信息。这将帮助审阅者更好地理解你的更改。
提交PR 我们鼓励您尽早提交PR,即使它尚未准备好进行审查。您可以通过以下方式将其标记为草稿: 1. 在PR页面上点击草稿按钮。 2. 在PR标题中添加[WIP]。
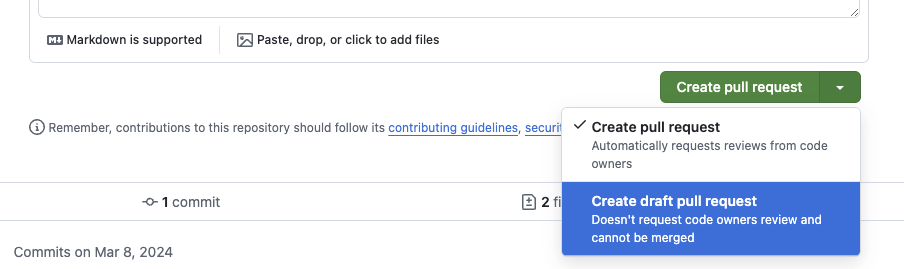
创建一个草稿PR#
迭代你的PR。 一旦你提交了PR,审阅者将会审阅你的更改并提供反馈。你可以通过进行必要的更改并将它们推送到你的分支来迭代你的PR。审阅者将会再次审阅你的更改。
合并你的PR。 一旦你的PR被批准,审阅者将为你合并PR。你也可以通过点击PR页面上的合并按钮来合并你的PR。
第五部分:审查流程#
目前,我们将使用PyTorch lightning的审查指南。