数据(数据库/管道)#
本说明的目的是提供关于LLM应用中的数据、数据建模和数据存储的概述,以及AdalFlow如何处理数据。 我们将涵盖:
关于如何表示重要数据的数据模型。
用于处理LLM应用程序中的数据的数据管道。
本地数据库提供内存数据管理和存储。
使用fsspec和SQLAlchemy处理云数据库的示例。
注意
本笔记更侧重于处理执行LLM任务所需的数据。 数据集,包括输入和真实输出加载以及数据集将在优化部分中讨论。
到目前为止,我们已经了解了我们的核心组件如Generator、Embedder和Retriever在没有数据缓存/数据库和强制数据格式的情况下如何工作,以读取和写入数据。
然而,在现实世界的LLM应用中,我们无法避免处理数据存储。
我们从中检索上下文的文档可能很大,并且可以以表格或图形的形式存储在文件系统或数据库中。
我们经常需要将大量数据(如文本分割、嵌入和BM25中的idf)在数据管道中预处理到云数据库中。
我们需要将记录、日志写入文件或数据库以进行监控和调试,例如失败的llm调用。
当涉及到状态重要的应用程序时,如游戏和聊天机器人,我们需要存储状态和对话历史。
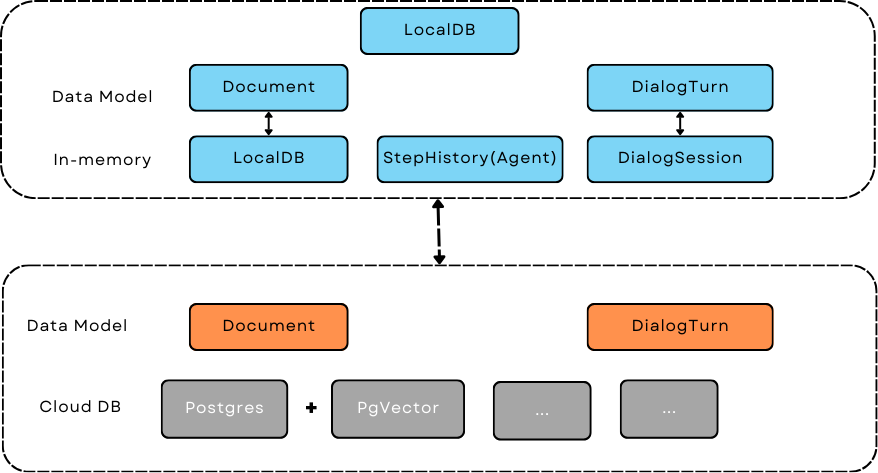
数据模型和数据库#
数据模型#
除了拥有统一的GeneratorOutput、EmbedderOutput和RetrieverOutput数据格式外,我们主要提供core.types.Document和core.types.DialogTurn来帮助处理文本文档和对话历史记录以及数据存储。
我们将解释Document和DialogTurn的设计。在本笔记中,我们将继续使用我们在之前笔记中使用的这些简单文档:
org_documents =[
{
"title": "The Impact of Renewable Energy on the Economy",
"content": "Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure."
},
{
"title": "Understanding Solar Panels",
"content": "Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels."
},
{
"title": "Pros and Cons of Solar Energy",
"content": "While solar energy offers substantial environmental benefits, such as reducing carbon footprints and pollution, it also has downsides. The production of solar panels can lead to hazardous waste, and large solar farms require significant land, which can disrupt local ecosystems."
},
{
"title": "Renewable Energy and Its Effects",
"content": "Renewable energy sources like wind, solar, and hydro power play a crucial role in combating climate change. They do not produce greenhouse gases during operation, making them essential for sustainable development. However, the initial setup and material sourcing for these technologies can still have environmental impacts."
}
]
turns = [
{
"user": "What are the benefits of renewable energy?",
"system": "I can see you are interested in renewable energy. Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.",
"user_time": "2021-09-01T12:00:00Z",
"system_time": "2021-09-01T12:00:01Z"
},
{
"user": "How do solar panels impact the environment?",
"system": "Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.",
"user_time": "2021-09-01T12:00:02Z",
"system_time": "2021-09-01T12:00:03Z"
}
]
文档#
core.types.Document 被用作文档数据结构,并在LLM应用程序中辅助文本处理。
一个通用的文档/文本容器,包含字段
text,meta_data, 和id。使用字段
parent_doc_id和order辅助文本分割。协助嵌入字段
vector。协助将其用作LLM的提示,包含字段
estimated_num_tokens。
这就是为什么像TextSplitter和ToEmbeddings这样的数据处理组件需要Document作为每个数据项的输入。
创建文档
from adalflow.core.types import Document
documents = [Document(text=doc['content'], meta_data={'title': doc['title']}) for doc in org_documents]
print(documents)
打印输出将是:
[Document(id=73c12be3-7844-435b-8678-2e8e63041698, text='Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute...', meta_data={'title': 'The Impact of Renewable Energy on the Economy'}, vector=[], parent_doc_id=None, order=None, score=None), Document(id=7a17ed45-569a-4206-9670-5316efd58d58, text='Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock ele...', meta_data={'title': 'Understanding Solar Panels'}, vector=[], parent_doc_id=None, order=None, score=None), Document(id=bcbc6ff9-518a-405a-8b0d-840021aa1953, text='While solar energy offers substantial environmental benefits, such as reducing carbon footprints and...', meta_data={'title': 'Pros and Cons of Solar Energy'}, vector=[], parent_doc_id=None, order=None, score=None), Document(id=ec910402-f98f-4077-a958-7335e34ee0c6, text='Renewable energy sources like wind, solar, and hydro power play a crucial role in combating climate ...', meta_data={'title': 'Renewable Energy and Its Effects'}, vector=[], parent_doc_id=None, order=None, score=None)]
对话轮次#
core.types.DialogTurn 仅用作LLM应用程序中用户-助手对话轮次的数据结构。
如果我们需要对对话历史应用文本处理管道,我们将使用我们的文本容器``Document``来存储我们需要使用的文本。
注意
对于Document和DialogTurn,我们在database.sqlalchemy.model`(:class:`database.sqlalchemy.modoel.Document)中有一个等效的类来处理SQL数据库中的数据持久化。
以下是如何从turns中获取DialogTurn列表的方法:
from adalflow.core.types import DialogTurn, UserQuery, AssistantResponse
dialog_turns = [
DialogTurn(
user_query=UserQuery(query_str=turn["user"]),
assistant_response=AssistantResponse(response_str=turn["system"]),
user_query_timestamp=turn["user_time"],
assistant_response_timestamp=turn["system_time"],
)
for turn in turns
]
print(dialog_turns)
打印输出将是:
[DialogTurn(id='f2eddc77-4667-43f5-87e0-fd11f12958b3', user_id=None, session_id=None, order=None, user_query=UserQuery(query_str='What are the benefits of renewable energy?', metadata=None), assistant_response=AssistantResponse(response_str='I can see you are interested in renewable energy. Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.', metadata=None), user_query_timestamp='2021-09-01T12:00:00Z', assistant_response_timestamp='2021-09-01T12:00:01Z', metadata=None, vector=None), DialogTurn(id='b2dbdf2f-f513-493d-aaa8-c77c98ac260f', user_id=None, session_id=None, order=None, user_query=UserQuery(query_str='How do solar panels impact the environment?', metadata=None), assistant_response=AssistantResponse(response_str='Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.', metadata=None), user_query_timestamp='2021-09-01T12:00:02Z', assistant_response_timestamp='2021-09-01T12:00:03Z', metadata=None, vector=None)]
数据管道#
让我们看看如何编写一个数据管道,通过使用中间数据模型Document来处理任何形式的文本数据。
目前,我们在components.data_process模块中有两个数据处理组件:TextSplitter和ToEmbeddings。
我们将使用ord_documents和一系列DialogTurn作为示例。由于我们的数据管道设计为与Document结构一起工作,我们只需添加一个映射函数来将原始数据转换为Document。
# mapping function for org_documents
def map_to_document(doc: Dict) -> Document:
return Document(text=doc['content'], meta_data={'title': doc['title']})
def map_dialogturn_to_document(turn: DialogTurn) -> Document:
# it can be important to keep the original data's id
return Document(id=turn.id, text=turn.user_query.query_str + ' ' + turn.assistant_response.response_str)
您可以参考Text Splitter了解更多关于如何使用TextSplitter的详细信息。
ToEmbeddings是BatchEmbedder上的一个协调器,它将为Document列表生成嵌入,并将嵌入存储为List[Float]在每个Document的vector字段中。
Sequential 可以轻松地用于将多个数据处理组件链接在一起。
以下是形成数据管道的代码:
from adalflow.core.embedder import Embedder
from adalflow.core.types import ModelClientType
from adalflow.components.data_process import TextSplitter, ToEmbeddings
from adalflow.core.component import Sequential
model_kwargs = {
"model": "text-embedding-3-small",
"dimensions": 256,
"encoding_format": "float",
}
splitter_config = {
"split_by": "word",
"split_length": 50,
"split_overlap": 10
}
splitter = TextSplitter(**splitter_config)
embedder = Embedder(model_client =ModelClientType.OPENAI(), model_kwargs=model_kwargs)
embedder_transformer = ToEmbeddings(embedder, batch_size=2)
data_transformer = Sequential(splitter, embedder_transformer)
print(data_transformer)
打印输出将是:
Sequential(
(0): TextSplitter(split_by=word, split_length=50, split_overlap=10)
(1): ToEmbeddings(
batch_size=2
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
(batch_embedder): BatchEmbedder(
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
)
)
)
现在,将数据管道应用于 dialog_turns:
dialog_turns_as_documents = [map_dialogturn_to_document(turn) for turn in dialog_turns]
print(dialog_turns_as_documents)
# apply data transformation to the documents
output = data_transformer(dialog_turns_as_documents)
print(output)
打印输出将是:
[Document(id=e3b48bcc-df68-43a4-aa81-93922b619293, text='What are the benefits of renewable energy? I can see you are interested in renewable energy. Renewab...', meta_data=None, vector=[], parent_doc_id=None, order=None, score=None), Document(id=21f0385d-d19a-442f-ae99-910e984cdb65, text='How do solar panels impact the environment? Solar panels convert sunlight into electricity by allowi...', meta_data=None, vector=[], parent_doc_id=None, order=None, score=None)]
Splitting documents: 100%|██████████| 2/2 [00:00<00:00, 609.37it/s]
Batch embedding documents: 100%|██████████| 2/2 [00:00<00:00, 3.79it/s]
Adding embeddings to documents from batch: 2it [00:00, 10205.12it/s]
[Document(id=e636facc-8bc3-483b-afbd-37e1d8ff0526, text='What are the benefits of renewable energy? I can see you are interested in renewable energy. Renewab...', meta_data=None, vector='len: 256', parent_doc_id=e3b48bcc-df68-43a4-aa81-93922b619293, order=0, score=None), Document(id=06ea7cea-c4e4-4f5f-b3e9-2e6f4452827b, text='and installation sectors. The growth in renewable energy usage boosts local economies through increa...', meta_data=None, vector='len: 256', parent_doc_id=e3b48bcc-df68-43a4-aa81-93922b619293, order=1, score=None), Document(id=0018af12-c8fc-49ff-ab64-a2acf8ba4c27, text='How do solar panels impact the environment? Solar panels convert sunlight into electricity by allowi...', meta_data=None, vector='len: 256', parent_doc_id=21f0385d-d19a-442f-ae99-910e984cdb65, order=0, score=None), Document(id=c5431397-2a78-4870-abce-353b738c1b71, text='has been found to have a significant positive effect on the environment by reducing the reliance on ...', meta_data=None, vector='len: 256', parent_doc_id=21f0385d-d19a-442f-ae99-910e984cdb65, order=1, score=None)]
本地数据库#
LocalDB 类
core.db.LocalDB 是一个强大的数据管理类:
它通过CRUD操作管理任何数据类型的数据项序列。
跟踪并应用数据转换/处理管道到其项目。
将项目的状态保存到文件或从文件加载,包括所有数据和数据转换器记录。
此表列出了其属性和重要方法:
属性/方法 |
描述 |
|
|---|---|---|
属性 |
|
数据库的名称。 |
|
数据库中的项目列表。 |
|
|
用于存储转换后项目的字典。 |
|
|
用于存储变压器设置的字典。 |
|
|
一个字典,用于存储与transformer一起使用的映射函数。 |
|
数据增删改查操作 |
|
将项目列表加载到数据库 |
|
将项目添加到 |
|
|
通过索引添加单个项目或追加到末尾。可选择应用转换器。 |
|
|
通过索引移除项目或弹出最后一个项目。可选择同时移除转换后的数据。假设转换后的项目与原始项目具有相同的索引。可能并不总是如此。 |
|
|
将所有属性重置为初始状态。 |
|
数据处理 |
|
注册一个数据转换到数据库以供后续使用。 |
|
通过键对数据应用转换器。 |
|
|
注册并应用一个转换器到数据上。 |
|
数据持久化 |
|
将数据库的状态保存到一个pickle文件中。 |
|
一个类方法,用于从pickle文件中加载数据库的状态。 |
现在,我们终于有了一个很好的方法来组织重要数据,沿着其管道,如数据库中的Document和DialogTurn。
数据加载和CRUD操作
让我们创建一个LocalDB来管理dialog_turns及其数据处理管道:
from adalflow.core.db import LocalDB
dialog_turn_db = LocalDB('dialog_turns')
print(dialog_turn_db)
dialog_turn_db.load(dialog_turns)
print(dialog_turn_db)
打印输出将是:
LocalDB(name='dialog_turns', items=[], transformed_items={}, transformer_setups={}, mapper_setups={})
LocalDB(name='dialog_turns', items=[DialogTurn(id='f2eddc77-4667-43f5-87e0-fd11f12958b3', user_id=None, session_id=None, order=None, user_query=UserQuery(query_str='What are the benefits of renewable energy?', metadata=None), assistant_response=AssistantResponse(response_str='I can see you are interested in renewable energy. Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.', metadata=None), user_query_timestamp='2021-09-01T12:00:00Z', assistant_response_timestamp='2021-09-01T12:00:01Z', metadata=None, vector=None), DialogTurn(id='b2dbdf2f-f513-493d-aaa8-c77c98ac260f', user_id=None, session_id=None, order=None, user_query=UserQuery(query_str='How do solar panels impact the environment?', metadata=None), assistant_response=AssistantResponse(response_str='Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.', metadata=None), user_query_timestamp='2021-09-01T12:00:02Z', assistant_response_timestamp='2021-09-01T12:00:03Z', metadata=None, vector=None)], transformed_items={}, transformer_setups={}, mapper_setups={})
数据处理/转换管道(例如TextSplitter和Embedder)
我们注册并应用上一节中的转换器到存储在dialog_turn_db中的数据:
key = "split_and_embed"
dialog_turn_db.transform(data_transformer, map_fn=map_dialogturn_to_document, key=key)
print(dialog_turn_db.transformed_items[key])
print(dialog_turn_db.transformer_setups[key])
print(dialog_turn_db.mapper_setups[key])
打印输出将是:
Splitting documents: 100%|██████████| 2/2 [00:00<00:00, 2167.04it/s]
Batch embedding documents: 100%|██████████| 2/2 [00:00<00:00, 5.46it/s]
Adding embeddings to documents from batch: 2it [00:00, 63072.24it/s]
[Document(id=64987b2b-b6c6-4eb4-9122-02448e3fd394, text='What are the benefits of renewable energy? I can see you are interested in renewable energy. Renewab...', meta_data=None, vector='len: 256', parent_doc_id=f2eddc77-4667-43f5-87e0-fd11f12958b3, order=0, score=None), Document(id=9a424d4c-4bd0-48ce-aba9-7a4f86892556, text='and installation sectors. The growth in renewable energy usage boosts local economies through increa...', meta_data=None, vector='len: 256', parent_doc_id=f2eddc77-4667-43f5-87e0-fd11f12958b3, order=1, score=None), Document(id=45efa517-8e52-4780-bdbd-2329ffa8d4b6, text='How do solar panels impact the environment? Solar panels convert sunlight into electricity by allowi...', meta_data=None, vector='len: 256', parent_doc_id=b2dbdf2f-f513-493d-aaa8-c77c98ac260f, order=0, score=None), Document(id=bc0ff7f6-27cc-4e24-8c3e-9435ed755e20, text='has been found to have a significant positive effect on the environment by reducing the reliance on ...', meta_data=None, vector='len: 256', parent_doc_id=b2dbdf2f-f513-493d-aaa8-c77c98ac260f, order=1, score=None)]
Sequential(
(0): TextSplitter(split_by=word, split_length=50, split_overlap=10)
(1): ToEmbeddings(
batch_size=2
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
(batch_embedder): BatchEmbedder(
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
)
)
)
<function map_dialogturn_to_document at 0x10fb26f20>
保存/重新加载数据
dialog_turn_db.save_state(filepath='.storage/dialog_turns.pkl')
reloaded_dialog_turn_db = LocalDB.load_state(filepath='.storage/dialog_turns.pkl')
print(str(dialog_turn_db.__dict__) == str(restored_dialog_turn_db.__dict__))
如果两个数据库相同,这将打印 True。我们可以使用重新加载的数据库类来继续处理数据。
这个数据类对于研究人员和开发人员来说非常有用,可以运行和跟踪本地实验以优化数据处理流程。
使用生成器进行对话的CRUD操作
我们将拥有一个聊天机器人,并将新的对话轮次添加到数据库中。当对话太长,无法适应您的LLM模型的令牌限制时,您可以轻松地使用检索器来控制对话历史的长度。
首先,让我们准备生成器。我们将使用默认提示中的input_str和chat_history_str。
这还将利用DialogTurn从DataClass继承的能力来快速形成chat_history_str。
from adalflow.core import Generator
llm_kwargs = {
"model": "gpt-3.5-turbo"
}
generator = Generator(model_client = ModelClientType.OPENAI(), model_kwargs=llm_kwargs)
以下是形成提示的代码,我们将使用generator.print_prompt()来检查提示的样子:
from typing import List
input_str = "What are the benefits of renewable energy? Did I ask this before?"
def format_chat_history_str(turns: List[DialogTurn]) -> str:
chat_history_str = []
for turn in turns:
chat_history_str.append(
turn.to_yaml(
exclude=[
"id",
"user_id",
"session_id",
"user_query_timestamp",
"assistant_response_timestamp",
"order",
"metadata",
"vector",
],
)
)
chat_history_str = '\n_________\n'.join(chat_history_str)
return chat_history_str
chat_history_str = format_chat_history_str(dialog_turn_db.items[0:1])
print(generator.print_prompt(input_str=input_str, chat_history_str=chat_history_str))
打印输出将是:
Prompt:
<SYS>
<CHAT_HISTORY>
user_query:
metadata: null
query_str: What are the benefits of renewable energy?
assistant_response:
metadata: null
response_str: I can see you are interested in renewable energy. Renewable energy technologies
not only help in reducing greenhouse gas emissions but also contribute significantly
to the economy by creating jobs in the manufacturing and installation sectors. The
growth in renewable energy usage boosts local economies through increased investment
in technology and infrastructure
</CHAT_HISTORY>
</SYS>
<User>
What are the benefits of renewable energy? Did I ask this before?
</User>
You:
现在,让我们与生成器聊天并将对话轮次添加到数据库中:
response = generator(prompt_kwargs={"input_str": input_str, "chat_history_str": chat_history_str})
print(response)
# add the turn and apply the transformer
new_turn = DialogTurn(
user_query=UserQuery(query_str=input_str),
assistant_response=AssistantResponse(response_str=response.data),
)
dialog_turn_db.add(new_turn, apply_transformer=True)
print(dialog_turn_db.length, len(dialog_turn_db.transformed_items[key]))
# 3 6
与检索器一起使用
假设我们的历史记录太长,无法适应令牌限制。
我们将使用语义检索器从数据库中获取相关的分块文档。
然后,我们将通过比较parent_doc_id与文档的id来找到其相关的对话轮次,而不是直接使用这些文档。
以下是准备相关对话轮次的代码。
from adalflow.components.retriever.faiss_retriever import FAISSRetriever
retriever = FAISSRetriever(top_k=3, embedder=embedder)
embeddings = [item.vector for item in dialog_turn_db.transformed_items[key]]
retriever.build_index_from_documents(documents=embeddings)
# get the relevant documents
top_k_documents = retriever(input=input_str)
# get the relevant dialog turns
parent_doc_ids = set(
[
dialog_turn_db.transformed_items[key][doc_index].parent_doc_id
for doc_index in top_k_documents[0].doc_indices
]
)
condition_fn = lambda item: item.id in parent_doc_ids
fetched_dialog_turns = [item for item in dialog_turn_db.items if condition_fn(item)]
现在,我们可以使用fetched_dialog_turns来继续与生成器的对话。
云数据库#
请查看Retriever以使用云数据库作为存储和检索器。
文件读取#
我们目前不提供集成,但使用像fsspec这样的文件读取包应该很容易与我们的数据处理流程一起使用。
API 参考
附加资源