适配器激活与组合
通过adapters,可以将针对不同任务训练的多个适配器以所谓的适配器组合方式结合使用。为实现这种组合,adapters提供了一套模块化且灵活的概念,用于定义模型输入应如何流经可用的适配器。这使得诸如堆叠(MAD-X)和融合(AdapterFusion)适配器,甚至更复杂的适配器配置成为可能。
适配器激活
所有适配器组合魔法发生的唯一位置是模型类的active_adapters属性。
最简单的情况下,您可以在此设置单个适配器的名称来激活它:
model.active_adapters = "adapter_name"
重要
active_adapters 定义了在模型的前向和后向传播过程中使用哪些可用的适配器。这意味着:
在使用
add_adapter()或load_adapter()将适配器添加到模型之前,您无法激活该适配器。未在
active_adapters配置中提及的所有适配器将被忽略,即使它们可能已加载到模型中。因此,在添加适配器后,请确保激活它。
注意,我们也可以使用set_active_adapters方法,通过model.set_active_adapters("adapter_name")实现相同的功能。
或者,AdapterSetup上下文管理器允许在不改变模型状态的情况下动态配置激活的设置:
from adapters import AdapterSetup
model = ...
model.add_adapter("adapter_name")
with AdapterSetup("adapter_name"):
# will use the adapter named "adapter_name" in the forward pass
outputs = model(**inputs)
组合模块 - 概述
高级设置的基本构建模块是源自AdapterCompositionBlock的对象,每个对象代表了一种组合单个适配器的不同可能性。下表概述了支持的组合块及其在不同适配器方法中的支持情况。
| 模块 | 瓶颈 适配器 |
前缀 调优 |
压缩器 | LoRA | (IA)³ | Vera | 提示调优 |
|---|---|---|---|---|---|---|---|
Stack |
✅ | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | |
Fuse |
✅ | ✅ | |||||
Split |
✅ | ✅ | |||||
BatchSplit |
✅ | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | |
MultiTask |
✅ | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | |
Parallel |
✅ | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | |
| Output averaging | ✅ | ✅ | ✅(*) | ✅(*) | ✅(*) | ||
| Parameter averaging | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
(*) 除Deberta、GPT-2和ModernBERT之外。
接下来,我们将更详细地介绍所有组合模块。
堆栈
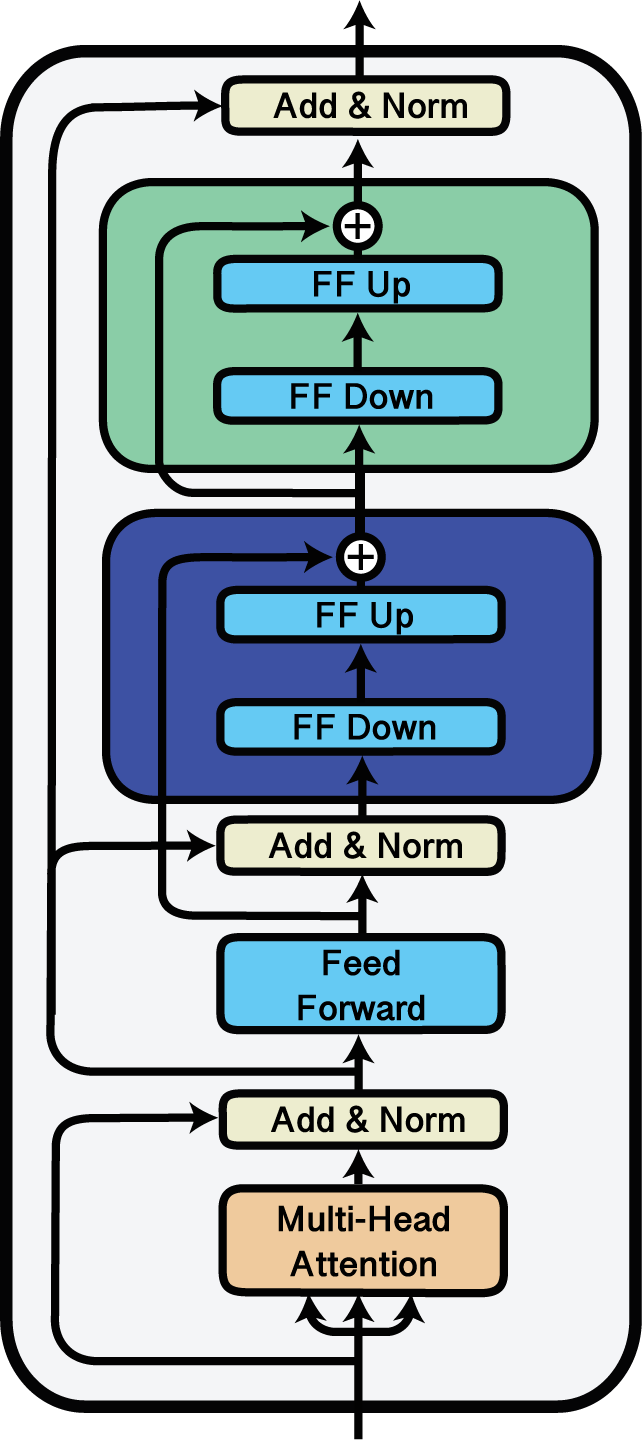
使用'Stack'块堆叠适配器。
Stack模块可用于将多个适配器堆叠在一起。这种适配器组合方式被应用于例如MAD-X框架中的跨语言迁移(Pfeiffer et al., 2020),其中语言适配器和任务适配器会被堆叠使用。了解更多信息,请查看这个Colab笔记本中关于跨语言迁移的内容。
在以下示例中,我们将适配器 a、b 和 c 进行堆叠,使得在每一层中,输入首先通过 a,a 的输出随后输入到 b,最后 b 的输出输入到 c。
import adapters.composition as ac
// ...
model.add_adapter("a")
model.add_adapter("b")
model.add_adapter("c")
model.active_adapters = ac.Stack("a", "b", "c")
注意
当使用堆叠进行前缀调优时,堆叠的前缀会从右到左添加到输入状态之前,即Stack("a", "b", "c")会先将"a"的前缀状态添加到输入向量,然后将"b"添加到结果向量,依此类推。
Fuse
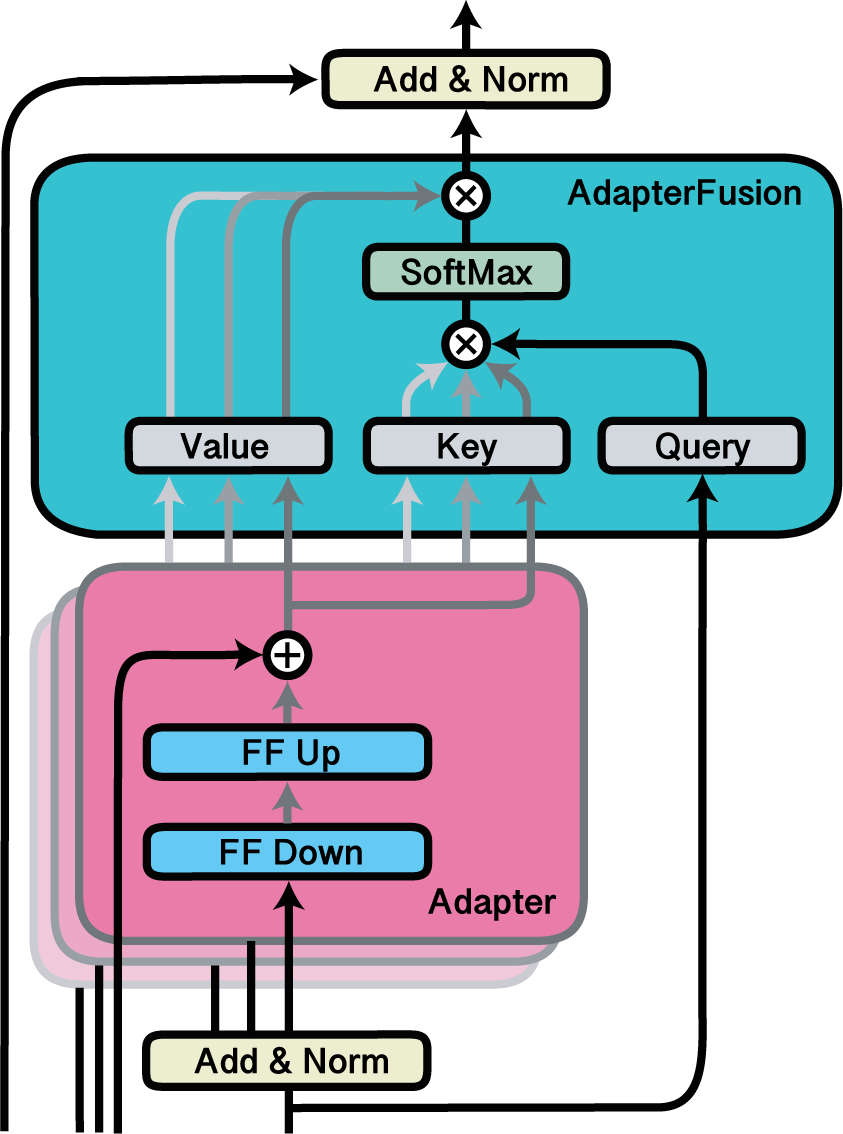
使用AdapterFusion融合适配器。
Fuse模块可用于激活适配器的融合层。AdapterFusion是一种非破坏性的方法,用于在新下游任务中结合多个预训练适配器的知识,由Pfeiffer等人于2021年提出。在以下示例中,我们激活了适配器d、e和f,以及融合这三者输出的融合层。该融合层是通过model.add_adapter_fusion()预先添加的,在此我们指定了需要融合的适配器名称。
import adapters.composition as ac
// ...
model.add_adapter("d")
model.add_adapter("e")
model.add_adapter("f")
model.add_adapter_fusion(["d", "e", "f"])
model.active_adapters = ac.Fuse("d", "e", "f")
重要
只有当模型中添加了一个结合Fuse块中列出的所有适配器的适配器融合层时,使用Fuse块融合适配器才能成功完成。
这可以通过使用add_adapter_fusion()或load_adapter_fusion()来实现。
要了解如何训练AdapterFusion层,请查看adapters代码库中的这个Colab笔记本。
要在一行代码中保存并上传包含适配器和融合层的完整组合设置,请查阅保存和加载适配器组合的文档。
获取AdapterFusion注意力机制
最后,可以获取模型前向传播过程中每个融合层计算得到的注意力分数。这些分数可用于分析融合后的适配器模块,并作为可视化基础,类似于AdapterFusion论文中的展示方式。您可以通过在模型前向调用中传入output_adapter_fusion_attentions=True来收集融合注意力分数。每层的分数随后会保存在输出的adapter_fusion_attentions属性中:
outputs = model(**inputs, output_adapter_fusion_attentions=True)
attention_scores = outputs.adapter_fusion_attentions
请注意,此参数仅适用于基础模型类和AdapterModel类。
在示例中,attention_scores包含以下形式的字典:
{
'<fusion_name>': {
<layer_id>: {
'<module_location>': np.array([...]),
...
},
...
},
...
}
Split
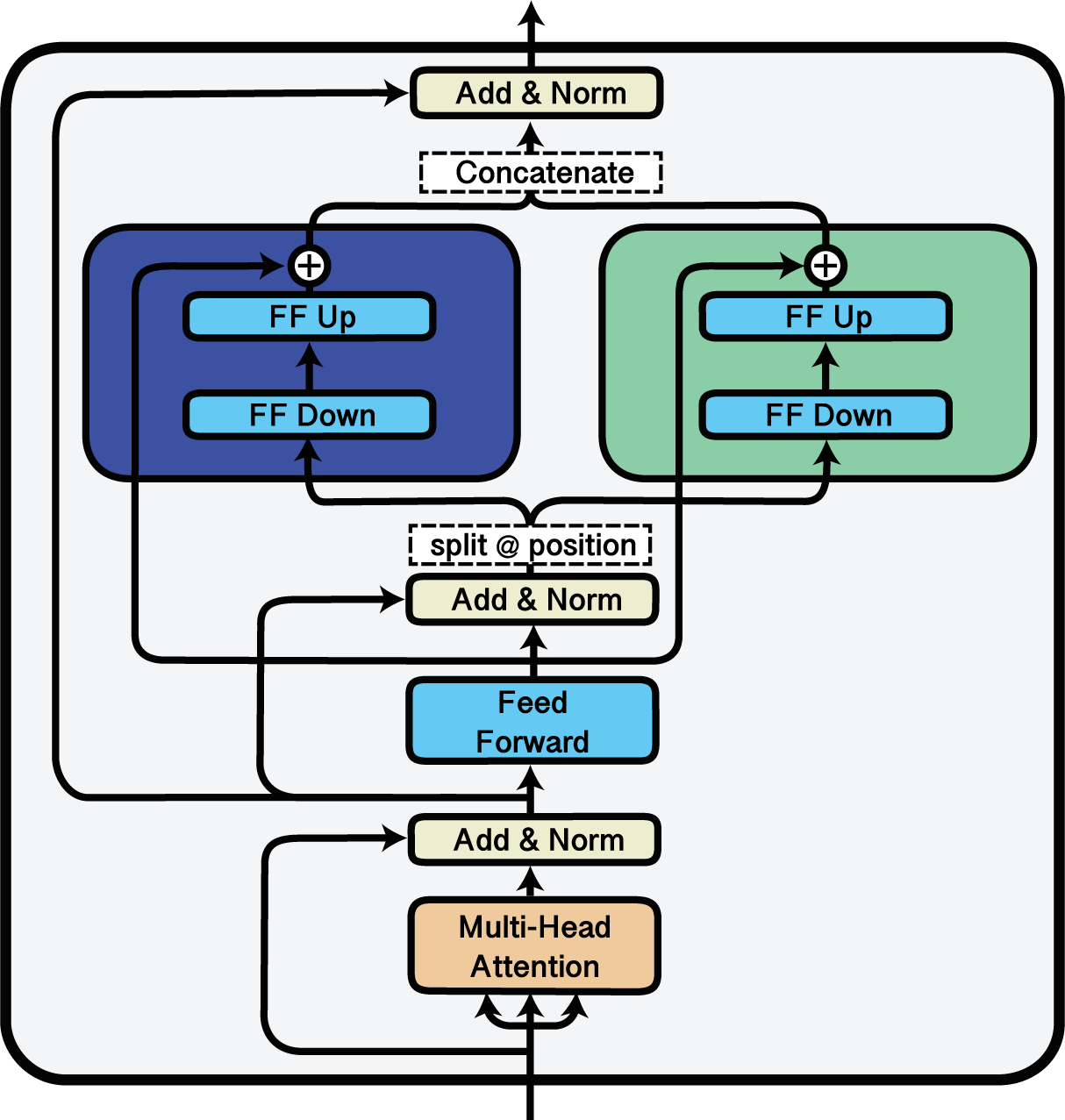
使用'Split'块在两个适配器之间分割输入。
Split 模块可用于在多个适配器之间分割输入序列。
这是通过指定分割索引来实现的,序列将在这些索引处被划分。
在以下示例中,我们将每个输入序列在适配器 g 和 h 之间进行分割。
对于每个序列,从第0到第63个标记将通过 g 转发,而接下来的64个标记将通过 h 转发:
import adapters.composition as ac
// ...
model.add_adapter("g")
model.add_adapter("h")
model.active_adapters = ac.Split("g", "h", splits=[64, 64])
BatchSplit
BatchSplit模块是一种替代方案,用于在多个适配器之间分配输入。它不会分割输入序列,而是将批次拆分为更小的批次。因此,输入序列保持不变。
在以下示例中,我们将批次在适配器i、k和l之间进行分割。batch_sizes参数指定了每个适配器的批次大小。适配器i获得两个序列,k获得1个序列,l获得两个序列。如果所有适配器应获得相同的批次大小,可以通过传递一个批次大小来指定,例如batch_sizes = 2。指定的批次总和必须与输入的批次大小匹配。
import adapters.composition as ac
// ...
model.add_adapter("i")
model.add_adapter("k")
model.add_adapter("l")
model.active_adapters = ac.BatchSplit("i", "k", "l", batch_sizes=[2, 1, 2])
MultiTask
MultiTask模块通过基于提供给forward方法的task_ids实现动态批次分割,扩展了BatchSplit功能。
在下面的示例中,批次会根据分配给每个序列的task_ids动态划分给适配器i、k和l。这种方法支持灵活的多任务学习,无需为每个适配器固定批次大小。
重要
MultiTask 只能与继承自 MultiTaskConfig 的配置一起使用。
在训练多任务适配器时,task_ids必须是一个指示适配器位置的整数张量。
在推理过程中,task_ids可以是任务名称的列表。
from adapters import MTLLoRAConfig
import adapters.composition as ac
// ...
# config must inherit from MultiTaskConfig
config = MTLLoRAConfig()
model.add_adapter("i", config)
model.add_adapter("k", config)
model.add_adapter("l", config)
model.share_parameters(
adapter_names=["i", "k", "l"],
)
model.active_adapters = ac.MultiTask("i", "k", "l")
# input batch size = 3
model.forward(**inputs, task_ids=torch.tensor([2, 1, 0])) # 2 → "l", 1 → "k", 0 → "i"
# Equivalent inference call
model.forward(**inputs, task_ids=["l", "k", "i"])
Parallel
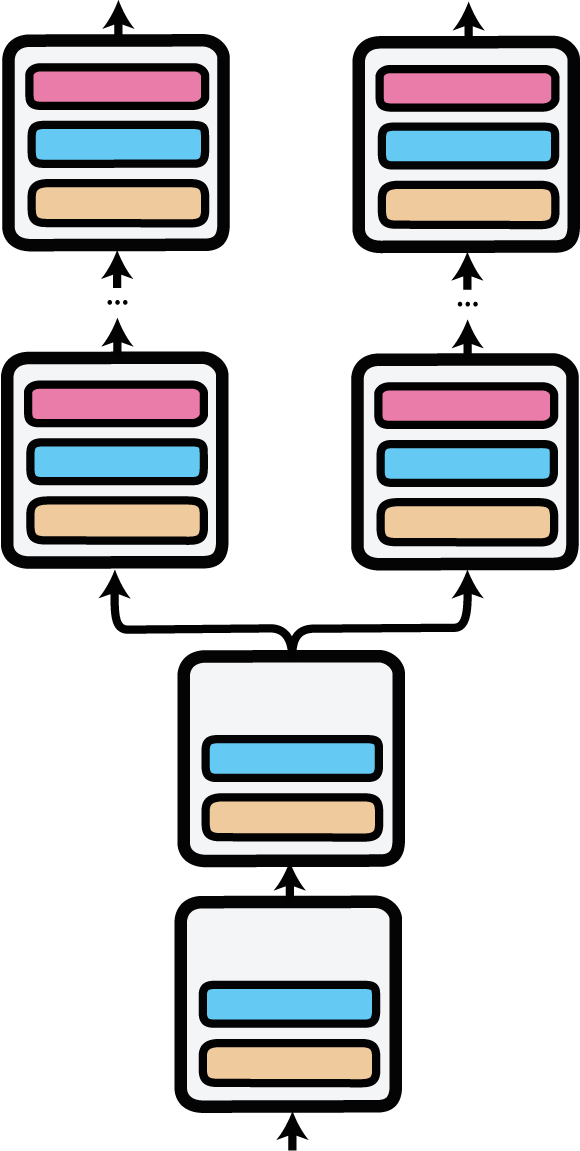
并行适配器的前向传递,由'Parallel'模块实现。输入在第一层通过并行适配器进行复制。
Parallel模块可用于在不同适配器上启用并行多任务训练和推理,每个适配器都有自己的预测头。
并行适配器推理首次应用于AdapterDrop: On the Efficiency of Adapters in Transformers (Rücklé et al., 2020)。
在以下示例中,我们从Hub加载了两个用于语义文本相似度(STS)的适配器,一个在STS基准测试上训练,另一个在MRPC数据集上训练。我们激活了一个并行设置,其中输入会同时通过两个适配器及其各自的预测头进行处理。
import adapters.composition as ac
model = AutoAdapterModel.from_pretrained("distilbert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
adapter1 = model.load_adapter("sts/sts-b@ukp")
adapter2 = model.load_adapter("sts/mrpc@ukp")
model.active_adapters = ac.Parallel(adapter1, adapter2)
input_ids = tokenizer("Adapters are great!", "Adapters are awesome!", return_tensors="pt")
output1, output2 = model(**input_ids)
print("STS-B adapter output:", output1[0].item())
print("MRPC adapter output:", bool(torch.argmax(output2[0]).item()))
输出平均化
近期关于适配器的研究探索了集成模型以提升泛化能力的方法。这包括对适配器输出表示进行平均(Wang et al., 2021)以及对适配器参数进行平均(Wang et al., 2022, Chronopoulou et al., 2023)。Adapters为这两种推理时平均方法提供了内置支持。下文描述了输出平均组合模块,而适配器参数合并方法则在合并适配器文档页面中说明。
输出平均允许通过加权平均在模型前向传播过程中动态聚合多个适配器的输出表示。这是通过Average组合块实现的,其工作原理与其他组合块类似。
在下面的示例中,三个适配器分别以0.1(对应m)、0.6(对应n)和0.3(对应o)的权重进行平均。
import adapters.composition as ac
// ...
model.add_adapter("m")
model.add_adapter("n")
model.add_adapter("o")
model.active_adapters = ac.Average("m", "n", "o", weights=[0.1, 0.6, 0.3])
嵌套组合块
当然,也可以在一个适配器设置中组合不同的组合块。例如,我们可以在适配器的Stack中嵌套一个Split块:
import adapters.composition as ac
model.active_adapters = ac.Stack("a", ac.Split("b", "c", splits=60))
然而,适配器组合块的组合深度并非可以无限延伸。目前所有支持的可能性已在下方表格中可视化展示。
| 区块 | 支持的嵌套 |
|---|---|
Stack |
[str, Fuse, Split, Parallel, BatchSplit, Average] |
Fuse |
[str, Stack] |
Split |
[str, Split, Stack, BatchSplit, Average] |
Parallel |
[str, Stack, BatchSplit, Average] |
BatchSplit |
[str, Stack, Split, BatchSplit, Average] |
MultiTask |
[str, Stack, Split, BatchSplit, Average] |
Average |
[str, Stack, Split, BatchSplit] |
在表格中,str 表示一个适配器,例如上面嵌套示例中的适配器"a"。根据具体模型的不同,某些嵌套组合可能无法实现。