适配器方法
本页面展示了当前集成到adapters库中的所有适配器方法。
此处提供了适配器方法的表格概览。
此外,下一页还展示了在单一设置中组合多种适配器方法的选项。
瓶颈适配器
配置类: BnConfig
瓶颈适配器在Transformer模型的每一层中引入了瓶颈前馈层。通常,这些适配器层包含一个将隐藏状态投影到较低维度\(d_{bottleneck}\)的下投影矩阵\(W_{down}\),一个非线性函数\(f\),一个将数据投影回原始隐藏层维度的上投影矩阵\(W_{up}\),以及一个残差连接\(r\):
根据具体的适配器配置,这些层可以引入到Transformer块内的不同位置。此外,残差连接、层归一化、激活函数和瓶颈尺寸等参数也可以进行配置。
这里需要重点强调的最重要配置超参数是瓶颈维度\(d_{bottleneck}\)。在适配器中,这个瓶颈维度是通过配置中的reduction_factor属性间接指定的。这个reduction_factor定义了模型层隐藏维度与瓶颈维度之间的比率,即:
下图展示了与适配器结构相关的更多配置选项的可视化。更多详情,请参阅BnConfig的文档](adapters.BnConfig)。
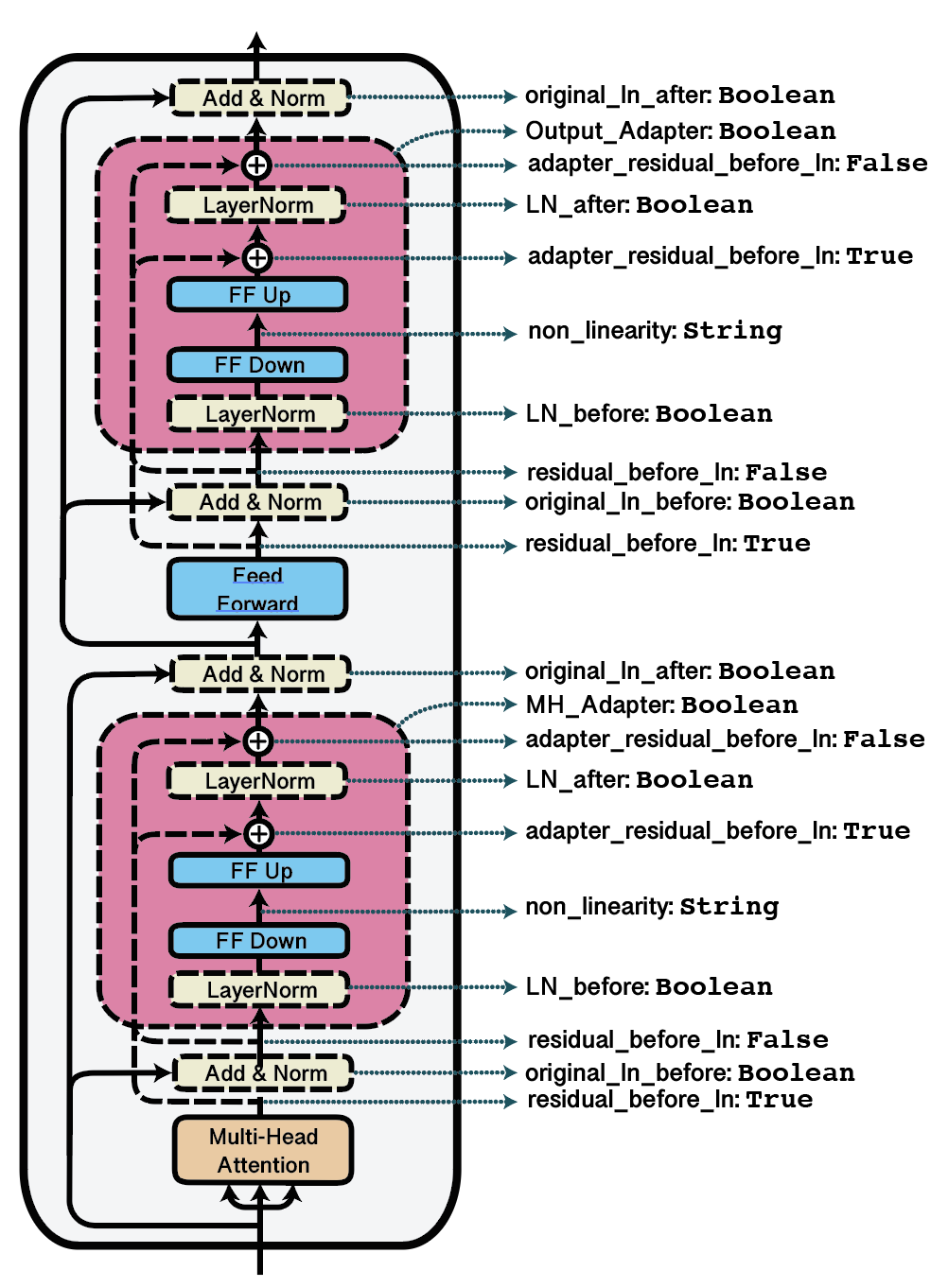
可视化可能的适配器配置及其对应的字典键。
adapters 提供了一些文献中提出的预定义瓶颈适配器架构配置:
DoubleSeqBnConfig,如Houlsby等人(2019)所提出的,在每个Transformer层的多头注意力机制和前馈网络块之后都放置适配器层。SeqBnConfig,如Pfeiffer等人(2020)所提出的,仅在每个Transformer层的前馈块后放置一个适配器层。ParBnConfig,如He等人(2021)所提出的,将适配器层与原始Transformer层并行放置。AdapterPlusConfig,由Steitz和Roth(2024)提出,将适配器层放置在多头注意力之后,并具有通道级缩放和Houlsby权重初始化 示例:
from adapters import BnConfig
config = BnConfig(mh_adapter=True, output_adapter=True, reduction_factor=16, non_linearity="relu")
model.add_adapter("bottleneck_adapter", config=config)
论文:
NLP中的参数高效迁移学习 (Houlsby et al., 2019)
Simple, Scalable Adaptation for Neural Machine Translation (Bapna and Firat, 2019)
AdapterFusion: 非破坏性任务组合的迁移学习 (Pfeiffer等人, 2021)
Adapters Strike Back (Steitz 和 Roth., 2024)
AdapterHub: 一个用于适配Transformer的框架 (Pfeiffer等人, 2020)
注意
瓶颈适配器中的两个参数original_ln_before和original_ln_after同时控制残差输入的添加与预训练层归一化的应用。如果原始模型在前向函数的特定位置(例如FFN层之后)未应用层归一化函数,那么在该相同位置设置的适配器瓶颈参数将仅控制残差输入的应用。
语言适配器 - 可逆适配器
配置类: SeqBnInvConfig, DoubleSeqBnInvConfig
MAD-X设置(Pfeiffer et al., 2020)提出了语言适配器来学习语言特定的转换。 在语言建模任务上训练后,语言适配器可以堆叠在任务适配器之前,用于下游任务的训练。 为了实现零样本跨语言迁移,只需将一个语言适配器替换为另一个即可。
在架构方面,语言适配器与常规瓶颈适配器大体相似,不同之处在于LM嵌入层之后多了一个可逆适配器层。嵌入输出在进入第一个Transformer层之前会正向通过这个可逆适配器,在离开最后一个Transformer层之后则会逆向通过。可逆适配器的架构细节详见Pfeiffer等人(2020),可通过BnConfig类的inv_adapter属性进行配置。
示例:
from adapters import SeqBnInvConfig
config = SeqBnInvConfig()
model.add_adapter("lang_adapter", config=config)
论文:
MAD-X: 基于适配器的多任务跨语言迁移框架 (Pfeiffer等人,2020)
注意
AdapterHub的V1.x版本通过AdapterType枚举区分了任务适配器(不含可逆适配器)和语言适配器(含可逆适配器)。这个区分在V2.x版本中被取消了。
前缀调优
配置类: PrefixTuningConfig
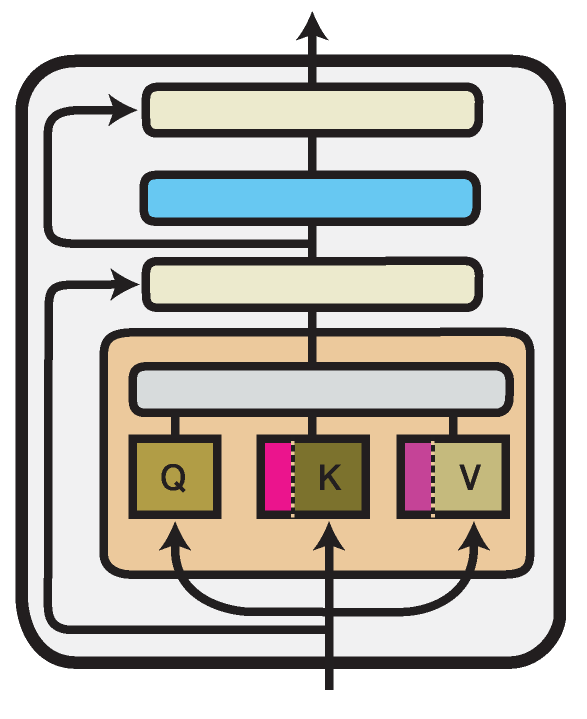
展示Transformer单层中Prefix Tuning方法的示意图。经过训练的组件以品红色调标注。
前缀调优(Li and Liang, 2021)在每个Transformer层的多头注意力模块中引入了新参数。
具体来说,该方法将可训练的前缀向量\(P^K\)和\(P^V\)添加到注意力头输入的键和值前,每个前缀向量的长度\(l\)可配置(prefix_length属性):
根据原作者的设计,\(P^K\)和\(P^V\)中的前缀向量不是直接优化的,而是通过一个瓶颈MLP进行重新参数化。
这一行为由配置中的flat属性控制。
使用PrefixTuningConfig(flat=True)将创建无需重新参数化即可优化的前缀调优向量。
示例:
from adapters import PrefixTuningConfig
config = PrefixTuningConfig(flat=False, prefix_length=30)
model.add_adapter("prefix_tuning", config=config)
由于在使用瓶颈多层感知器进行重新参数化对于在已训练的前缀调优模块上执行推理并非必要,adapters包含了一个功能,可以将重新参数化的前缀调优"弹出"为一个扁平化的版本:
model.eject_prefix_tuning("prefix_tuning")
这将仅保留必要的参数,并减小训练后的Prefix Tuning模型大小。
论文:
Prefix-Tuning: 面向生成的连续提示优化 (Li and Liang, 2021)
Compacter
配置类: CompacterConfig, CompacterPlusPlusConfig
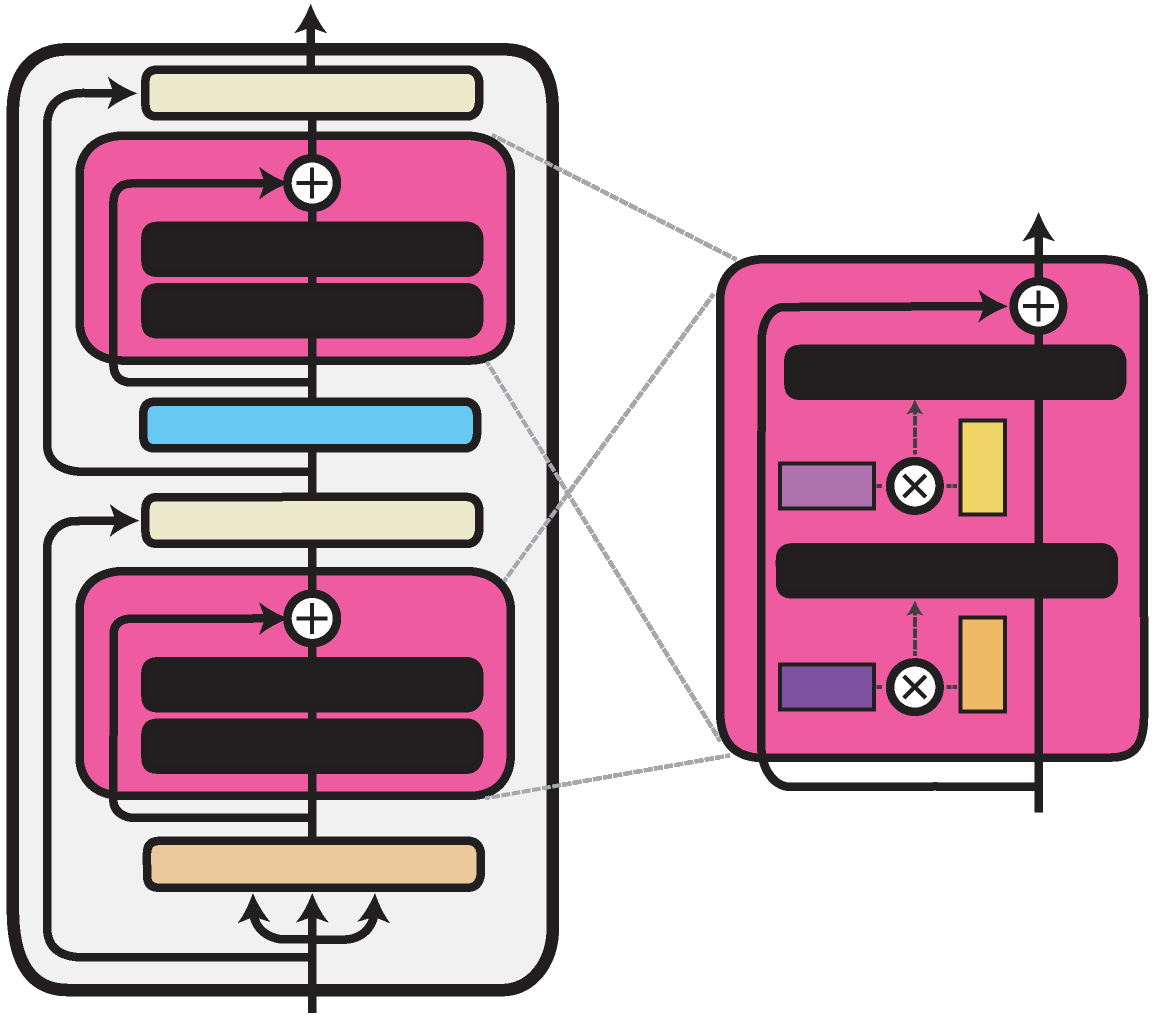
展示单个Transformer层内的Compacter方法。经过训练的组件以深浅不一的品红色标出。
由Mahabadi等人, 2021提出的Compacter架构与瓶颈适配器架构类似。它仅将线性向下和向上投影替换为PHM层。与线性层不同,PHM层通过两个较小的矩阵构建其权重矩阵,从而减少了参数数量。这些矩阵可以被分解并在所有适配器层之间共享。您可以通过在配置中指定use_phm=True,将前面章节描述的任何瓶颈适配器的向下和向上投影层替换为PHM层。
PHM层具有以下额外属性:phm_dim, shared_phm_rule, factorized_phm_rule, learn_phm,
factorized_phm_W, shared_W_phm, phm_c_init, phm_init_range, hypercomplex_nonlinearity
如需了解更多信息,请查看BnConfig类。
要为您的模型添加Compacter,可以使用预定义的配置:
from adapters import CompacterConfig
config = CompacterConfig()
model.add_adapter("dummy", config=config)
论文:
COMPACTER: 高效低秩超复数适配器层 (Mahabadi, Henderson 和 Ruder, 2021)
LoRA
配置类: LoRAConfig

展示单个Transformer层内的LoRA方法示意图。经过训练的组件以深浅不一的洋红色标注。
低秩适配(LoRA)是由Hu等人(2021年)提出的一种高效微调技术。LoRA将可训练的低秩分解矩阵注入预训练模型的各层中。对于任何表示为\(h = W_0 x\)形式的矩阵乘法模型层,它执行重新参数化,使得:
这里,\(A \in \mathbb{R}^{r\times k}\) 和 \(B \in \mathbb{R}^{d\times r}\) 是分解矩阵,而\(r\)作为分解的低维秩是最重要的超参数。
虽然原则上这种重新参数化可以应用于模型中的任何权重矩阵,但原始论文仅使用LoRA对Transformer自注意力子层的注意力权重进行了适配。
adapters 还允许将LoRA注入到Transformer块的中间和输出组件中的密集前馈层中。
您可以使用LoRAConfig类中的属性来配置应注入LoRA权重的位置。
示例:
from adapters import LoRAConfig
config = LoRAConfig(r=8, alpha=16)
model.add_adapter("lora_adapter", config=config)
在LoRA的设计中,Hu等人(2021年)特别注重将推理延迟开销与完全微调相比保持在最低水平。
为实现这一目标,LoRA的重新参数化可以与模型的原始预训练权重合并用于推理。
因此,在每次前向传播中直接使用适配后的权重,而无需通过额外模块传递激活。
在adapters中,这可以通过内置的merge_adapter()方法实现:
model.merge_adapter("lora_adapter")
要继续训练这个LoRA适配器或完全停用它,首先需要再次重置合并的权重:
model.reset_adapter()
论文:
LoRA: 大型语言模型的低秩适配 (Hu 等人, 2021)
(IA)^3
配置类: IA3Config
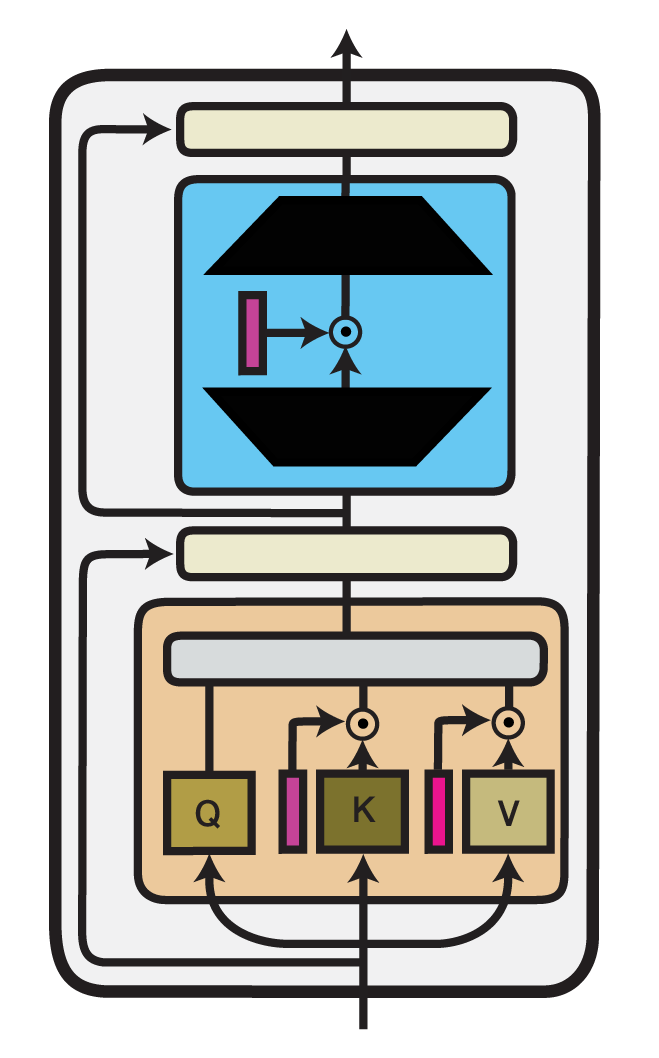
展示单个Transformer层中的(IA)^3方法。经过训练的组件以品红色调显示。
通过抑制和放大内部激活的融合适配器((IA)^3)是由Liu等人(2022)在T-Few微调方法中提出的一种高效微调方法。 (IA)^3将可训练向量\(l_W\)引入Transformer模型的不同组件中,这些向量对模型内部激活进行逐元素重新缩放。 对于任何表示为矩阵乘法形式\(h = W x\)的模型层,它都会与\(l_W\)进行逐元素相乘,因此:
这里,\(\odot\)表示逐元素乘法,其中\(l_W\)的条目被广播到\(W\)的形状。
示例:
from adapters import IA3Config
config = IA3Config()
model.add_adapter("ia3_adapter", config=config)
(IA)^3的实现以及IA3Config类源自LoRA的实现,但进行了几项主要修改。
首先,(IA)^3采用权重乘法组合而非LoRA中的加法组合。
其次,新增权重不再进一步分解为低秩矩阵。
这些修改通过将composition_mode配置属性设置为composition_mode="scale"来控制。
此外,由于新增权重本身已是秩1矩阵,因此设置r=1。
除此之外,这两种方法共享相同的配置属性,允许您指定在哪些Transformer组件中注入重新缩放向量。
根据原始实现,IA3Config将重新缩放向量添加到自注意力权重(selfattn_lora=True)和最终前馈层(output_lora=True)中。
此外,您可以通过利用attn_matrices属性来修改注意力机制中要重新缩放的矩阵。
默认情况下,(IA)^3将权重注入键('k')和值('v')矩阵,但不注入查询('q')矩阵。
最后,与LoRA类似,(IA)^3也允许将注入的参数与Transformer模型的原始权重矩阵合并。 例如:
# Merge (IA)^3 adapter
model.merge_adapter("ia3_adapter")
# Reset merged weights
model.reset_adapter()
论文:
Vera
Vera是由Kopiczko等人(2024)提出的一种基于LoRA的微调方法。在Vera中,我们添加了在所有层之间共享的冻结矩阵A和B。与LoRA相比,它减少了可训练参数的数量,但保持了相同的性能。此外,还引入了可训练的缩放向量\(b\)和\(d\),并与冻结矩阵相乘得到方程:
其中 \Lambda_{b} 和 \Lambda_{d} 在训练期间会接收更新。
示例:
from adapters import VeraConfig
config = VeraConfig()
model.add_adapter("vera_config", config=config)
通过VeraConfig,您可以使用参数init_weights来指定缩放向量的初始化方式以及冻结权重B和A的Vera初始化。
论文:
VeRA: 基于向量的随机矩阵适配 (Kopiczko等人,2024)
提示调优
提示调优(Prompt Tuning)是由Lester等人(2021)提出的一种高效微调技术。该方法通过添加可调令牌(称为软提示)并将其预置到输入文本来实现。
首先,输入序列\({x_1, x_2, \dots, x_n }\)会被嵌入处理,生成矩阵\(X_e \in \mathbb{R}^{n \times e}\),其中\(e\)表示嵌入空间的维度。长度为\(p\)的软提示则表示为\(P_e \in \mathbb{R}^{p \times e}\)。
将\(P_e\)和\(X_e\)进行拼接后,就形成了后续编码器或解码器的输入:
PromptTuningConfig 具有以下属性:
prompt_length: 用于设置软提示的长度 \(p\)prompt_init: 用于设置权重初始化方法,可选"random_uniform"或"from_string",通过从模型词汇表中抽取嵌入来初始化每个提示词标记。prompt_init_text作为初始化文本,当prompt_init="from_string"时使用
combine: 用于定义前缀是应该添加到嵌入输入序列之前,还是添加到BOS标记之后
要为您的模型添加提示调优(Prompt Tuning),您可以使用预定义的配置:
from adapters import PromptTuningConfig
config = PromptTuningConfig(prompt_length=10)
model.add_adapter("dummy", config=config)
论文:
参数高效提示调优的规模化力量 (Lester等人,2021)
ReFT
配置类: ReftConfig
表征微调(ReFT),最初由Wu等人(2024)提出,利用所谓的干预机制来调整语言模型的预训练表征。在ReFT框架下,这些干预机制可以直观地理解为置于每个Transformer层后的适配器模块。其通用形式中,干预函数\(\Phi\)可定义如下:
这里,\(R \in \mathbb{R}^{r \times d}\) 和 \(W \in \mathbb{R}^{r \times d}\) 是秩为 \(r\) 的低秩矩阵。 \(h\) 是单个序列位置的层输出隐藏状态,即可以在每个位置独立应用干预。
基于这种通用形式,ReFT论文提出了多种由适配器支持的ReFT方法实例:
LoReFT 强制使\(R\)中的行保持正交性。可通过
LoReftConfig定义,或如以下示例所示通过orthogonality属性定义:
config = ReftConfig(
layers="all", prefix_positions=3, suffix_positions=0, r=1, orthogonality=True
) # equivalent to LoreftConfig()
NoReFT 不强制要求 \(R\) 的正交性。通过
NoReftConfig或等效方式定义:
config = ReftConfig(
layers="all", prefix_positions=3, suffix_positions=0, r=1, orthogonality=False
) # equivalent to NoreftConfig()
DiReFT 不强制要求\(R\)的正交性,并且在干预中移除了\(R h\)的减法运算,可通过
DiReftConfig或等效方式定义:
config = ReftConfig(
layers="all", prefix_positions=3, suffix_positions=0, r=1, orthogonality=False, subtract_projection=False
) # equivalent to DireftConfig()
此外,Adapters支持在ReftConfig中配置ReFT论文中调整的多个超参数,包括:
prefix_positions: 前缀位置的数量suffix_positions: 后缀位置的数量layers: 需要干预的层。可以是"all"或一个层ID列表tied_weights: 是否在前缀和后缀之间绑定参数
论文:
ReFT: 语言模型的表示微调 (Wu et al., 2024)