主页

![]()
![]()
![]()
![]()
![]()
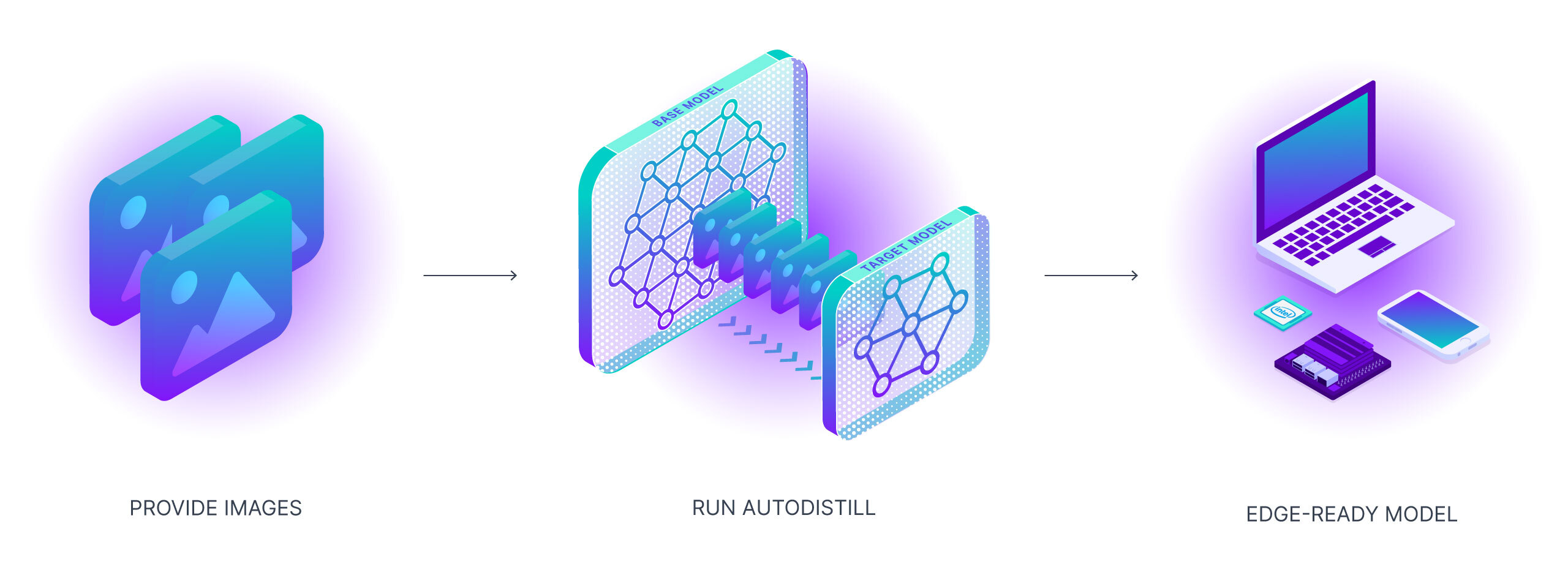
Autodistill使用较大、较慢的基础模型来训练较小、较快的监督模型。使用autodistill,您可以从未标记的图像直接推断在边缘运行的自定义模型,中间无需人工干预。
您可以在自己的硬件上使用Autodistill,或者使用Roboflow托管的Autodistill版本在云中对图像进行标注。
以下是目标模型在使用自动标注的数据集训练后,检测牛奶瓶和瓶盖的示例预测(参见 Autodistill YouTube 视频 以获取完整演示):

🚀 功能¶
- 🔌 可插拔接口,将模型连接在一起
- 🤖 自动标记数据集
- 🐰 训练快速的监督模型
- 🔒 拥有你的模型
- 🚀 将精简模型部署到云端或边缘
📚 基本概念¶
要使用 autodistill,您将未标记的数据输入到一个基础模型中,该模型使用本体来标记一个用于训练目标模型的数据集,目标模型输出一个经过微调的蒸馏模型,以执行特定任务。

Autodistill 定义了几个基本原语:
- 任务 - 任务定义了一个目标模型将预测的内容。每个组件(基础模型、本体论和目标模型)在
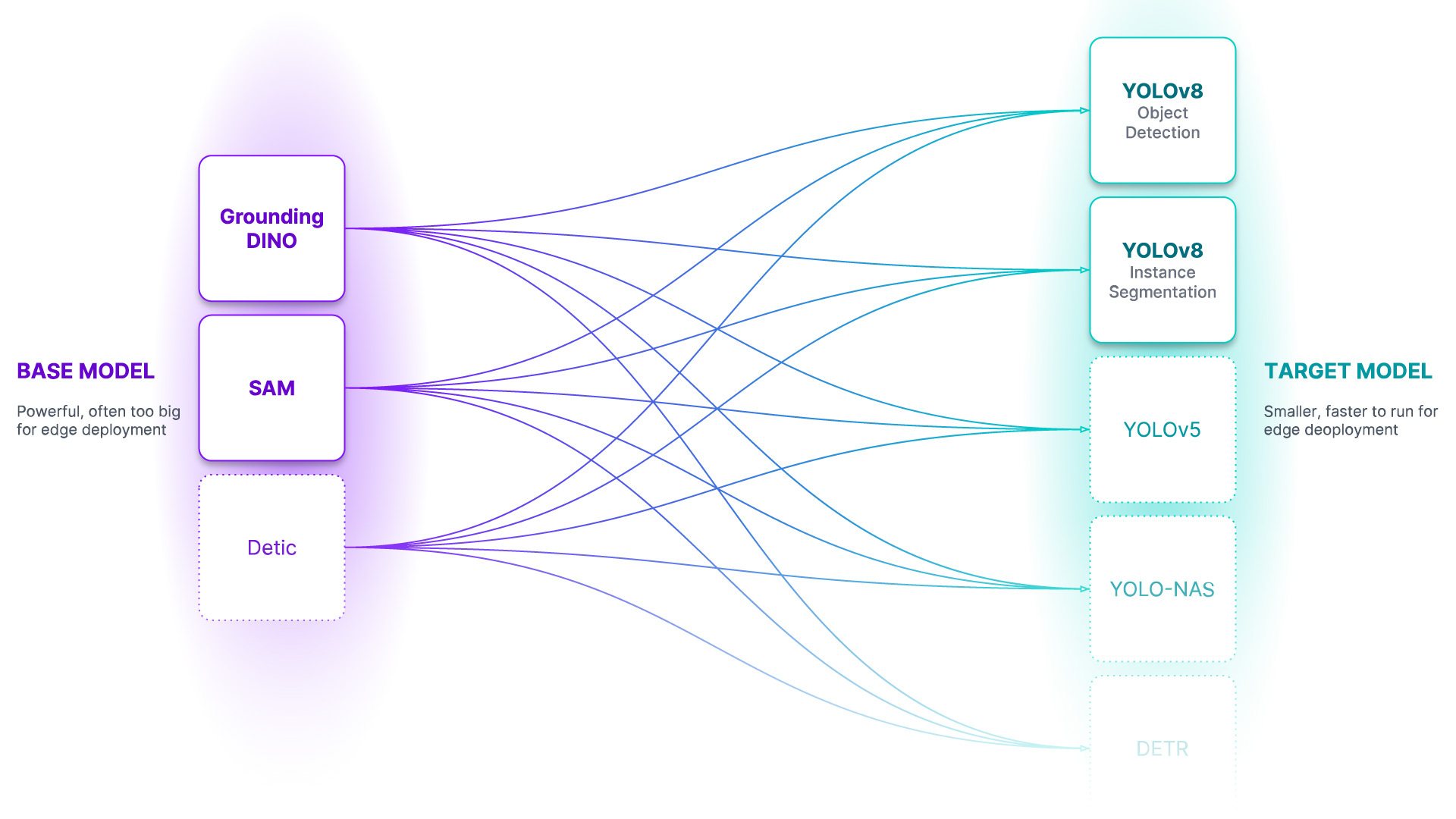
autodistill管道中的任务必须匹配才能相互兼容。目前通过detection任务支持目标检测和实例分割。classification支持将很快添加。 - 基础模型 - 基础模型是一个大型基础模型,知识面广泛。基础模型通常是多模态的,能够执行许多任务。它们大、慢且昂贵。基础模型的例子包括GroundedSAM和即将推出的GPT-4多模态变体。我们使用基础模型(以及未标记的输入数据和本体)来创建数据集。
- 本体 - 本体定义了如何提示您的基础模型,您的数据集将描述什么,以及您的目标模型将预测什么。一个简单的本体是
CaptionOntology,它通过文本标题提示基础模型并将其映射到类名。其他本体可能会例如使用 CLIP 向量或示例图像来代替文本标题。 - 数据集 - 数据集是一组自动标记的数据,可用于训练目标模型。它是基础模型生成的输出。
- 目标模型 - 目标模型是一种监督模型,它消耗一个数据集并输出一个准备好部署的精简模型。目标模型通常较小、快速,并经过微调以非常好地执行特定任务(但它们在数据集中描述的信息之外的泛化能力较差)。目标模型的例子包括 YOLOv8 和 DETR。
- 蒸馏模型 - 蒸馏模型是
autodistill过程的最终输出;它是一组针对您的任务进行微调的权重,可以部署以获取预测。
💡 理论与限制¶
人工标注是计算机视觉广泛应用的最大障碍之一。制作一个适合训练生产模型的数据集可能需要数千个小时。训练监督模型的蒸馏过程并不新鲜,实际上,传统的人类标注只是一种从极具能力的基础模型(人脑 🧠)中进行蒸馏的另一种形式。
基础模型知道很多事情,但在生产中我们需要了解一些事情的模型。
随着基础模型越来越优秀,它们将越来越能够增强或替代人类在标注过程中的作用。我们需要用于引导、利用和比较这些模型的工具。此外,这些基础模型庞大、昂贵,并且通常受到私人API的限制。对于许多生产用例,我们需要能够以低成本和实时在边缘运行的模型。
Autodistill 的基础模型已经能够为许多常见用例创建数据集(通过创造性提示和少量示例,我们可以将其用途扩展到更多),但它们还不够完美。还有很多工作要做;这只是开始,我们希望您能帮助测试和扩展系统的功能!
💿 安装¶
Autodistill 是模块化的。您需要安装 autodistill 包(定义上述概念的接口)以及 Base Model and Target Model plugins(实现特定模型)。
通过将这些单独打包为插件,可以最大限度地减少依赖关系和许可不兼容性,任何人都可以实现和维护新的模型。
示例:
pip install autodistill autodistill-grounded-sam autodistill-yolov8
Install from source
You can also clone the project from GitHub for local development:git clone https://github.com/roboflow/autodistill
cd autodistill
pip install -e .
附加的基础和目标模型如下所列。
🎬 视频指南¶

在这个视频中,我们将向您展示如何使用一个新库来训练YOLOv8模型,检测在输送带上移动的瓶子。没错—不需要任何注释时间!我们深入探讨Autodistill的功能,涵盖从设置您的Python环境和准备图像到激动人心的自动图像注释等主题。
💡 社区资源¶
NoneNone- 将大型视觉模型提炼为更小、更高效的模型,使用Autodistill: 关于如何使用Autodistill的公告帖子和书面指南
- 比较AI标记的数据与人工标记的数据: 对在各个任务和领域中使用Autodistill的Grounding DINO进行的定性评估。
- 如何评估 Autodistill 提示与 CVevals: 评估 Autodistill 提示。
- Autodistill: 在20分钟内标注和训练一个计算机视觉模型: 在20分钟内构建一个模型来检测飞机。
- 将AI标记的数据与人工标记的数据进行比较: 探索与Autoditsill一起使用的基本模型的优缺点。
- 无标签训练图像分类模型: 使用 Grounded SAM 自动标记图像,以训练 Ultralytics YOLOv8 分类模型。
- 使用无标签训练分割模型: 使用 CLIP 自动为训练 Ultralytics YOLOv8 分割模型标记图像。
- 提交一个PR来添加你自己的资源!
🗺️ 路线图¶
除了添加新模型,我们还计划探索几个领域与 autodistill 包括:
- 💡 本体创建与提示工程
- 👩💻 人工干预支持
- 🤔 模型评估
- 🔄 主动学习
- 💬 语言任务
🏆 贡献¶
我们非常感谢您的反馈!请查看我们的 贡献指南 开始。感谢 🙏 所有贡献者!
👩⚖️ 许可证¶
这个 autodistill 包是根据 Apache 2.0 许可证发布的。每个基础或目标模型插件可能会使用其对应于其基础模型的许可证。有关更多信息,请参阅每个插件仓库中的许可证。
常见问题 ❓¶
是什么导致了PytorchStreamReader failed reading zip archive: failed finding central directory错误?¶
当 PyTorch 无法加载模型的权重时,会导致此错误。进入 ~/.cache/autodistill 目录,并删除与您尝试加载的模型相关的文件夹。然后,再次运行您的代码。模型权重将从头下载。请勿打断安装过程。
💻 探索更多 Roboflow 开源项目¶
| 项目 | 描述 |
|---|---|
| supervision | 用于计算机视觉项目的通用工具,从预测过滤和显示到物体跟踪再到模型评估。 |
| Autodistill (该项目) | 自动标记图像以用于训练计算机视觉模型。 |
| 推断 | 一个易于使用、准备投入生产的计算机视觉推断服务器,支持许多流行模型架构和微调模型的部署。 |
| 笔记本 | 计算机视觉任务的教程,从训练最先进的模型到跟踪对象再到在区域内计数对象。 |
| Collect | 由CLIP驱动的自动化、智能数据收集。 |