最新动态¶
在这里,您可以找到AutoGluon当前和过去版本的发布说明。
v1.1.1
Version 1.1.1
我们很高兴宣布AutoGluon 1.1.1版本的发布。
AutoGluon 1.1.1 包含了对 Tabular、TimeSeries 和 Multimodal 模块的错误修复和日志改进,以及对 PyTorch 2.2 和 2.3 的支持。
加入社区:
获取最新更新:


此版本支持 Python 3.8、3.9、3.10 和 3.11 版本。不支持加载在旧版 AutoGluon 上训练的模型。请使用 AutoGluon 1.1.1 重新训练模型。
此版本包含来自10位贡献者的52次提交!
通用
添加对 PyTorch 2.2 的支持。@prateekdesai04 (#4123)
添加对 PyTorch 2.3 的支持。@suzhoum (#4239, #4256)
将GluonTS升级到0.15.1。@shchur (#4231)
Tabular
注意:尝试加载一个使用先前AutoGluon版本训练的FastAI模型的TabularPredictor时,在调用predict时会引发异常,这是由于model-interals.pkl路径的修复。请确保版本匹配。
修复当
num_gpus>0且启用dynamic_stacking时的死锁问题。@Innixma (#4208)改进决策阈值校准。@Innixma (#4136, #4137)
改进动态堆叠日志记录。@Innixma (#4208, #4262)
修复了LightGBM早停时回归指标(除RMSE和MSE外)计算错误的问题。@Innixma (#4174)
修复了LightGBM早停时自定义多类指标计算错误的问题。@Innixma (#4250)
修复使用NN_TORCH和FASTAI模型时HPO崩溃的问题。@Innixma (#4232)
改进NN_TORCH运行时间估计。@Innixma (#4247)
添加推理吞吐量日志记录。@Innixma (#4200)
由于观察到性能下降,禁用线性模型的sklearnex。@Innixma (#4223)
在Kaggle中提高sklearnex日志的详细程度。@Innixma (#4216)
将缓存的版本文件重命名为version.txt。@Innixma (#4203)
为线性模型添加refit_full支持。@Innixma (#4222)
添加AsTypeFeatureGenerator的详细异常日志记录。@Innixma (#4251, #4252)
时间序列
确保prediction_length存储为整数。@shchur (#4160)
修复表格模型预处理失败的边缘情况。@shchur (#4175)
修复了如果预测器移动到不同目录时,表格模型加载失败的问题。@shchur (#4171)
修复当预测器保存在现有预测器之上时的缓存预测错误。@shchur (#4202)
使用AutoGluon的Chronos模型分支。@shchur (#4198)
修复Chronos推理中的off-by-one错误。@canerturkmen (#4205)
将缓存的版本文件重命名为version.txt。@Innixma (#4203)
在MLForecast的回退模型中使用正确的目标和分位数水平。@shchur (#4230)
Multimodal
修复CLIP图像特征归一化中的错误。@Harry-zzh (#4114)
修复文本增强中的错误。@Harry-zzh (#4115)
修改默认的微调技巧。@Harry-zzh (#4166)
为物体检测添加PyTorch版本警告。@FANGAreNotGnu (#4217)
文档和持续集成
将比赛解决方案添加到
AWESOME.md。@Innixma @shchur (#4122, #4163, #4245)修复PDF分类教程。@zhiqiangdon (#4127)
添加AutoMM论文引用。@zhiqiangdon (#4154)
在所有模块和教程中添加pickle加载警告。@shchur (#4243)
各种文档和测试的小修复和改进。@tonyhoo @shchur @lovvge @Innixma @suzhoum (#4113, #4176, #4225, #4233, #4235, #4249, #4266)
贡献者
完整贡献者列表(按提交次数排序):
@Innixma @shchur @Harry-zzh @suzhoum @zhiqiangdon @lovvge @rey-allan @prateekdesai04 @canerturkmen @FANGAreNotGnu
新贡献者
@lovvge 在 https://github.com/autogluon/autogluon/commit/57a15fcfbbbc94514ff20ed2774cd447d9f4115f 上做出了他们的第一次贡献
@rey-allan 在 #4145 中做出了他们的第一次贡献
v1.1.0
版本 1.1.0
我们很高兴宣布AutoGluon 1.1版本的发布。
AutoGluon 1.1 对 TimeSeries 模块进行了重大改进,通过添加 Chronos(一个用于时间序列预测的预训练模型)以及许多其他增强功能,与 AutoGluon 1.0 相比,胜率提高了 60%。 其他模块也通过新功能得到了增强,例如支持 Conv-LORA 以及提高了 5 - 30 GB 大小的大型表格数据集的性能。 有关 AutoGluon 1.1 功能的完整分解,请参阅下面的功能亮点和详细增强列表。
Join the community:
Get the latest updates:
此版本支持 Python 3.8、3.9、3.10 和 3.11 版本。不支持加载在旧版 AutoGluon 上训练的模型。请使用 AutoGluon 1.1 重新训练模型。
此版本包含来自20位贡献者的121次提交!
完整贡献者列表(按提交次数排序):
@shchur @prateekdesai04 @Innixma @canerturkmen @zhiqiangdon @tonyhoo @AnirudhDagar @Harry-zzh @suzhoum @FANGAreNotGnu @nimasteryang @lostella @dassaswat @afmkt @npepin-hub @mglowacki100 @ddelange @LennartPurucker @taoyang1122 @gradientsky
特别感谢@ddelange在Python 3.11支持和Ray版本升级方面的持续帮助!
聚光灯
AutoGluon 在机器学习竞赛中取得顶尖成绩!
自AutoGluon 1.0发布以来,AutoGluon在Kaggle上得到了广泛的应用。 在过去的90天里,AutoGluon已经在超过130个Kaggle笔记本中被使用,并在超过100个讨论线程中被提及! 最令人兴奋的是,自2024年初以来,AutoGluon已经在多个有数千名参赛者的比赛中被用于获得顶级排名:
放置 |
竞赛 |
作者 |
日期 |
AutoGluon 详情 |
注释 |
|---|---|---|---|---|---|
:3rd_place_medal: 排名 3/2303 (前 0.1%) |
2024年03月31日 |
v1.0, 表格 |
Kaggle 游乐场系列 S4E3 |
||
:2nd_place_medal: 排名 2/93 (前2%) |
2024年03月21日 |
v1.0, 表格 |
|||
:2nd_place_medal: 排名 2/1542 (前 0.1%) |
2024/03/01 |
v1.0, 表格 |
|||
:2nd_place_medal: 排名 2/3746 (前 0.1%) |
2024年02月29日 |
v1.0, 表格 |
Kaggle 游乐场系列 S4E2 |
||
:2nd_place_medal: 排名 2/3777 (前 0.1%) |
2024/01/31 |
v1.0, 表格 |
Kaggle 游乐场系列 S4E1 |
||
排名 4/1718(前 0.2%) |
2024/01/01 |
v1.0, 表格 |
Kaggle 游乐场系列 S3E26 |
我们非常高兴数据科学社区正在利用AutoGluon作为他们的首选方法,快速有效地实现顶级机器学习解决方案! 有关使用AutoGluon的最新竞赛解决方案列表,请参阅我们的AWESOME.md, 如果您在竞赛中使用了AutoGluon,请毫不犹豫地告诉我们!
Chronos,一个用于时间序列预测的预训练模型
AutoGluon-TimeSeries 现在推出了 Chronos,这是一个在大量开源时间序列数据集上预训练的预测模型家族,可以为新的未见数据生成准确的零样本预测。查看 新教程,了解如何通过熟悉的 TimeSeriesPredictor API 使用 Chronos。
通用
重构项目README和项目标语 @Innixma (#3861, #4066)
添加AWESOME.md竞赛结果和其他文档改进。@Innixma (#4023)
Pandas 版本升级。@shchur @Innixma (#4079, #4089)
PyTorch、CUDA、Lightning 版本升级。@prateekdesai04 @canerturkmen @zhiqiangdon (#3982, #3984, #3991, #4006)
Ray 版本升级。@ddelange @tonyhoo (#3774, #3956)
Scikit-learn 版本升级。@prateekdesai04 (#3872, #3881, #3947)
各种依赖项升级。@Innixma @tonyhoo (#4024, #4083)
时间序列
亮点
AutoGluon 1.1 带来了许多新功能和改进,特别是在时间序列模块。这些包括高度需求的功能,如特征重要性、支持分类协变量、可视化预测的能力以及日志记录的增强。新版本还在预测准确性方面取得了显著改进,与之前的 AutoGluon 版本相比,实现了 60% 的胜率和 3% 的平均误差减少。这些改进主要归功于 Chronos 的加入、改进的预处理逻辑以及对缺失值的本地处理。
新功能
添加Chronos预训练预测模型(教程)。@canerturkmen @shchur @lostella (#3978, #4013, #4052, #4055, #4056, #4061, #4092, #4098)
使用
TimeSeriesPredictor.feature_importance()测量特征和协变量对预测准确性的重要性。@canerturkmen (#4033, #4087)原生支持缺失值(无需插补)。@shchur (#3995, #4068, #4091)
添加对分类协变量的支持。@shchur (#3874, #4037)
通过使用
TimeSeriesPredictor.persist()将模型持久化在内存中,提高推理速度。@canerturkmen (#4005)使用
TimeSeriesPredictor.plot()可视化预测。@shchur (#3889)添加
RMSLE评估指标。@canerturkmen (#3938)启用日志记录到文件。@canerturkmen (#3877)
添加选项以在训练后保留闪电日志,使用
keep_lightning_logs超参数。@shchur (#3937)
修复和改进
自动预处理实值协变量 @shchur (#4042, #4069)
添加选项以在仅训练一个模型时跳过模型选择。@shchur (#4002)
确保所有指标处理目标中的缺失值 @shchur (#3966)
修复在CPU机器上加载GPU训练模型时的错误 @shchur (#3979)
修复不一致的随机种子。@canerturkmen @shchur (#3934, #4099)
修复在加载后调用 .info 时崩溃的问题。@afmkt (#3900)
修复当没有模型训练时排行榜崩溃的问题。@shchur (#3849)
添加原型TabRepo模拟工件生成。@shchur (#3829)
修复 refit_full 错误。@shchur (#3820)
文档改进,隐藏已弃用的方法。@shchur (#3764, #4054, #4098)
小修复。@canerturkmen, @shchur, @AnirudhDagar (#4009, #4040, #4041, #4051, #4070, #4094)
AutoMM
亮点
AutoMM 1.1 引入了创新的 Conv-LoRA, 这是一种参数高效微调(PEFT)方法,源自我们在 ICLR 2024 上发表的最新论文, 题为“卷积遇上 LoRA:Segment Anything Model 的参数高效微调”。 Conv-LoRA 旨在微调 Segment Anything Model, 在多种语义分割任务中表现出优于以往 PEFT 方法的性能, 包括自然图像、农业、遥感和医疗保健等领域。查看 我们的 Conv-LoRA 示例。
新功能
添加了Conv-LoRA,一种新的参数高效微调方法。@Harry-zzh @zhiqiangdon (#3933, #3999, #4007, #4022, #4025)
新增了对新列类型的支持:‘image_base64_str’。@Harry-zzh @zhiqiangdon (#3867)
增加了在FT-Transformer中加载预训练权重的支持。@taoyang1122 @zhiqiangdon (#3859)
修复和改进
修复了语义分割中的错误。@Harry-zzh (#3801, #3812)
修复了使用F1指标时的崩溃问题。@suzhoum (#3822)
修复了PEFT方法中的错误。@Harry-zzh (#3840)
高质量和最佳质量预设的物体检测训练速度提高了约30%。@FANGAreNotGnu (#3970)
已弃用的 Grounding-DINO @FANGAreNotGnu (#3974)
修复了闪电升级问题 @zhiqiangdon (#3991)
在知识蒸馏中,使用f1、f1_macro、f1_micro进行二元分类的问题已修复。@nimasteryang (#3837)
由于许可证问题,已从安装中移除MyMuPDF。用户需要自行安装以进行文档分类。@zhiqiangdon (#4093)
Tabular
亮点
AutoGluon-Tabular 1.1 主要专注于错误修复和稳定性改进。特别是,我们通过使用子采样进行决策阈值校准和加权集成拟合到100万行,大大提高了5-30 GB大小的大型数据集的运行时性能,在保持相同质量的同时执行速度更快。我们还将默认的加权集成迭代次数从100次调整为25次,这将使所有加权集成拟合时间加快4倍。我们大幅重构了fit_pseudolabel逻辑,现在应该能够显著获得更强的结果。
修复和改进
修复了在
predictor.fit_weighted_ensemble(refit_full=True)中的返回值。@Innixma (#1956)通过子采样提高大数据集上的性能。@Innixma (#3977)
修复了在内存不足时refit_full崩溃的问题。@Innixma (#3977)
重构并增强
.fit_pseudolabel逻辑。@Innixma (#3930)修复了在LightGBM、CatBoost和XGBoost的HPO过程中内存检查导致的崩溃。@Innixma (#3931)
修复窗口上的动态堆叠问题。@Innixma (#3893)
LightGBM 版本升级。@mglowacki100, @Innixma (#3427)
修复如果Ray未初始化时跳过内存安全的子拟合问题。@LennartPurucker (#3868)
日志记录改进。@AnirudhDagar (#3873)
隐藏已弃用的方法。@Innixma (#3795)
文档改进。@Innixma @AnirudhDagar (#2024, #3975, #3976, #3996)
文档和持续集成
添加自动基准测试报告生成。@prateekdesai04 (#4038, #4039)
修复Windows的表格测试。@tonyhoo (#4036)
修复挂起的表格单元测试。@prateekdesai04 (#4031)
修复CI评估。@suzhoum (#4019)
在CI运行之间添加包版本比较 @prateekdesai04 (#3962, #3968, #3972)
更新 conf.py 以反映当前年份。@dassaswat (#3932)
避免冗余的单元测试运行。@prateekdesai04 (#3942)
修复colab笔记本链接 @prateekdesai04 (#3926)
v1.0.0
Version 1.0.0
Today is finally the day… AutoGluon 1.0 has arrived!! After over four years of development and 2061 commits from 111 contributors, we are excited to share with you the culmination of our efforts to create and democratize the most powerful, easy to use, and feature rich automated machine learning system in the world. AutoGluon 1.0 comes with transformative enhancements to predictive quality resulting from the combination of multiple novel ensembling innovations, spotlighted below. Besides performance enhancements, many other improvements have been made that are detailed in the individual module sections.
注意:不支持加载在旧版本AutoGluon上训练的模型。请使用AutoGluon 1.0重新训练模型。
此版本支持 Python 3.8、3.9、3.10 和 3.11 版本。
此版本包含来自17位贡献者的223次提交!
完整贡献者列表(按提交次数排序):
@shchur, @zhiqiangdon, @Innixma, @prateekdesai04, @FANGAreNotGnu, @yinweisu, @taoyang1122, @LennartPurucker, @Harry-zzh, @AnirudhDagar, @jaheba, @gradientsky, @melopeo, @ddelange, @tonyhoo, @canerturkmen, @suzhoum
Join the community:
Get the latest updates:
聚光灯
表格性能增强
AutoGluon 1.0 features major enhancements to predictive quality, establishing a new state-of-the-art in Tabular modeling. To the best of our knowledge, AutoGluon 1.0 marks the largest leap forward in the state-of-the-art for tabular data since the original AutoGluon paper from March 2020. The enhancements come primarily from two features: Dynamic stacking to mitigate stacked overfitting, and a new learned model hyperparameters portfolio via Zeroshot-HPO, obtained from the newly released TabRepo ensemble simulation library. Together, they lead to a 75% win-rate compared to AutoGluon 0.8 with faster inference speed, lower disk usage, and higher stability.
AutoML 基准测试结果
OpenML released the official 2023 AutoML Benchmark results on November 16th, 2023. Their results show AutoGluon 0.8 as the state-of-the-art in AutoML systems across a wide variety of tasks: “Overall, in terms of model performance, AutoGluon consistently has the highest average rank in our benchmark.” We now showcase that AutoGluon 1.0 achieves far superior results even to AutoGluon 0.8!
Below is a comparison on the OpenML AutoML Benchmark across 1040 tasks. LightGBM, XGBoost, and CatBoost results were obtained via AutoGluon, and other methods are from the official AutoML Benchmark 2023 results. AutoGluon 1.0 has a 95%+ win-rate against traditional tabular models, including a 99% win-rate vs LightGBM and a 100% win-rate vs XGBoost. AutoGluon 1.0 has between an 82% and 94% win-rate against other AutoML systems. For all methods, AutoGluon is able to achieve >10% average loss improvement (Ex: Going from 90% accuracy to 91% accuracy is a 10% loss improvement). AutoGluon 1.0 achieves first place in 63% of tasks, with lightautoml having the second most at 12% (AutoGluon 0.8 previously took first place 48% of the time). AutoGluon 1.0 even achieves a 7.4% average loss improvement over AutoGluon 0.8!
方法 |
AG胜率 |
AG损失改进 |
重新调整的损失 |
排名 |
冠军 |
|---|---|---|---|---|---|
AutoGluon 1.0(最佳,4小时8核) |
- |
- |
0.04 |
1.95 |
63% |
lightautoml (2023, 4小时8核心) |
84% |
12.0% |
0.2 |
4.78 |
12% |
H2OAutoML (2023, 4小时8核心) |
94% |
10.8% |
0.17 |
4.98 |
1% |
FLAML (2023, 4小时8核心) |
86% |
16.7% |
0.23 |
5.29 |
5% |
MLJAR (2023, 4小时8核心) |
82% |
23.0% |
0.33 |
5.53 |
6% |
autosklearn (2023, 4小时8核心) |
91% |
12.5% |
0.22 |
6.07 |
4% |
GAMA (2023, 4小时8核心) |
86% |
15.4% |
0.28 |
6.13 |
5% |
CatBoost (2023, 4小时8核心) |
95% |
18.2% |
0.28 |
6.89 |
3% |
TPOT (2023, 4小时8核心) |
91% |
23.1% |
0.4 |
8.15 |
1% |
LightGBM (2023, 4小时8核) |
99% |
23.6% |
0.4 |
8.95 |
0% |
XGBoost (2023, 4小时8核) |
100% |
24.1% |
0.43 |
9.5 |
0% |
随机森林 (2023, 4h8c) |
97% |
25.1% |
0.53 |
9.78 |
1% |
Not only is AutoGluon more accurate in 1.0, it is also more stable thanks to our new usage of Ray subprocesses during low-memory training, resulting in 0 task failures on the AutoML Benchmark.
AutoGluon 1.0 is capable of achieving the fastest inference throughput of any AutoML system while still obtaining state-of-the-art results.
By specifying the infer_limit fit argument, users can trade off between accuracy and inference speed to meet their needs.
如下图所示,AutoGluon 1.0 在质量和推理吞吐量方面设定了帕累托前沿,与所有其他 AutoML 系统相比实现了帕累托优势。 AutoGluon 1.0 High 实现了比 AutoGluon 0.8 Best 更优越的性能,推理速度快了 8 倍,磁盘使用量减少了 8 倍!
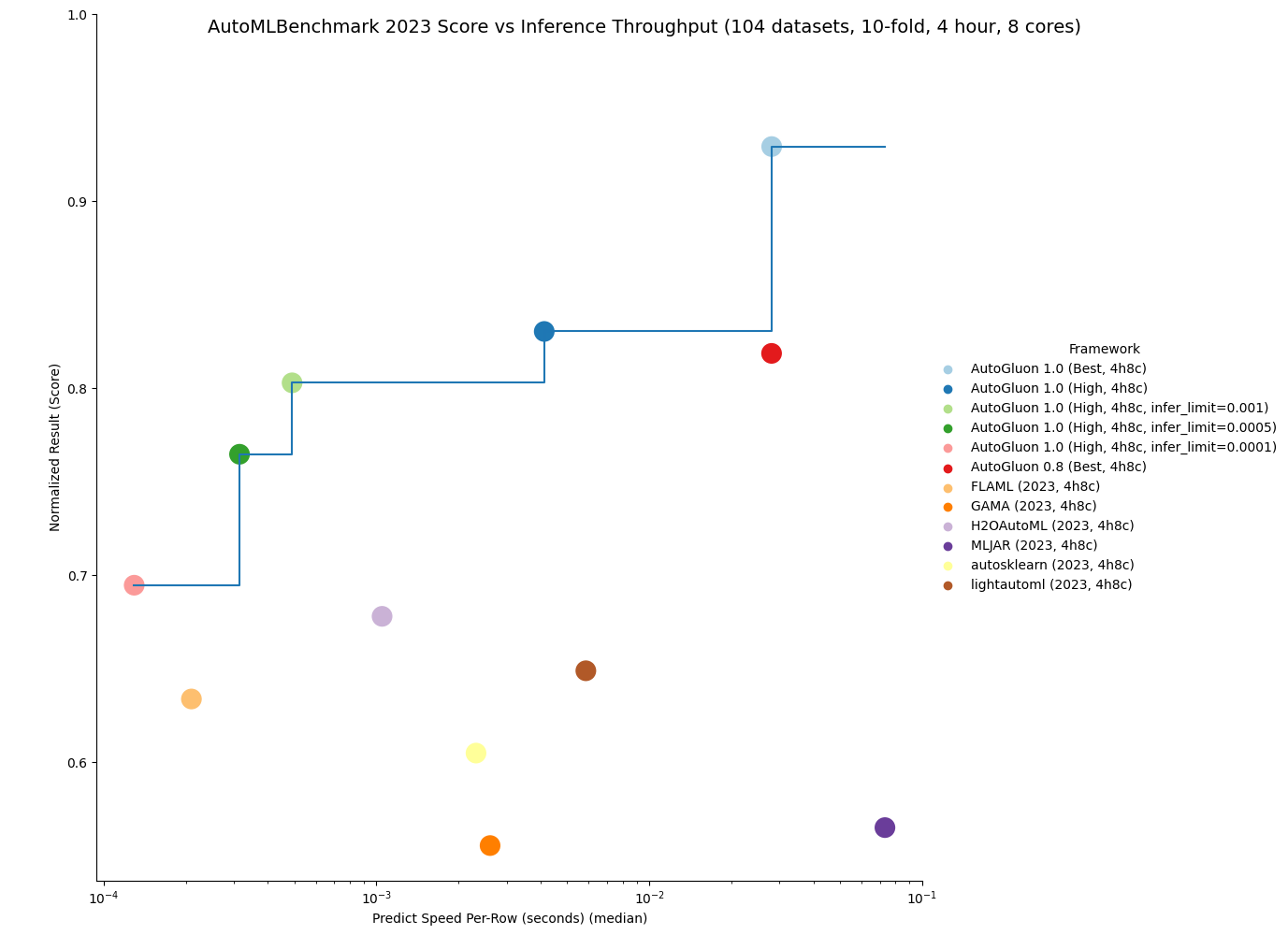
You can get more details on the results here.
我们很高兴看到我们的用户能够利用AutoGluon 1.0的增强性能实现什么。一如既往,我们将在未来的版本中继续改进AutoGluon,以推动AutoML的边界向前发展。
AutoGluon 多模态 (AutoMM) 亮点一览图

AutoMM 独特性
AutoGluon Multimodal (AutoMM) distinguishes itself from other open-source AutoML toolboxes like AutosSklearn, LightAutoML, H2OAutoML, FLAML, MLJAR, TPOT and GAMA, which mainly focus on tabular data for classification or regression. AutoMM is designed for fine-tuning foundation models across multiple modalities—image, text, tabular, and document, either individually or combined. It offers extensive capabilities for tasks like classification, regression, object detection, named entity recognition, semantic matching, and image segmentation. In contrast, other AutoML systems generally have limited support for image or text, typically using a few pretrained models like EfficientNet or hand-crafted rules like bag-of-words as feature extractors. They often rely on traditional models or simple neural networks. AutoMM provides a uniquely comprehensive and versatile approach to AutoML, being the only AutoML system to support flexible multimodality and support for a wide range of tasks. A comparative table detailing support for various data modalities, tasks, and model types is provided below.
数据 |
任务 |
模型 |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
图片 |
文本 |
表格 |
文档 |
任何组合 |
分类 |
回归 |
目标检测 |
语义匹配 |
命名实体识别 |
图像分割 |
传统模型 |
深度学习模型 |
基础模型 |
|
LightAutoML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
H2O自动机器学习 |
✓ |
✓ |
✓ |
✓ |
||||||||||
FLAML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
MLJAR |
✓ |
✓ |
✓ |
✓ |
||||||||||
自动Sklearn |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||||
GAMA |
✓ |
✓ |
✓ |
✓ |
||||||||||
TPOT |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
||||||||
AutoMM |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
特别感谢
我们希望通过感谢Pieter Gijsbers、Sébastien Poirier、Erin LeDell、Joaquin Vanschoren以及AutoML Benchmark的其他作者来结束这个亮点,他们在提供一个共享且广泛的基准以监控AutoML领域的进展中发挥了关键作用。他们的支持对AutoGluon项目的持续增长至关重要。
我们还要感谢Frank Hutter,他一直是AutoML领域的领导者,组织了2022年和2023年的AutoML会议,将社区聚集在一起分享想法并对一个引人注目的愿景达成一致。
最后,我们要感谢Alex Smola和Mu Li在亚马逊倡导开源软件,使这个项目成为可能。
特别感谢
特别感谢@LennartPurucker领导动态堆栈的开发
Special thanks to @geoalgo for co-authoring TabRepo to enable Zeroshot-HPO
特别感谢 @ddelange 帮助添加 Python 3.11 支持
特别感谢 @mglowacki100 提供了大量的反馈和建议
特别感谢 @Harry-zzh 贡献了新的语义分割问题类型
通用
亮点
Python 3.11 支持 @ddelange @yinweisu (#3190)
其他增强功能
添加了系统信息日志记录工具 @Innixma (#3718)
依赖更新
将torch升级到
>=2.0,<2.2@zhiqiangdon @yinweisu @shchur (#3404, #3587, #3588)将numpy升级到
>=1.21,<1.29@prateekdesai04 (#3709)将Pandas升级到
>=2.0,<2.2@yinweisu @tonyhoo @shchur (#3498)升级了scikit-learn到
>=1.3,<1.5@yinweisu @tonyhoo @shchur (#3498)升级了Pillow到
>=10.0.1,<11@jaheba (#3688)升级了scipy到
>=1.5.4,<1.13@prateekdesai04 (#3709)已将LightGBM升级至
>=3.3,<4.2@mglowacki100 @prateekdesai04 @Innixma (#3427, #3709, #3733)将XGBoost升级到
>=1.6,<2.1@Innixma (#3768)各种次要依赖更新 @jaheba (#3689)
Tabular
亮点
AutoGluon 1.0 在预测质量方面进行了重大改进,确立了表格建模的新技术水平。更多详情请参阅上面的亮点部分!
新功能
添加了
dynamic_stacking预测器拟合参数以减轻 堆叠过拟合 @LennartPurucker @Innixma (#3616)添加了zeroshot-HPO learned portfolio作为
best_quality和high_quality预设的新超参数。@Innixma @geoalgo (#3750)为TabularPredictor添加了实验性的scikit-learn API兼容包装器。您可以通过
from autogluon.tabular.experimental import TabularClassifier, TabularRegressor访问它们。@Innixma (#3769)添加了
predictor.model_failures()@Innixma (#3421)添加了增强的FT-Transformer @taoyang1122 @Innixma (#3621, #3644, #3692)
添加了
predictor.simulation_artifact()以支持与 TabRepo 的集成 @Innixma (#3555)
性能改进
通过输出裁剪增强FastAI模型在回归上的质量 @LennartPurucker @Innixma (#3597)
添加了跳过连接加权集成 @LennartPurucker (#3598)
通过使用ray进程进行顺序拟合来修复内存泄漏 @LennartPurucker (#3614)
添加了动态并行折叠支持,以在低内存场景中更好地利用计算 @yinweisu @Innixma (#3511)
修复了HPO期间线性模型崩溃的问题,并为线性模型添加了搜索空间 @Innixma (#3571, #3720)
其他增强功能
多层堆叠现在产生确定性结果 @LennartPurucker (#3573)
各种模型依赖更新 @mglowacki100 (#3373)
各种代码清理和日志记录改进 @Innixma (#3408, #3570, #3652, #3734)
Bug 修复 / 代码和文档改进
修复了不正确的模型内存使用计算 @Innixma (#3591)
修复了在bagging时错误使用
infer_limit的问题 @Innixma (#3467)修复了罕见的边缘情况 FastAI 模型崩溃 @Innixma (#3416)
各种小错误修复 @Innixma (#3418, #3480)
AutoMM
AutoGluon Multimodal (AutoMM) 旨在简化基础模型在下游应用中的微调,只需三行代码即可完成。 它无缝集成了流行的模型库,如 HuggingFace Transformers、 TIMM 和 MMDetection, 支持多种数据模态,包括图像、文本、表格和文档数据,无论是单独使用还是组合使用。
新功能
语义分割
介绍新的问题类型
semantic_segmentation,用于通过三行代码微调 Segment Anything Model (SAM)。@Harry-zzh @zhiqiangdon (#3645, #3677, #3697, #3711, #3722, #3728)添加了来自不同领域的全面基准测试, 包括自然图像、农业、遥感和医疗保健。
利用参数高效微调(PEFT)LoRA,展示了在广泛的基准测试中优于其他方法(VPT, adaptor, BitFit, SAM-adaptor, 和 LST)的持续优越性能。
添加了一个语义分割教程 @zhiqiangdon (#3716)。
默认使用 SAM-ViT Huge(需要 GPU 内存大于 25GB)。
少样本分类
新增了
few_shot_classification问题类型,用于在图像或文本上训练少样本分类器。@zhiqiangdon (#3662, #3681, #3695)利用图像/文本基础模型提取特征并训练SVM分类器。
添加了一个少样本分类教程。@zhiqiangdon (#3662)
支持 torch.compile 以加速训练(实验性功能,需要 torch >=2.2)@zhiqiangdon (#3520)。
性能改进
改进了默认的图像骨干网络,在图像基准测试中实现了100%的胜率。@taoyang1122 (#3738)
将MLPs替换为FT-Transformer作为默认的表格骨干网络,在文本+表格基准测试中获得了67%的胜率。@taoyang1122 (#3732)
使用改进的默认图像骨干和FT-Transformer在文本+表格+图像基准测试中实现了62%的胜率。@taoyang1122 (#3732, #3738)
稳定性增强
启用了严格的多GPU CI测试。@prateekdesai04 (#3566)
修复了多GPU问题。@FANGAreNotGnu (#3617 #3665 #3684 #3691, #3639, #3618)
增强的可用性
支持自定义评估指标,允许定义自定义的指标对象并将其传递给
eval_metric参数。@taoyang1122 (#3548)在笔记本中支持多GPU训练(实验性)。@zhiqiangdon (#3484)
改进了包含系统信息的日志记录。@zhiqiangdon (#3735)
改进的可扩展性
新学习者类设计的引入使得在AutoMM中更容易支持新任务和数据模式,从而增强了整体的可扩展性。@zhiqiangdon (#3650, #3685, #3735)
其他增强功能
添加了选项
hf_text.use_fast用于自定义hf_text模型中的快速分词器使用。@zhiqiangdon (#3379)添加了备用评估/验证指标,支持
f1_macrof1_micro和f1_weighted。@FANGAreNotGnu (#3696)支持使用DDP策略进行多GPU推理。@zhiqiangdon (#3445, #3451)
已将torch升级至2.0。@zhiqiangdon (#3404)
升级了lightning到2.0 @zhiqiangdon (#3419)
已将 torchmetrics 升级至 1.0 @zhiqiangdon (#3422)
代码改进
使用学习者类重构了AutoMM,以改进设计。@zhiqiangdon (#3650, #3685, #3735)
重构了FT-Transformer。@taoyang1122 (#3621, #3700)
重构了目标检测、语义分割和NER的可视化工具。@zhiqiangdon (#3716)
其他代码重构/清理:@zhiqiangdon @FANGAreNotGnu (#3383 #3399 #3434 #3667 #3684 #3695)
错误修复/文档改进
修复了焦点损失的HPO。@suzhoum (#3739)
修复了一个ONNX导出问题。@AnirudhDagar (#3725)
改进了AutoMM的介绍以提高清晰度。@zhiqiangdon (#3388 #3726)
改进了AutoMM API文档。@zhiqiangdon @AnirudhDagar (#3772 #3777)
其他错误修复 @zhiqiangdon @FANGAreNotGnu @taoyang1122 @tonyhoo @rsj123 @AnirudhDagar (#3384, #3424, #3526, #3593, #3615, #3638, #3674, #3693, #3702, #3690, #3729, #3736, #3474, #3456, #3590, #3660)
其他文档改进 @zhiqiangdon @FANGAreNotGnu @taoyang1122 (#3397, #3461, #3579, #3670, #3699, #3710, #3716, #3737, #3744, #3745, #3680)
时间序列
亮点
AutoGluon 1.0 在 TimeSeries 模块中引入了许多可用性和性能的改进。这些改进包括自动处理缺失数据和不规则时间序列、新的预测指标(包括自定义指标支持)、高级时间序列交叉验证选项以及新的预测模型。AutoGluon 在预测准确性方面取得了最先进的结果,与其他流行的预测框架相比,实现了70%+ 的胜率。
新功能
支持自定义预测指标 @shchur (#3760, #3602)
新的预测指标
WAPE,RMSSE,SQL+ 改进的 指标文档 @melopeo @shchur (#3747, #3632, #3510, #3490)改进的鲁棒性:
TimeSeriesPredictor现在可以处理具有所有 pandas 频率、不规则时间戳或由NaN表示的缺失值的数据 @shchur (#3563, #3454)新模型:基于保形预测的间歇需求预测模型(
ADIDA,CrostonClassic,CrostonOptimized,CrostonSBA,IMAPA);来自GluonTS的WaveNet和NPTS;新的基线模型(Average,SeasonalAverage,Zero)@canerturkmen @shchur (#3706, #3742, #3606, #3459)高级交叉验证选项:使用
refit_every_n_windows避免为每个验证窗口重新训练模型,或使用val_step_size参数调整验证窗口之间的步长,传递给TimeSeriesPredictor.fit@shchur (#3704, #3537)
增强功能
为深度学习预测模型启用Ray Tune @canerturkmen (#3705)
支持向
TimeSeriesPredictor.evaluate传递多个评估指标 @shchur (#3646)现在可以将静态特征直接传递给
TimeSeriesDataFrame.from_path和TimeSeriesDataFrame.from_data_frame构造函数 @shchur (#3635)
性能改进
由于新的预设和更新的逻辑,用于在模型之间分配训练时间,因此在较短的时间限制下,预测更加准确 @shchur (#3749, #3657, #3741)
更快的训练和预测 + 更低的内存使用率,适用于
DirectTabular和RecursiveTabular模型 (#3740, #3620, #3559)启用提前停止并提高GluonTS模型的推理速度 @shchur (#3575)
通过将导入语句移动到模型类内部,减少
autogluon.timeseries的导入时间(#3514)
Bug 修复 / 代码和文档改进
改进日志消息 @shchur (#3721)
在README中添加对AutoGluon-TimeSeries出版物的引用 @shchur (#3482)
将
TimeSeriesPredictor的API与TabularPredictor对齐,移除已弃用的方法 @shchur (#3714, #3655, #3396)一般错误修复和改进 @shchur(#3758, #3756, #3755, #3754, #3746, #3743, #3727, #3698, #3654, #3653, #3648, #3628, #3588, #3560, #3558, #3536, #3533, #3523, #3522, #3476, #3463)
探索性数据分析
EDA模块将在稍后发布,因为它需要额外的开发工作才能准备好1.0版本。
当EDA准备好发布时,我们将发布公告。目前,请继续使用"autogluon.eda==0.8.2"。
弃用
通用
autogluon.core.spaces已被弃用。请改用autogluon.common.spaces@Innixma (#3701)
Tabular
如果使用已弃用的方法,Tabular 将记录警告。已弃用的方法计划在 AutoGluon 1.2 @Innixma (#3701) 中移除。
autogluon.tabular.TabularPredictorpredictor.get_model_names()->predictor.model_names()predictor.get_model_names_persisted()->predictor.model_names(persisted=True)predictor.compile_models()->predictor.compile()predictor.persist_models()->predictor.persist()predictor.unpersist_models()->predictor.unpersist()predictor.get_model_best()->predictor.model_bestpredictor.get_pred_from_proba()->predictor.predict_from_proba()predictor.get_oof_pred_proba()->predictor.predict_proba_oof()predictor.get_oof_pred()->predictor.predict_oof()predictor.get_model_full_dict()->predictor.model_refit_map()predictor.get_size_disk()->predictor.disk_usage()predictor.get_size_disk_per_file()->predictor.disk_usage_per_file()predictor.leaderboard()silent参数已弃用,替换为display,默认值为 False同样适用于
predictor.evaluate()和predictor.evaluate_predictions()
AutoMM
已弃用
FewShotSVMPredictor,推荐使用新的few_shot_classification问题类型 @zhiqiangdon (#3699)已弃用
AutoMMPredictor,改用MultiModalPredictor@zhiqiangdon (#3650)autogluon.multimodal.MultiModalPredictor弃用了 fit API 中的
config参数。@zhiqiangdon (#3679)已弃用init API中的
init_scratch和pipeline参数 @zhiqiangdon (#3668)
时间序列
autogluon.timeseries.TimeSeriesPredictor已弃用的参数
TimeSeriesPredictor(ignore_time_index: bool)。现在,如果数据包含不规则的时间戳,可以使用data = data.convert_frequency(freq)将其转换为规则的频率,或者在创建预测器时提供频率,如TimeSeriesPredictor(freq=freq)。predictor.evaluate()现在返回一个字典(之前返回的是一个浮点数)predictor.score()->predictor.evaluate()predictor.get_model_names()->predictor.model_names()predictor.get_model_best()->predictor.model_best指标
"mean_wQuantileLoss"已更名为"WQL"predictor.leaderboard()silentargument deprecated, replaced bydisplay, defaults to False当在
predictor.fit()中将hyperparameters设置为字符串时,现在支持的值为"default"、"light"和"very_light"
autogluon.timeseries.TimeSeriesDataFramedf.to_regular_index()->df.convert_frequency()已弃用的方法
df.get_reindexed_view()。请参阅上面TimeSeriesPredictor下的ignore_time_index的弃用说明,了解如何处理不规则时间戳
模型
所有基于MXNet的模型(
DeepARMXNet,MQCNNMXNet,MQRNNMXNet,SimpleFeedForwardMXNet,TemporalFusionTransformerMXNet,TransformerMXNet)已被移除来自Statmodels的统计模型(
ARIMA,Theta,ETS)已被StatsForecast中的对应模型替换(#3513)。请注意,这些模型现在具有不同的超参数名称。DirectTabular现在使用mlforecast后端实现(与RecursiveTabular相同),模型的大多数超参数名称已更改。
autogluon.timeseries.TimeSeriesEvaluator已被弃用。请改用autogluon.timeseries.metrics中提供的指标。autogluon.timeseries.splitter.MultiWindowSplitter和autogluon.timeseries.splitter.LastWindowSplitter已被弃用。请使用num_val_windows和val_step_size参数来替代TimeSeriesPredictor.fit(或者使用autogluon.timeseries.splitter.ExpandingWindowSplitter)。
论文
AutoGluon-TimeSeries: 用于概率时间序列预测的AutoML
我们在2023年AutoML会议上发表了一篇关于AutoGluon-TimeSeries的论文(论文链接, YouTube视频)。 在论文中,我们对AutoGluon和流行的开源预测框架(包括DeepAR、TFT、AutoARIMA、AutoETS、AutoPyTorch)进行了基准测试。 AutoGluon在点预测和概率预测方面取得了SOTA结果,甚至在与最佳事后模型组合的对比中取得了65%的胜率。
TabRepo: 一个大规模的表格模型评估库及其AutoML应用
我们已经在arXiv上发表了一篇关于表格零样本超参数优化(Tabular Zeroshot-HPO)集成模拟的论文(论文链接, GitHub)。 这篇论文对于实现AutoGluon 1.0中看到的性能提升至关重要,我们计划继续开发代码库以支持未来的增强功能。
XTab: 表格Transformers的跨表预训练
我们在ICML 2023上发表了一篇关于表格Transformer预训练的论文(论文链接, GitHub)。 在论文中,我们展示了表格深度学习模型的最先进性能,包括能够匹配XGBoost和LightGBM模型的性能。 虽然预训练的Transformer尚未集成到AutoGluon中,但我们计划在未来的版本中集成它。
学习特征空间中的多模态数据增强
我们关于学习多模态数据增强的论文被ICLR 2023接受(论文链接, GitHub)。 这篇论文介绍了一个即插即用的模块,用于在特征空间中学习多模态数据增强, 对模态的身份或模态之间的关系没有任何限制。 我们展示了它可以(1)提高多模态深度学习架构的性能, (2)适用于以前未考虑过的模态组合, 以及(3)在由图像、文本和表格数据组成的广泛应用中实现最先进的结果。这项工作尚未纳入AutoGluon,但我们计划在未来的版本中集成它。
通过可控扩散模型进行目标检测的数据增强
我们关于生成式目标检测数据增强的论文已被WACV 2024接受(论文和GitHub链接将很快提供)。 本文提出了一种基于可控扩散模型和CLIP的数据增强流程, 通过视觉先验生成来指导生成,并通过类别校准的CLIP分数进行后过滤以控制其质量。 我们展示了在使用我们的增强流程与不同检测器时,各种任务和设置中的性能都有所提升。 尽管扩散模型目前尚未集成到AutoGluon中,但我们计划在未来的版本中纳入数据增强技术。
将图像基础模型应用于视频理解
我们在ICLR 2023上发表了一篇关于如何高效地将图像基础模型应用于视频理解的论文(论文链接, GitHub)。这篇论文介绍了空间适应、时间适应和联合适应,逐步为冻结的图像模型赋予时空推理能力。所提出的方法在显著节省大型基础模型训练成本的同时,实现了与传统全微调相当甚至更好的性能。
v0.8.3
版本 0.8.3
v0.8.3 是一个修补版本,用于解决安全漏洞。
查看完整的提交变更日志请访问:https://github.com/autogluon/autogluon/compare/v0.8.2…v0.8.3
此版本支持 Python 3.8、3.9 和 3.10 版本。
更改
transformersand other packages version upgrades + some fixes. @suzhoum (#4155)
v0.8.2
Version 0.8.2
v0.8.2 is a hot-fix release to pin pydantic version to avoid crashing during HPO
一如既往,仅使用与原始训练时相同版本的AutoGluon加载先前训练的模型。 不支持加载在不同版本的AutoGluon中训练的模型。
查看完整的提交变更日志请访问:https://github.com/autogluon/autogluon/compare/v0.8.1…v0.8.2
此版本支持 Python 3.8、3.9 和 3.10 版本。
更改
codespell: 动作, 配置 + 修复了一些拼写错误 @yarikoptic @yinweisu (#3323)
取消固定 sentencepiece @zhiqiangdon (#3368)
Pin pydantic @yinweisu (3370)
v0.8.1
版本 0.8.1
v0.8.1 是一个错误修复版本。
一如既往,仅使用与原始训练时相同版本的AutoGluon加载先前训练的模型。 不支持加载在不同版本的AutoGluon中训练的模型。
查看完整的提交变更日志请访问:https://github.com/autogluon/autogluon/compare/v0.8.0…v0.8.1
此版本支持 Python 3.8、3.9 和 3.10 版本。
更改
文档改进
更新谷歌分析属性 @gidler (#3330)
添加 Discord 链接 @Innixma (#3332)
在网站首页添加社区部分 @Innixma (#3333)
更新Windows Conda安装说明 @gidler (#3346)
在教程中添加一些缺失的Colab按钮 @gidler (#3359)
Bug 修复 / 常规改进
将PyMuPDF移至可选 @Innixma @zhiqiangdon (#3331)
移除核心设置中的TIMM @Innixma (#3334)
更新 persist_models 的 max_memory 从 0.1 到 0.4 @Innixma (#3338)
Lint模块 @yinweisu (#3337, #3339, #3344, #3347)
移除fairscale @zhiqiangdon (#3342)
修复refit崩溃 @Innixma (#3348)
Fix
DirectTabularmodel failing for some metrics; hide warnings produced byAutoARIMA@shchur (#3350)固定依赖 @yinweisu (#3358)
减少AutoMM high_quality_hpo的每个GPU的批量大小,以避免在某些极端情况下出现内存不足的错误 @zhiqiangdon (#3360)
通过将 reuse_actor 设置为 False 修复 HPO 崩溃 @yinweisu (#3361)
v0.8.0
版本 0.8.0
我们很高兴宣布AutoGluon 0.8版本的发布。
注意:不支持加载在不同版本的AutoGluon中训练的模型。
此版本包含来自20位贡献者的196次提交!
查看完整的提交变更日志请访问:https://github.com/autogluon/autogluon/compare/0.7.0…0.8.0
特别感谢 @geoalgo 在本版本中生成实验性表格 Zeroshot-HPO 组合的联合工作!
完整贡献者列表(按提交次数排序):
@shchur, @Innixma, @yinweisu, @gradientsky, @FANGAreNotGnu, @zhiqiangdon, @gidler, @liangfu, @tonyhoo, @cheungdaven, @cnpgs, @giswqs, @suzhoum, @yongxinw, @isunli, @jjaeyeon, @xiaochenbin9527, @yzhliu, @jsharpna, @sxjscience
AutoGluon 0.8 支持 Python 版本 3.8、3.9 和 3.10。
更改
亮点
AutoGluon TimeSeries 引入了几项重大改进,包括新模型、升级的预设以提高预测准确性,以及加速训练和推理的优化。
AutoGluon Tabular now supports calibrating the decision threshold in binary classification (API), leading to massive improvements in metrics such as
f1andbalanced_accuracy. It is not uncommon to seef1scores improve from0.70to0.73as an example. We strongly encourage all users who are using these metrics to try out the new decision threshold calibration logic.AutoGluon MultiModal introduces two new features: 1) PDF document classification, and 2) Open Vocabulary Object Detection.
AutoGluon MultiModal upgraded the presets for object detection, now offering
medium_quality,high_quality, andbest_qualityoptions. The empirical results demonstrate significant ~20% relative improvements in the mAP (mean Average Precision) metric, using the same preset.AutoGluon Tabular has added an experimental Zeroshot HPO config which performs well on small datasets <10000 rows when at least an hour of training time is provided (~60% win-rate vs
best_quality). To try it out, specifypresets="experimental_zeroshot_hpo_hybrid"when callingfit().AutoGluon EDA added support for Anomaly Detection and Partial Dependence Plots.
AutoGluon Tabular has added experimental support for TabPFN, a pre-trained tabular transformer model. Try it out via
pip install autogluon.tabular[all,tabpfn](hyperparameter key is “TABPFN”)!
通用
文档总体改进 @tonyhoo @Innixma @yinweisu @gidler @cnpgs @isunli @giswqs (#2940, #2953, #2963, #3007, #3027, #3059, #3068, #3083, #3128, #3129, #3130, #3147, #3174, #3187, #3256, #3258, #3280, #3306, #3307, #3311, #3313)
通用代码修复和改进 @yinweisu @Innixma (#2921, #3078, #3113, #3140, #3206)
CI改进 @yinweisu @gidler @yzhliu @liangfu @gradientsky (#2965, #3008, #3013, #3020, #3046, #3053, #3108, #3135, #3159, #3283, #3185)
新的AutoGluon网页 @gidler @shchur (#2924)
在RMSE中支持sample_weight @jjaeyeon (#3052)
将AG搜索空间移至公共 @yinweisu (#3192)
弃用工具 @yinweisu (#3206, #3209)
更新命名空间包以兼容PEP420 @gradientsky (#3228)
Multimodal
AutoGluon MultiModal (also known as AutoMM) introduces two new features: 1) PDF document classification, and 2) Open Vocabulary Object Detection. Additionally, we have upgraded the presets for object detection, now offering medium_quality, high_quality, and best_quality options. The empirical results demonstrate significant ~20% relative improvements in the mAP (mean Average Precision) metric, using the same preset.
新功能
PDF Document Classification. See tutorial @cheungdaven (#2864, #3043)
Open Vocabulary Object Detection. See tutorial @FANGAreNotGnu (#3164)
性能改进
将检测引擎从 mmdet 2.x 升级到 mmdet 3.x,并升级我们的预设 @FANGAreNotGnu (#3262)
medium_quality: yolo-s -> yolox-lhigh_quality: yolox-l -> DINO-Res50best_quality: yolox-x -> DINO-Swin_l
使用deepspeed策略加速融合模型训练。@liangfu (#2932)
启用检测骨干网络冻结以提升微调速度并节省GPU使用 @FANGAreNotGnu (#3220)
其他增强功能
支持将数据路径传递给 fit() API @zhiqiangdon (#3006)
将TIMM升级到最新的v0.9.* @zhiqiangdon (#3282)
支持xywh输出用于目标检测 @FANGAreNotGnu (#2948)
使用TensorRT进行融合模型推理加速 @liangfu (#2836, #2987)
Support customizing advanced image data augmentation. Users can pass a list of torchvision transform objects as image augmentation. @zhiqiangdon (#3022)
添加 yoloxm 和 yoloxtiny @FangAreNotGnu (#3038)
为对象检测添加MultiImageMix数据集 @FangAreNotGnu (#3094)
支持加载特定的检查点。用户可以加载除model.ckpt和last.ckpt之外的中间检查点。@zhiqiangdon (#3244)
为模型统计添加一些预测器属性 @zhiqiangdon (#3289)
trainable_parametersreturns the number of trainable parameters.total_parametersreturns the number of total parameters.model_sizereturns the model size measured by megabytes.
Bug 修复 / 代码和文档改进
一般错误修复和改进 @zhiqiangdon @liangfu @cheungdaven @xiaochenbin9527 @Innixma @FANGAreNotGnu @gradientsky @yinweisu @yongxinw (#2939, #2989, #2983, #2998, #3001, #3004, #3006, #3025, #3026, #3048, #3055, #3064, #3070, #3081, #3090, #3103, #3106, #3119, #3155, #3158, #3167, #3180, #3188, #3222, #3261, #3266, #3277, #3279, #3261, #3267)
文档总体改进 @suzhoum (#3295, #3300)
从融合模型中移除剪辑 @liangfu (#2946)
重构推断问题类型和输出形状 @zhiqiangdon (#3227)
在训练期间记录GPU信息,包括GPU总内存、空闲内存、GPU卡名称和CUDA版本 @zhiqaingdon (#3291)
Tabular
新功能
Added
calibrate_decision_threshold(tutorial), which allows to optimize a given metric’s decision threshold for predictions to strongly enhance the metric score. @Innixma (#3298)We’ve added an experimental Zeroshot HPO config, which performs well on small datasets <10000 rows when at least an hour of training time is provided. To try it out, specify
presets="experimental_zeroshot_hpo_hybrid"when callingfit()@Innixma @geoalgo (#3312)The TabPFN model is now supported as an experimental model. TabPFN is a viable model option when inference speed is not a concern, and the number of rows of training data is less than 10,000. Try it out via
pip install autogluon.tabular[all,tabpfn]! @Innixma (#3270)后端支持分布式训练,将在下一个云模块发布时提供。@yinweisu (#3054, #3110, #3115, #3131, #3142, #3179, #3216)
性能改进
加速布尔预处理 @Innixma (#2944)
其他增强功能
为CatBoost添加分位数回归支持 @shchur (#3165)
为LGBModel实现分位数回归 @shchur (#3168)
支持记录到文件 @yinweisu (#3232)
Add support for
included_model_types@yinweisu (#3239)为XGBoost添加enable_categorical=True支持 @Innixma (#3286)
Bug 修复 / 代码和文档改进
跨操作系统加载一个合适的TabularPredictor现在应该可以正常工作 @yinweisu @Innixma
一般错误修复和改进 @Innixma @cnpgs @shchur @yinweisu @gradientsky (#2865, #2936, #2990, #3045, #3060, #3069, #3148, #3182, #3199, #3226, #3257, #3259, #3268, #3269, #3287, #3288, #3285, #3293, #3294, #3302)
将可解释的逻辑移动到InterpretableTabularPredictor @Innixma (#2981)
增强drop_duplicates,默认启用 @Innixma (#3010)
重构 params_aux 和内存检查 @Innixma (#3033)
Raise regression
pred_proba@Innixma (#3240)
时间序列
在v0.8版本中,我们为时间序列模块引入了几项重大改进,包括新模型、升级的预设以提高预测准确性,以及加速训练和推理的优化。
亮点
New models:
PatchTSTandDLinearfrom GluonTS, andRecursiveTabularbased on integration with themlforecastlibrary @shchur (#3177, #3184, #3230)由于更新了预设 @shchur (#3281, #3120),提高了准确性并减少了整体训练时间。
3-6x faster training and inference for
AutoARIMA,AutoETS,Theta,DirectTabular,WeightedEnsemblemodels @shchur (#3062, #3214, #3252)
新功能
Dramatically faster repeated calls to
predict(),leaderboard()andevaluate()thanks to prediction caching @shchur (#3237)Reduce overfitting by using multiple validation windows with the
num_val_windowsargument tofit()@shchur (#3080)Exclude certain models from presets with the
excluded_model_typesargument tofit()@shchur (#3231)New method
refit_full()that refits models on combined train and validation data @shchur (#3157)Train multiple configurations of the same model by providing lists in the
hyperparametersargument @shchur (#3183)Time limit set by
time_limitis now respected by all models @shchur (#3214)
增强功能
Improvements to the
DirectTabularmodel (previously calledAutoGluonTabular): faster featurization, trained as a quantile regression model ifeval_metricis set to"mean_wQuantileLoss"@shchur (#2973, #3211)在计算MASE指标时使用正确的季节性周期 @shchur (#2970)
Check the AutoGluon version when loading
TimeSeriesPredictorfrom disk @shchur (#3233)
小改进 / 文档 / 错误修复
更新文档和教程 @shchur (#2960, #2964, #3296, #3297)
一般错误修复和改进 @shchur (#2977, #3058, #3066, #3160, #3193, #3202, #3236, #3255, #3275, #3290)
探索性数据分析 (EDA) 工具
在0.8版本中,我们引入了一些新工具来帮助数据探索和特征工程:
Anomaly Detection @gradientsky (#3124, #3137) - helps to identify unusual patterns or behaviors in data that deviate significantly from the norm. It’s best used when finding outliers, rare events, or suspicious activities that could indicate fraud, defects, or system failures. Check the Anomaly Detection Tutorial to explore the functionality.
Partial Dependence Plots @gradientsky (#3071, #3079) - visualize the relationship between a feature and the model’s output for each individual instance in the dataset. Two-way variant can visualize potential interactions between any two features. Please see this tutorial for more detail: Using Interaction Charts To Learn Information About the Data
Bug 修复 / 代码和文档改进
Switch regression analysis in
quick_fitto use residuals plot @gradientsky (#3039)Added
explain_rowsmethod toautogluon.eda.auto- Kernel SHAP visualization @gradientsky (#3014)一般改进和修复 @gradientsky (#2991, #3056, #3102, #3107, #3138)