模型#
1. 概念#
模型是智能代理的大脑,负责处理所有输入和输出数据以执行文本分析、图像识别和复杂推理等任务。通过可定制的接口和多种集成选项,CAMEL AI能够快速开发领先的大型语言模型。
探索代码:查看我们的Colab Notebook进行实际操作演示。
2. CAMEL支持的模型平台#
CAMEL支持多种模型,包括OpenAI的GPT系列、Meta的Llama模型、DeepSeek模型(R1及其他变体)等。下表列出了所有支持的模型平台:
模型平台 |
模型类型 |
|---|---|
OpenAI |
gpt-4.5-preview, gpt-4o, gpt-4o-mini, o1, o1-preview, o1-mini, o3-mini, gpt-4-turbo, gpt-4, gpt-3.5-turbo |
Azure OpenAI |
gpt-4o, gpt-4-turbo, gpt-4, gpt-3.5-turbo |
Mistral AI |
mistral-large-latest, pixtral-12b-2409, ministral-8b-latest, ministral-3b-latest, open-mistral-nemo, codestral-latest, open-mistral-7b, open-mixtral-8x7b, open-mixtral-8x22b, open-codestral-mamba |
Moonshot |
moonshot-v1-8k, moonshot-v1-32k, moonshot-v1-128k |
Anthropic |
claude-2.1, claude-2.0, claude-instant-1.2, claude-3-opus-latest, claude-3-sonnet-20240229, claude-3-haiku-20240307, claude-3-5-sonnet-latest, claude-3-5-haiku-latest |
Gemini |
gemini-2.0-flash-exp, gemini-1.5-pro, gemini-1.5-flash, gemini-exp-1114 |
零一万物 |
yi-lightning, yi-large, yi-medium, yi-large-turbo, yi-vision, yi-medium-200k, yi-spark, yi-large-rag, yi-large-fc |
Qwen |
qwq-32b-preview, qwen-max, qwen-plus, qwen-turbo, qwen-long, qwen-vl-max, qwen-vl-plus, qwen-math-plus, qwen-math-turbo, qwen-coder-turbo, qwen2.5-coder-32b-instruct, qwen2.5-72b-instruct, qwen2.5-32b-instruct, qwen2.5-14b-instruct |
深度求索 |
deepseek-chat, deepseek-reasoner |
智谱AI |
glm-4, glm-4v, glm-4v-flash, glm-4v-plus-0111, glm-4-plus, glm-4-air, glm-4-air-0111, glm-4-airx, glm-4-long, glm-4-flashx, glm-zero-preview, glm-4-flash, glm-3-turbo |
InternLM |
internlm3-latest, internlm3-8b-instruct, internlm2.5-latest, internlm2-pro-chat |
Reka |
reka-core, reka-flash, reka-edge |
COHERE |
command-r-plus, command-r, command-light, command, command-nightly |
GROQ |
|
TOGETHER AI |
|
SambaNova |
|
Ollama |
|
OpenRouter |
|
PPIO |
|
LiteLLM |
|
vLLM |
|
SGLANG |
|
NVIDIA |
|
AIML |
|
ModelScope |
3. 如何通过API调用使用模型#
使用简单的API调用即可轻松将您选择的模型与CAMEL AI集成。例如,要使用gpt-4o-mini模型:
如果您想使用其他模型,只需更改这三个参数:
model_platform、model_type和model_config_dict。
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType
from camel.configs import ChatGPTConfig
from camel.messages import BaseMessage
from camel.agents import ChatAgent
# Define the model, here in this case we use gpt-4o-mini
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI,
model_type=ModelType.GPT_4O_MINI,
model_config_dict=ChatGPTConfig().as_dict(),
)
# Define an assistant message
system_msg = "You are a helpful assistant."
# Initialize the agent
ChatAgent(system_msg, model=model)
如果你想使用与OpenAI兼容的API,可以将
model替换为以下代码:
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="a-string-representing-the-model-type",
api_key=os.environ.get("OPENAI_COMPATIBILITY_API_KEY"),
url=os.environ.get("OPENAI_COMPATIBILITY_API_BASE_URL"),
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
4. 使用设备上的开源模型#
CAMEL AI 还支持开源LLM的本地部署。选择适合您项目的设置:
4.1 使用Ollama在本地设置Llama 3#
下载 Ollama。
设置好Ollama后,为您的项目选择一个模型,比如Llama3:
ollama pull llama3
在您的项目目录中创建一个类似于下面的
ModelFile。(可选)
FROM llama3
# Set parameters
PARAMETER temperature 0.8
PARAMETER stop Result
# Sets a custom system message to specify the behavior of the chat assistant
# Leaving it blank for now.
SYSTEM """ """
创建一个脚本来获取基础模型(llama3)并使用上面的
ModelFile创建自定义模型。将其保存为.sh文件:(可选)
#!/bin/zsh
# variables
model_name="llama3"
custom_model_name="camel-llama3"
#get the base model
ollama pull $model_name
#create the model file
ollama create $custom_model_name -f ./Llama3ModelFile
导航到脚本和
ModelFile所在的目录并运行脚本。享受由CAMEL优秀智能体增强的Llama3模型。
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType
ollama_model = ModelFactory.create(
model_platform=ModelPlatformType.OLLAMA,
model_type="llama3",
url="http://localhost:11434/v1", # Optional
model_config_dict={"temperature": 0.4},
)
agent_sys_msg = "You are a helpful assistant."
agent = ChatAgent(agent_sys_msg, model=ollama_model, token_limit=4096)
user_msg = "Say hi to CAMEL"
assistant_response = agent.step(user_msg)
print(assistant_response.msg.content)
4.2 使用vLLM本地部署Phi-3#
首先安装 vLLM。
在设置好vLLM之后,通过以下方式启动一个与OpenAI兼容的服务器:
python -m vllm.entrypoints.openai.api_server --model microsoft/Phi-3-mini-4k-instruct --api-key vllm --dtype bfloat16
创建并运行以下脚本(更多详情请参考此示例):
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType
vllm_model = ModelFactory.create(
model_platform=ModelPlatformType.VLLM,
model_type="microsoft/Phi-3-mini-4k-instruct",
url="http://localhost:8000/v1", # Optional
model_config_dict={"temperature": 0.0}, # Optional
)
agent_sys_msg = "You are a helpful assistant."
agent = ChatAgent(agent_sys_msg, model=vllm_model, token_limit=4096)
user_msg = "Say hi to CAMEL AI"
assistant_response = agent.step(user_msg)
print(assistant_response.msg.content)
4.3 使用SGLang在本地设置meta-llama/Llama#
首先安装 SGLang。
创建并运行以下脚本(更多详情请参考此示例):
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType
sglang_model = ModelFactory.create(
model_platform=ModelPlatformType.SGLANG,
model_type="meta-llama/Llama-3.2-1B-Instruct",
model_config_dict={"temperature": 0.0},
api_key="sglang",
)
agent_sys_msg = "You are a helpful assistant."
agent = ChatAgent(agent_sys_msg, model=sglang_model, token_limit=4096)
user_msg = "Say hi to CAMEL AI"
assistant_response = agent.step(user_msg)
print(assistant_response.msg.content)
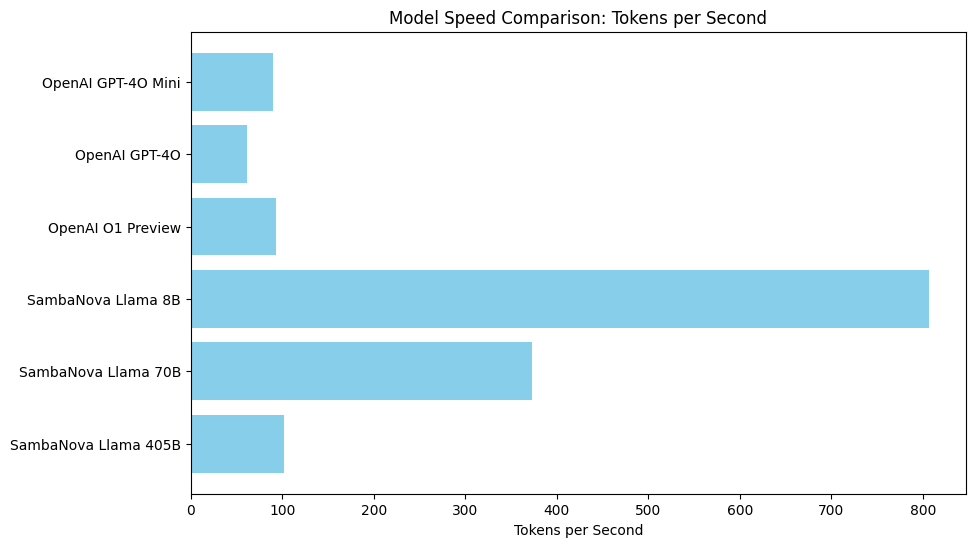
5 模型速度与性能#
性能对于交互式AI应用至关重要。CAMEL-AI对各种模型每秒处理的token数进行了基准测试:
在这个笔记本中,我们通过测量每个模型每秒处理的token数量,比较了多个模型,包括OpenAI的GPT-4O Mini、GPT-4O、O1 Preview以及SambaNova的Llama系列。
关键洞察: 较小型的模型如SambaNova的Llama 8B和OpenAI的GPT-4O Mini通常能提供更快的响应。而较大型的模型如SambaNova的Llama 405B虽然功能更强大,但由于其复杂性,生成输出的速度往往较慢。OpenAI模型展现出相对稳定的性能,而SambaNova的Llama 8B在速度上显著优于其他模型。下图展示了我们测试中每个模型实现的每秒令牌数:
在本地推理方面,我们在本地对vLLM和SGLang进行了直接比较。SGLang展现出更优的性能,使用meta-llama/Llama-3.2-1B-Instruct模型时达到了每秒220.98个token的峰值速度,而vLLM的最高速度为每秒107.2个token。
6. 后续步骤#
你现在已经学会了如何将各种模型集成到CAMEL AI中。
接下来,请查看我们的指南,了解使用BaseMessage创建和转换消息的基础知识。