比较向量索引的性能#
本文档简要概述了比较向量搜索索引和模型的方法。有关如何选择和配置索引类型的指导,请参阅此指南。
与传统数据库索引不同,传统索引即使没有进行性能调优,通常也会返回正确的结果,而向量搜索索引与机器学习模型更为紧密相关,如果未经调优,它们可能会返回完全无用的结果。
因此,在比较两个训练好的索引时,考虑索引构建的参数非常重要,这既关系到其潜在的质量,也关系到吞吐量/延迟。虽然使用默认参数构建索引比调整参数更容易,但一个经过良好调整的索引可以显著提高搜索质量,并且在搜索性能约束(如最大吞吐量和最小延迟)内表现良好。
什么是召回率?#
召回率是衡量模型质量的一个指标。想象一下,对于特定的向量,我们已经计算出了确切的最近邻。查询结果的召回率可以通过计算确切的最近邻和实际的最近邻之间的集合交集来计算。该交集列表中的邻居数量除以k,即请求的邻居数量。为了真正公平地估计模型的召回率,我们使用几个查询向量,所有这些向量都计算了真实值,我们取所有交集邻居列表中的总邻居数,并除以n_queries * k。
参数设置决定了索引的质量。下图显示了来自相同数据但具有不同调优参数的八个索引。一般来说,具有较高平均召回率的索引需要更长的时间来构建。报告哪个索引是公平的?
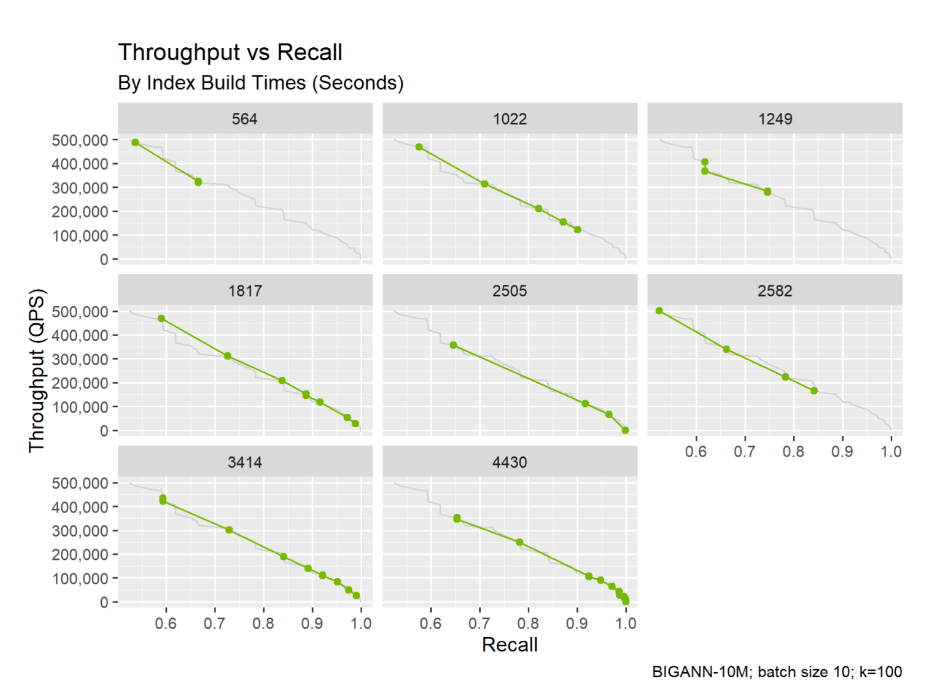
如何比较模型或索引算法?#
为了公平比较索引算法或模型的性能(例如延迟和吞吐量),我们总是需要根据其潜在的召回率来进行比较。这一点很重要,并且源自向量搜索的机器学习根源,但对于可能更熟悉数据库领域的新手来说,这常常令人困惑。
最佳实践:延迟和吞吐量只能在相似的召回率水平下进行比较。如果您在不同召回率水平下测量两个索引的性能,那么您在进行不公平的比较。
由于召回率在不同参数设置下可能会有很大差异,我们倾向于在一小组潜在的分桶内比较召回率,以便可以公平地比较每个分桶内表现的参数设置。
我们建议在召回率范围内平均性能。作为一般指导,我们倾向于使用以下区间:
85% - 89%
90% - 94%
95% - 99%
>99%
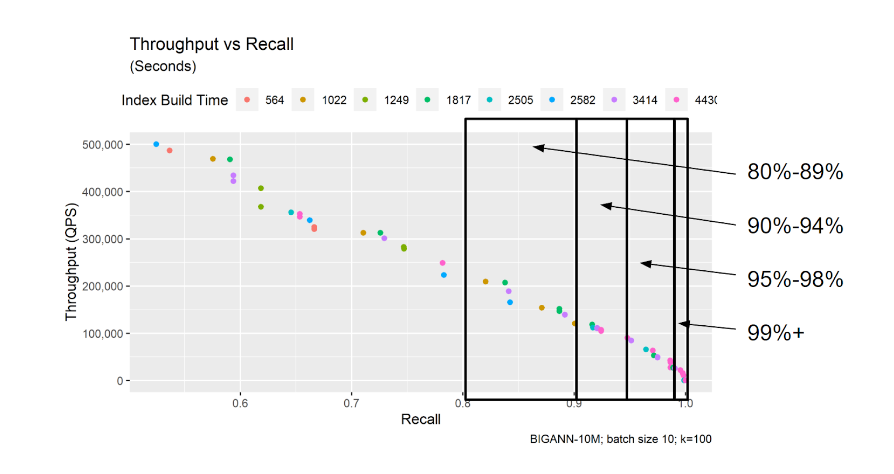
这使我们能够做出诸如“在95%的召回率水平下,模型A的构建速度可以比模型B快3倍,但模型B的延迟比模型A低2倍”的观察。

另一个重要的细节是,我们在每个召回窗口内将这些模型与其最佳搜索性能进行比较。这意味着我们的目标是找到不仅具有出色召回质量,而且在感兴趣的窗口内具有最高吞吐量或最低延迟的模型。这些最佳情况通常通过在网格搜索(或其他类型的搜索优化器)中进行参数扫描并查看每个召回级别的最佳情况来计算。
生成的数据点将构建一条称为帕累托最优的曲线。请注意,此过程专门用于展示召回率和吞吐量/延迟的最佳情况,但当我们关心找到产生最佳召回率和搜索性能的参数时,我们实际上是在进行超参数优化,这在机器学习中很常见。
如何在大型向量数据库上执行此操作?#
事实证明,大多数向量数据库,例如Milvus,会为单个“索引”创建许多较小的向量搜索索引模型,并且假设向量在这些较小的索引模型中的分布是完全均匀的。这意味着我们可以利用子采样的优势,并在整个数据集的较小子样本上进行调优。
请注意,然而,这些较小的索引通常有大小限制,在选择调整子样本的大小时需要考虑到这一点。
请参阅本指南以获取有关进行此子采样和调优过程的更多信息。