优化
Delta Lake 提供了优化功能,可加速数据湖操作。
通过文件管理优化性能
为了提高查询速度,Delta Lake支持优化存储中数据布局的能力。有多种方式可以优化布局。
压缩(装箱优化)
注意
此功能在Delta Lake 1.2.0及以上版本中可用。
Delta Lake 可以通过将小文件合并成较大的文件来提高从表中读取查询的速度。
OPTIMIZE '/path/to/delta/table' -- Optimizes the path-based Delta Lake table
OPTIMIZE delta_table_name;
OPTIMIZE delta.`/path/to/delta/table`;
-- If you have a large amount of data and only want to optimize a subset of it, you can specify an optional partition predicate using `WHERE`:
OPTIMIZE delta_table_name WHERE date >= '2017-01-01'
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, pathToTable) # For path-based tables
# For Hive metastore-based tables: deltaTable = DeltaTable.forName(spark, tableName)
deltaTable.optimize().executeCompaction()
# If you have a large amount of data and only want to optimize a subset of it, you can specify an optional partition predicate using `where`
deltaTable.optimize().where("date='2021-11-18'").executeCompaction()
import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, pathToTable) // For path-based tables
// For Hive metastore-based tables: val deltaTable = DeltaTable.forName(spark, tableName)
deltaTable.optimize().executeCompaction()
// If you have a large amount of data and only want to optimize a subset of it, you can specify an optional partition predicate using `where`
deltaTable.optimize().where("date='2021-11-18'").executeCompaction()
关于Scala、Java和Python API的语法详情,请参阅Delta Lake APIs。
注意
Bin-packing优化是幂等的,这意味着如果在同一数据集上运行两次,第二次运行不会产生任何效果。
Bin-packing(装箱算法)的目标是生成在磁盘大小方面均匀平衡的数据文件,但不一定要求每个文件包含的元组数量相同。不过,这两种衡量标准通常是相关的。
从Delta Lake 2.0版本开始,提供了用于执行
OPTIMIZE操作的Python和Scala API接口。设置Spark会话配置
spark.databricks.delta.optimize.repartition.enabled=true以使用repartition(1)替代coalesce(1),在压缩大量小文件时获得更好的性能。
Delta表的读取器使用快照隔离机制,这意味着当OPTIMIZE从事务日志中删除不必要的文件时,读取操作不会被中断。OPTIMIZE不会对表进行任何数据相关的更改,因此在OPTIMIZE操作前后执行读取会得到相同的结果。对作为流数据源的表执行OPTIMIZE不会影响当前或将任何来将此表作为源的流处理。OPTIMIZE会返回该操作所删除文件和新增文件的统计信息(最小值、最大值、总数等)。优化统计信息还包含优化的批次数量和分区数量。
自动压缩
注意
此功能在 Delta Lake 3.1.0 及以上版本中可用。
自动压缩功能将Delta表分区中的小文件合并,以自动减少小文件问题。自动压缩在表写入成功后触发,并在执行写入的集群上同步运行。自动压缩仅会压缩之前未被压缩过的文件。
您可以通过设置配置项spark.databricks.delta.autoCompact.maxFileSize来控制输出文件大小。
自动压缩仅针对拥有至少一定数量小文件的分区或表触发。您可以通过设置spark.databricks.delta.autoCompact.minNumFiles来可选地更改触发自动压缩所需的最小文件数量。
可以通过以下设置在表级别或会话级别启用自动压缩:
表属性:
delta.autoOptimize.autoCompactSparkSession 设置:
spark.databricks.delta.autoCompact.enabled
这些设置接受以下选项:
选项 |
行为 |
|---|---|
|
启用自动压缩。默认情况下,将使用128 MB作为目标文件大小。 |
|
关闭自动压缩功能。可以在会话级别设置,以覆盖工作负载中修改的所有Delta表的自动压缩设置。 |
数据跳过
注意
此功能在Delta Lake 1.2.0及以上版本中可用。
当您将数据写入Delta Lake表时,系统会自动收集数据跳过信息。Delta Lake在查询时会利用这些信息(每列的最小值和最大值)来提供更快的查询速度。您无需配置数据跳过功能;只要适用,该功能就会自动激活。但其效果取决于数据的布局方式。为了获得最佳效果,请应用Z-Ordering。
对包含长值(如string或binary)的列收集统计信息是一项开销较大的操作。为避免对此类列收集统计信息,您可以配置表属性 delta.dataSkippingNumIndexedCols。该属性表示表中某列在模式中的位置索引,所有位置索引小于delta.dataSkippingNumIndexedCols属性的列都将被收集统计信息。就收集统计信息而言,嵌套列中的每个字段都被视为单独的列。为避免对包含长值的列收集统计信息,您可以将delta.dataSkippingNumIndexedCols属性设置为使长值列位于该索引之后,或通过使用ALTER TABLE ALTER COLUMN将包含长字符串的列移动到大于delta.dataSkippingNumIndexedCols属性的索引位置。
Z-Ordering(多维聚类)
注意
此功能在Delta Lake 2.0.0及以上版本中可用。
Z-Ordering是一种技术,用于将相关信息集中存储在同一个文件集中。Delta Lake的数据跳过算法会自动利用这种共位性。这一特性显著减少了Apache Spark上的Delta Lake需要读取的数据量。要对数据进行Z-Order排序,您可以在ZORDER BY子句中指定排序列:
OPTIMIZE events ZORDER BY (eventType)
-- If you have a large amount of data and only want to optimize a subset of it, you can specify an optional partition predicate by using "where".
OPTIMIZE events WHERE date = '2021-11-18' ZORDER BY (eventType)
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, pathToTable) # path-based table
# For Hive metastore-based tables: deltaTable = DeltaTable.forName(spark, tableName)
deltaTable.optimize().executeZOrderBy(eventType)
# If you have a large amount of data and only want to optimize a subset of it, you can specify an optional partition predicate using `where`
deltaTable.optimize().where("date='2021-11-18'").executeZOrderBy(eventType)
import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, pathToTable) // path-based table
// For Hive metastore-based tables: val deltaTable = DeltaTable.forName(spark, tableName)
deltaTable.optimize().executeZOrderBy(eventType)
// If you have a large amount of data and only want to optimize a subset of it, you can specify an optional partition predicate by using "where".
deltaTable.optimize().where("date='2021-11-18'").executeZOrderBy(eventType)
关于Scala、Java和Python API语法详情,请参阅Delta Lake APIs
如果某列经常被用于查询谓词且该列具有高基数(即大量不同的值),则使用ZORDER BY。
您可以为ZORDER BY指定多个列作为逗号分隔的列表。然而,每增加一列,局部性效果就会降低。在没有收集统计信息的列上进行Z-Ordering是无效的,并且会浪费资源。这是因为数据跳过需要列级别的统计信息,如最小值、最大值和计数。您可以通过重新排序模式中的列来配置特定列的统计信息收集,或者增加要收集统计信息的列数。请参阅Data skipping。
注意
Z-Ordering不是幂等的。每次执行Z-Ordering时,它都会尝试在分区中的所有文件(新文件和之前参与过Z-Ordering的现有文件)中创建新的数据聚类。
Z-Ordering的目标是生成在元组数量上均衡的数据文件,但不一定保证磁盘上的数据大小均衡。这两个指标通常是相关的,但在某些情况下可能不一致,从而导致优化任务时间的倾斜。
例如,如果您使用
ZORDER BY按日期排序,而您最近的记录都比过去的记录宽得多(例如更长的数组或字符串值),那么预计OPTIMIZE作业的任务持续时间以及生成的文件大小都会出现倾斜。然而,这只是OPTIMIZE命令本身的问题;它不应该对后续查询产生任何负面影响。
多部分检查点
注意
此功能在Delta Lake 2.0.0及以上版本中可用。该功能目前处于实验性支持模式。
Delta Lake表会定期自动将所有增量更新压缩到Delta日志中的Parquet文件。这种"检查点"机制使得读取查询能够快速重建表的当前状态(即需要处理哪些文件、当前模式是什么),而无需读取包含增量更新的过多文件。
Delta Lake协议允许将检查点拆分为多个Parquet文件。这种并行处理方式可以加快检查点的写入速度。在Delta Lake中,默认情况下每个检查点都作为单个Parquet文件写入。要使用此功能,需设置SQL配置spark.databricks.delta.checkpoint.partSize=,其中n表示操作数量(例如AddFile)的限制阈值,当达到该阈值时,Apache Spark上的Delta Lake将开始并行化检查点,并尝试在每个检查点文件中最多写入该数量的操作。
注意
此功能无需在读取端进行任何配置更改。现有的读取器已经支持读取包含多个文件的检查点。
日志压缩
注意
此功能在Delta Lake 3.0.0及以上版本中可用。
Delta Lake协议允许使用[x, y]的聚合操作。日志压缩减少了对频繁检查点的需求,并最小化了由它们引起的延迟峰值。
Delta Lake 3.0.0及以上版本已支持日志压缩文件的读取功能。该功能默认启用,可通过SQL配置项spark.databricks.delta.deltaLog.minorCompaction.useForReads=进行禁用,其中value可设置为true/false。日志压缩的写入功能将在未来版本的Delta中实现。
优化写入
注意
此功能在 Delta Lake 3.1.0 及以上版本中可用。
优化写入操作可减少文件大小,从而提升后续对表的读取性能。
优化写入对分区表最为有效,因为它减少了写入每个分区的小文件数量。写入少量大文件比写入多个小文件效率更高,但由于数据在写入前需要重新洗牌,您可能仍会看到写入延迟增加。
下图展示了优化写入的工作原理:
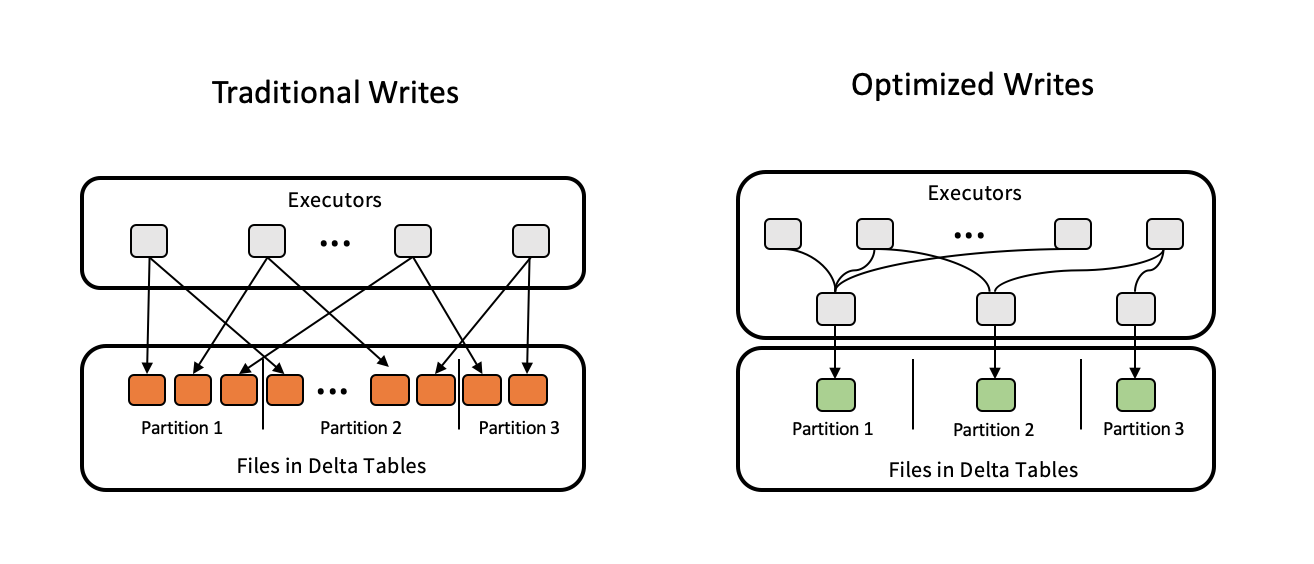
注意
您可能在写入数据之前运行了coalesce(n)或repartition(n)这样的代码来控制生成的文件数量。优化写入功能消除了对这种模式的需求。
默认情况下,优化写入功能处于禁用状态。可以通过以下设置(按优先级从低到高)在表级别、SQL会话级别和/或DataFrameWriter级别启用该功能:
表属性
delta.autoOptimize.optimizeWrite(默认值=None);SQL配置项
spark.databricks.delta.optimizeWrite.enabled(默认值=None);DataFrameWriter选项
optimizeWrite(默认值为None)。
除了上述内容外,还可以使用以下高级SQL配置来进一步微调写入文件的数量和大小:
spark.databricks.delta.optimizeWrite.binSize(默认=512MiB),用于控制每个输出文件的目标内存大小;spark.databricks.delta.optimizeWrite.numShuffleBlocks(默认值=50,000,000),用于控制"目标shuffle块的最大数量";spark.databricks.delta.optimizeWrite.maxShufflePartitions(默认值=2,000),用于控制"优化写入操作可使用的最大输出桶数(Reducer数量)"。