7.5 异构图内部机制
本章涵盖了分布式异构图的具体实现细节。在大多数情况下,这些对用户是透明的,但对于高级定制可能非常有用。
在DGL中,异构图中的节点或边在其自己的节点类型或边类型中具有唯一的ID。因此,DGL可以使用一个元组来识别一个节点或边:(node/edge type, type-wise ID)。我们将这种形式的ID称为异构ID。为了对异构图进行分布式训练的分区,DGL将其转换为同构图,以便我们可以重用为同构图设计的分区算法。因此,每个节点/边都被唯一地映射到一个连续ID范围内的整数ID(例如,从0到所有类型的节点总数)。我们将转换后的ID称为同构ID。
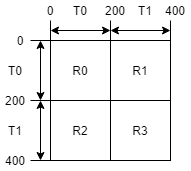
以下是ID转换过程的说明。这里,图有两种类型的节点(\(T0\) 和 \(T1\)),以及四种类型的边(\(R0\), \(R1\), \(R2\), \(R3\))。图中总共有400个节点,每种类型有200个节点。\(T0\) 的节点ID在[0,200)范围内,而\(T1\) 的节点ID在[200, 400)范围内。在这个例子中,如果我们使用一个元组来标识节点,\(T0\) 的节点被标识为(T0, 类型内ID),其中类型内ID在[0, 200)范围内;\(T1\) 的节点被标识为(T1, 类型内ID),其中类型内ID也在[0, 200)范围内。
ID转换工具
在预处理期间
并行处理管道的步骤都使用异构ID作为其输入和输出。然而,一些步骤如ParMETIS分区更容易使用同构ID实现,因此需要一个工具来执行ID转换。下面的代码使用分块图数据格式中的元数据JSON中的元数据信息实现了一个简单的IDConverter。它从某个节点类型\(A\)作为节点类型0开始,然后为其所有节点分配ID在范围\([0, |V_A|-1)\)内。然后它移动到下一个节点类型B作为节点类型1,并为其所有节点分配ID在范围\([|V_A|, |V_A|+|V_B|-1)\)内。
from bisect import bisect_left
import numpy as np
class IDConverter:
def __init__(self, meta):
# meta is the JSON object loaded from metadata.json
self.node_type = meta['node_type']
self.edge_type = meta['edge_type']
self.ntype2id_map = {ntype : i for i, ntype in enumerate(self.node_type)}
self.etype2id_map = {etype : i for i, etype in enumerate(self.edge_type)}
self.num_nodes = [sum(ns) for ns in meta['num_nodes_per_chunk']]
self.num_edges = [sum(ns) for ns in meta['num_edges_per_chunk']]
self.nid_offset = np.cumsum([0] + self.num_nodes)
self.eid_offset = np.cumsum([0] + self.num_edges)
def ntype2id(self, ntype):
"""From node type name to node type ID"""
return self.ntype2id_map[ntype]
def etype2id(self, etype):
"""From edge type name to edge type ID"""
return self.etype2id_map[etype]
def id2ntype(self, id):
"""From node type ID to node type name"""
return self.node_type[id]
def id2etype(self, id):
"""From edge type ID to edge type name"""
return self.edge_type[id]
def nid_het2hom(self, ntype, id):
"""From heterogeneous node ID to homogeneous node ID"""
tid = self.ntype2id(ntype)
if id < 0 or id >= self.num_nodes[tid]:
raise ValueError(f'Invalid node ID of type {ntype}. Must be within range [0, {self.num_nodes[tid]})')
return self.nid_offset[tid] + id
def nid_hom2het(self, id):
"""From heterogeneous node ID to homogeneous node ID"""
if id < 0 or id >= self.nid_offset[-1]:
raise ValueError(f'Invalid homogeneous node ID. Must be within range [0, self.nid_offset[-1])')
tid = bisect_left(self.nid_offset, id) - 1
# Return a pair (node_type, type_wise_id)
return self.id2ntype(tid), id - self.nid_offset[tid]
def eid_het2hom(self, etype, id):
"""From heterogeneous edge ID to homogeneous edge ID"""
tid = self.etype2id(etype)
if id < 0 or id >= self.num_edges[tid]:
raise ValueError(f'Invalid edge ID of type {etype}. Must be within range [0, {self.num_edges[tid]})')
return self.eid_offset[tid] + id
def eid_hom2het(self, id):
"""From heterogeneous edge ID to homogeneous edge ID"""
if id < 0 or id >= self.eid_offset[-1]:
raise ValueError(f'Invalid homogeneous edge ID. Must be within range [0, self.eid_offset[-1])')
tid = bisect_left(self.eid_offset, id) - 1
# Return a pair (edge_type, type_wise_id)
return self.id2etype(tid), id - self.eid_offset[tid]
分区加载后
在分区被加载到训练器或服务器进程后,加载的
GraphPartitionBook 提供了在同类ID和异类ID之间转换的工具。
map_to_per_ntype(): 将同质节点ID转换为类型ID和节点类型ID。map_to_per_etype(): 将同质边ID转换为类型ID和边类型ID。map_to_homo_nid(): 将类型ID和节点类型转换为同质节点ID。map_to_homo_eid(): 将类型ID和边类型转换为同质边ID。
因为所有DGL的低级分布式图采样操作符都使用同质ID,DGL在调用采样操作符之前,内部会将用户指定的异质ID转换为同质ID。下面展示了一个通过sample_neighbors()从类型为"paper"的节点中采样子图的例子。它首先执行ID转换,在获取采样子图后,将同质节点/边ID转换回异质ID。
gpb = g.get_partition_book()
# We need to map the type-wise node IDs to homogeneous IDs.
cur = gpb.map_to_homo_nid(seeds, 'paper')
# For a heterogeneous input graph, the returned frontier is stored in
# the homogeneous graph format.
frontier = dgl.distributed.sample_neighbors(g, cur, fanout, replace=False)
block = dgl.to_block(frontier, cur)
cur = block.srcdata[dgl.NID]
block.edata[dgl.EID] = frontier.edata[dgl.EID]
# Map the homogeneous edge Ids to their edge type.
block.edata[dgl.ETYPE], block.edata[dgl.EID] = gpb.map_to_per_etype(block.edata[dgl.EID])
# Map the homogeneous node Ids to their node types and per-type Ids.
block.srcdata[dgl.NTYPE], block.srcdata[dgl.NID] = gpb.map_to_per_ntype(block.srcdata[dgl.NID])
block.dstdata[dgl.NTYPE], block.dstdata[dgl.NID] = gpb.map_to_per_ntype(block.dstdata[dgl.NID])
请注意,从类型ID获取节点/边类型非常简单——只需从DistGraph的ntypes属性中获取它们,即g.ntypes[node_type_id]。
访问分布式图数据
DistGraph 类支持与 DGLGraph 类似的接口。下面展示了获取类型为 \(T0\) 的节点 0、10、20 的特征数据的示例。在访问 DistGraph 中的数据时,用户需要使用类型相关的 ID 和相应的节点类型或边类型。
import dgl
g = dgl.distributed.DistGraph('graph_name', part_config='data/graph_name.json')
feat = g.nodes['T0'].data['feat'][[0, 10, 20]]
用户可以为一个特定的节点类型或边类型创建分布式张量和分布式嵌入。分布式张量和嵌入被分割并存储在多个机器中。要创建一个,用户需要指定如何使用PartitionPolicy进行分区。默认情况下,DGL会根据第一个维度的大小选择合适的分区策略。然而,如果多个节点类型或边类型具有相同数量的节点或边,DGL无法自动确定分区策略。用户需要明确指定分区策略。下面展示了通过使用\(T0\)的分区策略为节点类型\(T0\)创建分布式张量并将其存储为\(T0\)的节点数据的示例。
g.nodes['T0'].data['feat1'] = dgl.distributed.DistTensor(
(g.num_nodes('T0'), 1), th.float32, 'feat1',
part_policy=g.get_node_partition_policy('T0'))
用于创建分布式张量和嵌入的分区策略在将异构图加载到图服务器时初始化。用户不能在运行时创建新的分区策略。因此,用户只能为节点类型或边类型创建分布式张量或嵌入。访问分布式张量和嵌入也需要类型特定的ID。