更多强化学习程序(自定义环境)¶
超级马里奥兄弟 & 超级马里奥兄弟2(失落的关卡) 在任天堂娱乐系统(NES)上是1980年代最受欢迎的游戏之一。如何设计一个基于深度强化学习(DRL)的人工智能来探索这个经典游戏呢?在本教程中,我们将在DI-engine中实现一个由人工智能驱动的马里奥(使用DQN算法)。
使用配置文件¶
DI-engine 使用一个全局配置文件来控制环境和策略的所有变量,每个变量都有相应的默认配置,可以在 mario_dqn_config 中找到,在本教程中我们直接使用默认配置:
from dizoo.mario.mario_dqn_config import main_config, create_config
from ding.config import compile_config
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
初始化环境¶
Super Mario Bros. 是一个图像输入的观察环境,因此我们不仅仅使用 DingEnvWrapper 来包装原始的 gym 环境,还需要添加一些额外的包装器来预处理观察结果,然后再将其发送到 DQN 策略。
在本教程中,我们使用以下5个包装器来预处理数据并将其转换为DI-engine的环境格式。这里有一些基本的描述,您可以找到完整的代码实现和注释这里
MaxAndSkipWrapper: 由于连续的帧变化不大,我们可以跳过n个中间帧来简化它,而不会丢失太多信息。
WarpFrameWrapper: 将原始的RGB图像转换为灰度图像,并将其调整为标准尺寸以用于DRL训练。
ScaledFloatFrameWrapper: 将原始图像从[0-255]归一化到[0-1],这对神经网络训练有益。
FrameStackWrapper: 堆叠连续的帧。由于我们无法从单个帧中推断出一些信息,如方向速度,堆叠的帧可以提供更多必要的信息。
EvalEpisodeReturnWrapper: 记录评估回合的回报(即马里奥中的回合回报),该功能已适配DI-engine的环境格式。
注意
如果找不到合适的环境包装器,你可以按照gym.Wrapper格式定义自己的包装器,或者根据自定义环境文档实现DI-engine环境格式的子类。
# use subprocess env manager to speed up collecting
from ding.envs import DingEnvWrapper, SubprocessEnvManagerV2
from ding.envs.env_wrappers import MaxAndSkipWrapper, WarpFrameWrapper, ScaledFloatFrameWrapper, FrameStackWrapper, \
EvalEpisodeReturnWrapper
import gym_super_mario_bros
from nes_py.wrappers import JoypadSpace
def wrapped_mario_env():
return DingEnvWrapper(
# Limit the action-space to 2 dim: 0. walk right, 1. jump right
JoypadSpace(gym_super_mario_bros.make("SuperMarioBros-1-1-v0"), [["right"], ["right", "A"]]),
cfg={
'env_wrapper': [
lambda env: MaxAndSkipWrapper(env, skip=4),
lambda env: WarpFrameWrapper(env, size=84),
lambda env: ScaledFloatFrameWrapper(env),
lambda env: FrameStackWrapper(env, n_frames=4),
lambda env: EvalEpisodeReturnWrapper(env),
]
}
)
collector_env_num, evaluator_env_num = cfg.env.collector_env_num, cfg.env.evaluator_env_num
collector_env = SubprocessEnvManagerV2(
env_fn=[wrapped_mario_env for _ in range(collector_env_num)], cfg=cfg.env.manager
)
evaluator_env = SubprocessEnvManagerV2(
env_fn=[wrapped_mario_env for _ in range(evaluator_env_num)], cfg=cfg.env.manager
)
注意
以下部分与CartPole + DQN示例相同,只需选择策略并打包整个训练流程。
选择策略¶
DI-engine 涵盖了大多数强化学习策略,使用它们只需要选择正确的策略和模型。 由于 DQN 是离策略的,我们还需要实例化一个缓冲区模块。
from ding.model import DQN
from ding.policy import DQNPolicy
from ding.data import DequeBuffer
model = DQN(**cfg.policy.model)
buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)
policy = DQNPolicy(cfg.policy, model=model)
构建管道¶
通过DI-engine提供的各种中间件,我们可以轻松构建整个管道:
from ding.framework import task
from ding.framework.context import OnlineRLContext
from ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, eps_greedy_handler, CkptSaver, nstep_reward_enhancer
with task.start(async_mode=False, ctx=OnlineRLContext()):
# Evaluating, we place it on the first place to get the score of the random model as a benchmark value
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(eps_greedy_handler(cfg)) # Decay probability of explore-exploit
task.use(StepCollector(cfg, policy.collect_mode, collector_env)) # Collect environmental data
task.use(nstep_reward_enhancer(cfg)) # Prepare nstep reward for training
task.use(data_pusher(cfg, buffer_)) # Push data to buffer
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_)) # Train the model
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100)) # Save the model
# In the evaluation process, if the model is found to have exceeded the convergence value, it will end early here
task.run()
运行代码¶
完整示例可以在mario DQN 示例中找到,并且可以通过python3 mario_dqn_example.py运行。
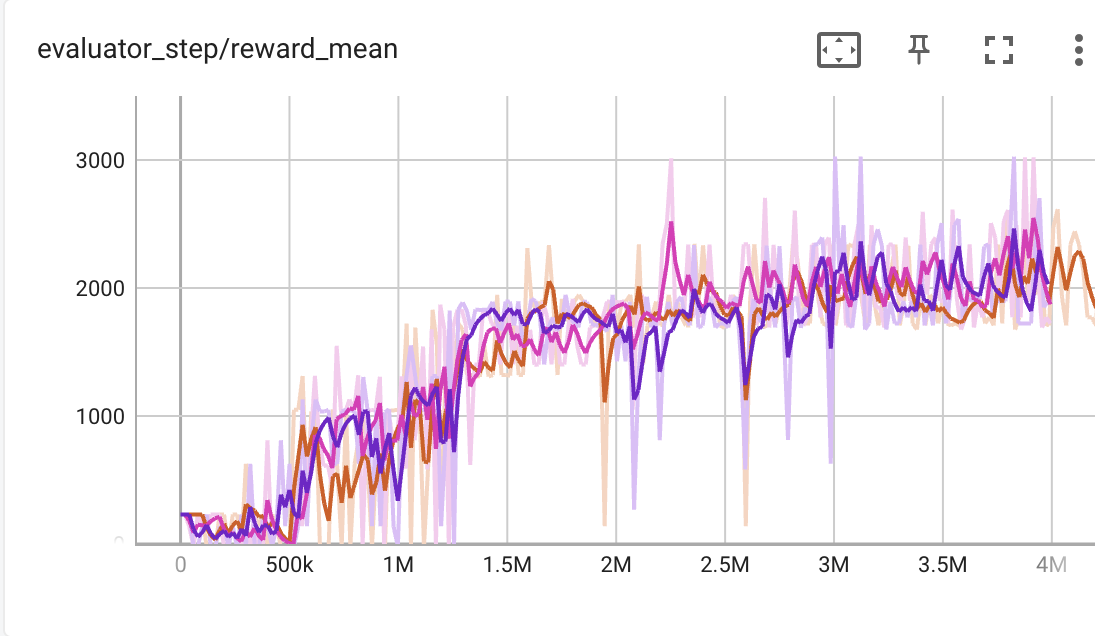
这个演示可以在几个小时内得出成功的结果,我们的超级马里奥可以尽快通过1-1关卡而不受任何伤害,以下是训练后的代理回放视频和详细的训练曲线(评估回合回报/环境交互步骤)。
现在你已经完成了使用DI-engine的自定义环境示例,你可以在示例目录中尝试更多算法,或者继续阅读文档以更深入地了解DI-engine的算法、系统设计和最佳实践。