分布式强化学习¶
问题定义和研究动机¶
分布式强化学习(Distributed RL)是深度强化学习应用于大规模应用并解决复杂决策空间和长期规划问题的唯一途径。为了解决像《星际争霸2》(SC2)[1]和《DOTA2》[2]这样的超大规模决策问题,单个进程甚至单台机器的计算能力远远不够,必须扩展计算和存储设备的每一个部分。研究人员希望设计一套完整的“算法+系统”解决方案,使DRL训练程序能够在各种计算规模下高效运行,并在确保算法优化收敛的同时尽可能提高每个环节的效率。
一般来说,强化学习训练程序有三种核心模块:
生成数据的环境(Env),
生成动作的Actor,
学习者使用这些数据进行训练,每个数据都需要不同数量和类型的计算资源支持。
附注:包含环境和参与者的模块通常被称为收集器。
根据算法和环境的不同,会添加一些扩展的辅助模块。例如,大多数离策略算法需要一个数据队列(Replay Buffer)来存储训练数据;对于基于模型的RL算法,会有相关的训练模块用于学习环境的动态;对于需要大量自我对弈的算法,需要一个集中式的协调器(Coordinator)来控制和协调每个组件(例如动态地与游戏的双方进行通信)。
从系统的角度来看,有必要为整个训练程序中的类似模块提供足够的并行可扩展性。例如,可以根据资源的可用性增加交互环境的数量(利用更多的CPU),或者根据并行设备的数量增加训练端的吞吐量(通常,拥有更多的GPU)。对于不同的模块,希望所有模块尽可能异步执行,并减少模块时间中各种通信方式(网络通信、数据库、文件系统)的成本。但总的来说,当Learner能够高效地持续训练而不需要等待时,系统的效率优化的理论上限就达到了;也就是说,当Learner高效地完成一次训练迭代时,下一次训练迭代的数据已经可用。
从算法的角度来看,希望在确保算法收敛的同时,减少算法对数据吞吐量的要求(例如容忍更旧和更多离策略的数据),并提高数据探索的效率和收集数据的利用率(例如,修改数据采样方法,或结合一些与RL中数据效率相关的研究)。从而为系统设计提供更多的空间和可能性。
总之,分布式强化学习是一个更全面的研究子领域,它需要深度强化学习算法与分布式系统设计的相互感知和协调。
研究方向¶
系统¶
总体架构¶
对于常见的决策问题,最常用的两种分布式架构是IMPALA [3] 和 SEED RL [4]。
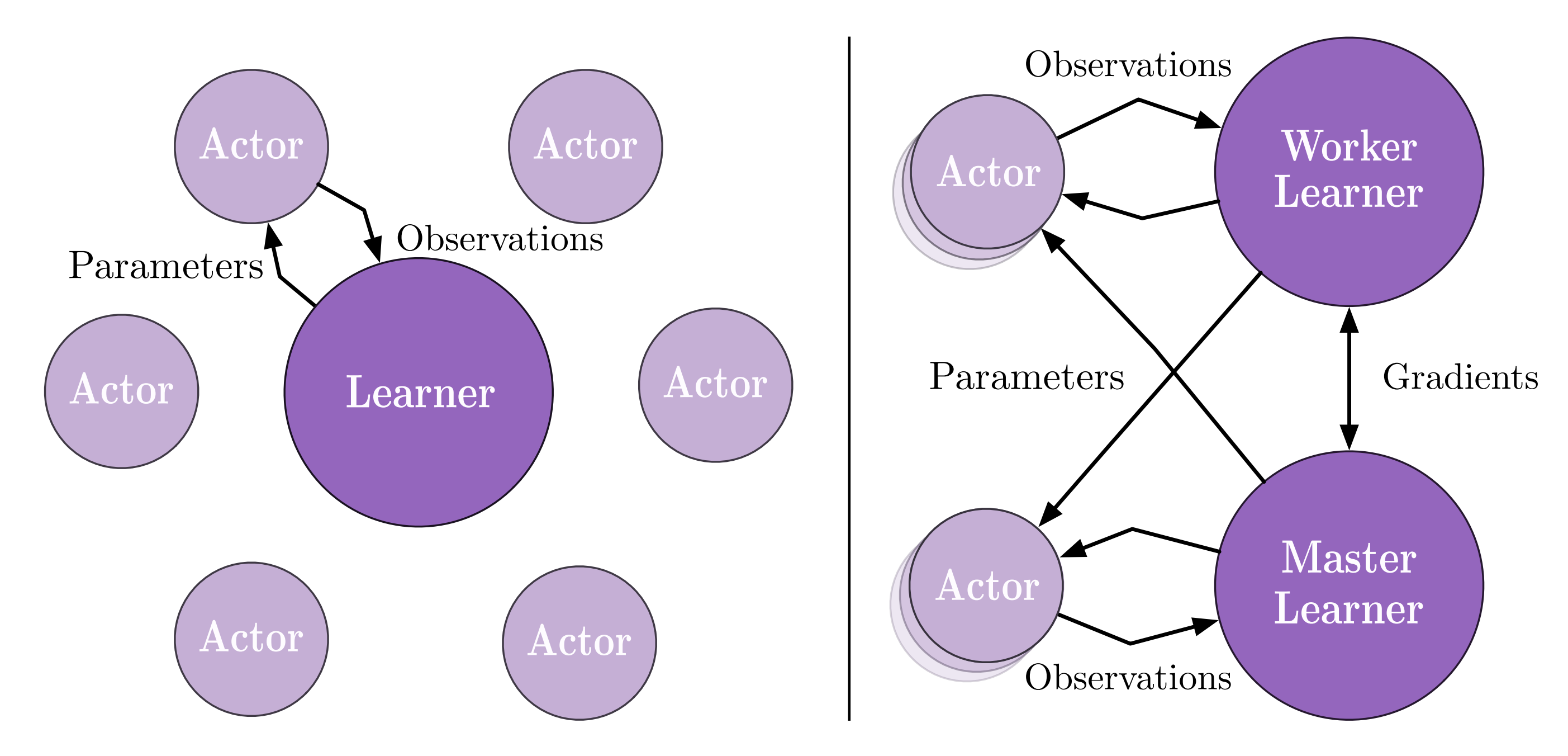
前者是经典的Actor-Learner模式;也就是说,数据收集和训练是完全分开的,最新的神经网络模型会定期从Learner传递给Actor,而Actor收集的数据在收集到一定数量的数据帧(即观察结果)后会发送给Learner。如果有多个Learner,它们也会定期同步它们的梯度以更新神经网络(即分布式深度学习中的数据并行模型)。
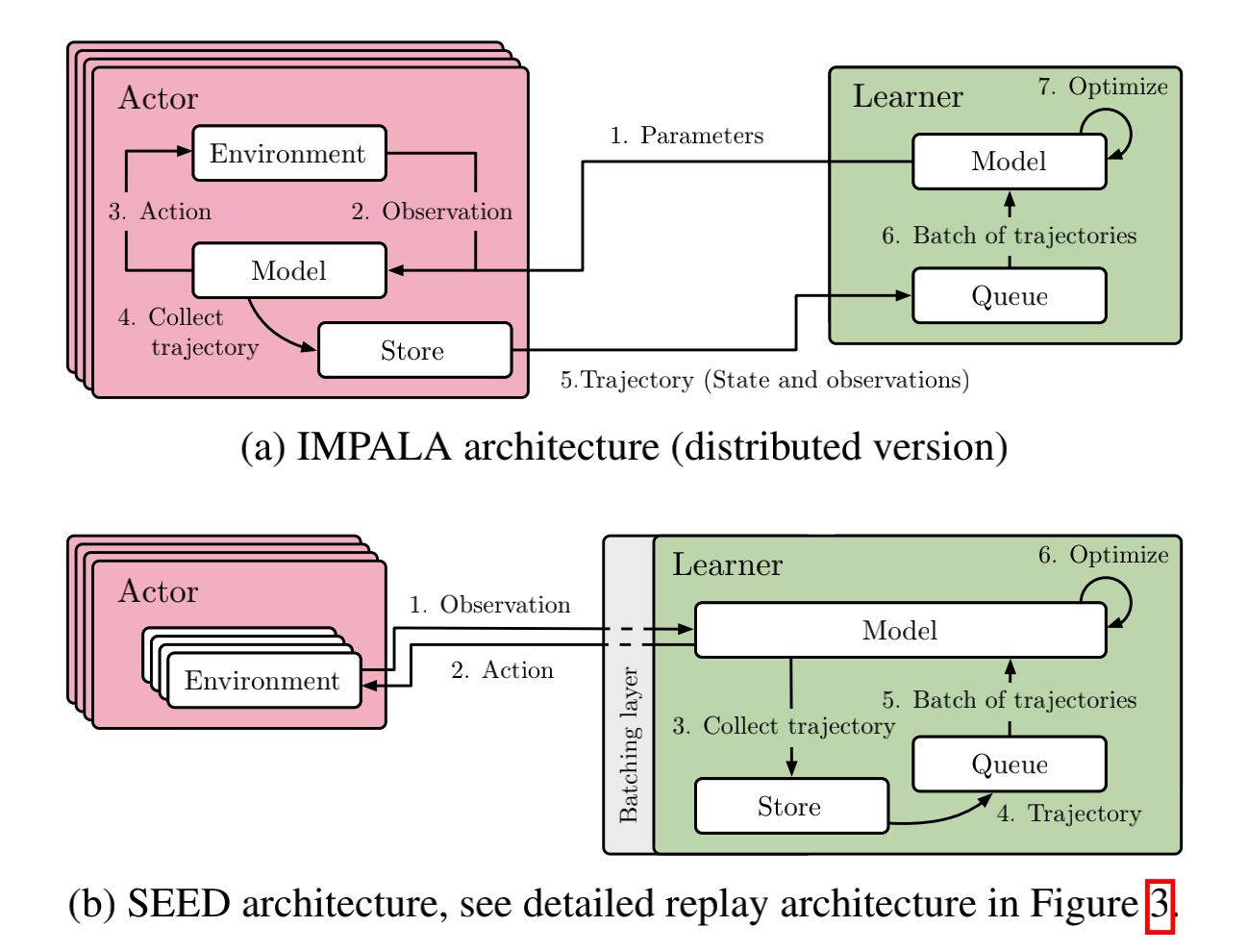
在前者的基础上,后者致力于优化传输模型参数的损失。SEED RL剥离了用于推理生成动作的部分,并将其与训练端放在一起,通过高效的TPU间通信技术更新模型参数。IMPALA中传递模型参数的成本大大降低,对于环境和推理Actor之间的跨机器通信,SEED RL使用了优化的gRPC方案来传递观察和动作,因此没有太大的负担。
注意
这两种方案之间没有绝对的优劣之分。如果跨机器传输模型的成本较高,并且GPU/TPU之间有更好的通信组件,那么SEED RL可能是更合适的选择。否则,如果跨机器传输观察和动作数据的成本较高,那么IMPALA是更稳定的选择。此外,IMPALA可以累积一批数据进行数据传输,而SEED RL需要在每个交互帧中进行数据传输。这是一个经典的数据批处理和流处理对比问题。对于当前的机器学习社区来说,前者通常更友好。此外,如果整个训练过程需要更高的自由度和定制化,例如动态控制Actor的某些行为,IMPALA更为方便。
除了上述两种架构外,还有许多其他分布式强化学习设计方案,例如引入了异步神经网络更新方案的A3C [5] 和 Gossip A2C [6]。为了支持大规模自对弈,设计了具有复杂联盟机制的AlphaStar [1],而结合了基于模型的RL和MCTS相关模块的MuZero [7] 将不在此处描述。感兴趣的读者可以参考具体的论文或参阅我们的算法攻略合集部分。
某些子主题/模块/目标的效率优化¶
除了整体结构的设计和创新外,在整个训练程序中还有许多优化单点模块的方法。它们主要是针对某个子问题进行定制和优化的。以下是一些主要的方法:
Object Store在 Ray/RLLib [8] 中:用于在多个进程和多台机器之间传输数据,Ray/RLLib 中的 Object Store 提供了一种非常方便和高效的方式。只要任何进程知道一个对象的引用,它就可以请求 Store 提供它。提供相应的值,具体的内部数据传输完全由 Store 管理,这样分布式训练程序可以像编写本地单进程程序一样实现。Object Store 的具体实现是通过结合 redis、plasma 和 gRPC 完成的。Sample Factory[9]: Sample Factory 在单机规模上定制和优化了 APPO 算法,精心设计了环境与动作生成策略之间的异步方案,并使用共享内存大大提高了模块之间的传输效率。Reverb在 Acme [10] 中:Reverb 提供了一套高度灵活且高效的数据操作和管理模块。对于强化学习(RL),它非常适合实现回放缓冲区相关的组件。envpool[11]: envpool 是目前最快的环境向量化并行解决方案,使用 C++ 线程池和许多经典 RL 环境的高效实现,提供强大的异步向量化环境模拟能力。
算法¶
降低数据生成算法的吞吐量要求¶
V-trace在 IMPALA [3] 中:离策略算法可以扩大可用于训练的数据范围,从而在一定程度上提高算法对旧数据的容忍度,并减少由收集器生成的数据的吞吐压力,但过于离策略的数据很容易影响算法的收敛性。针对这个问题,IMPALA 使用重要性采样机制和相应的裁剪方法,在分布式训练设置下设计了一个相对稳定的算法方案 V-trace,限制了离策略数据对优化本身的负面影响。Reuse和Staleness在 OpenAI FIVE [2] 中:在 OpenAI 为 DOTA2 设计的代理中,他们对数据重用的次数和数据的陈旧程度进行了一些实验。过多的重用次数和过于陈旧的数据会影响大规模训练中 PPO 算法的稳定性。
提高数据探索效率 + 收集数据的利用效率¶
Data Priority and Diversity——Ape-x [12]: Ape-x 是一种经典的分布式强化学习方案。其核心实践之一是使用优先级经验回放来设置具有优先级偏好的不同样本数据,使算法更加关注那些“重要”的轨迹。此外,Ape-x 还在不同的并行收集器中设置不同的探索参数(即 eps greedy 的 epsilon),以提高数据的多样性。Representation Learning在RL中的应用——CURL [13]: 对于一些高维或多模态的输入,可以结合表示学习方法来提高RL的数据利用效率。例如,对于高维图像输入的控制问题,CURL引入了额外的对比学习过程,RL基于学习到的特征空间进行决策。从系统设计的角度来看,表示学习与强化学习训练的结合也有很大的优化空间,例如两者的异步性。Model-based/MCTS RL——MuZero [7]: MuZero 结合了基于模型的强化学习和MCTS强化学习,以提高整体训练效率,其中包括许多独特的模块,例如MCTS的搜索过程、训练前数据的重新分析过程等,这将导致更加复杂和多样化的分布式强化学习训练系统。
未来研究¶
目前,分布式强化学习只是一个新兴的研究子领域。在许多情况下,它受到计算能力和问题复杂性的限制。仍有许多问题需要解决:
缺乏统一的基准来评估分布式强化学习算法和系统的效率;
目前,大多数分布式强化学习解决方案仅适用于一小部分环境和部分RL算法,技术的通用化还有很长的路要走;
当前系统优化和RL算法本身仍然是孤立的,可以考虑感知RL优化需求的系统设计,例如动态资源感知和调度。