基于模型的强化学习¶
基于模型的强化学习(Model-Based RL)是强化学习的一个重要分支。智能体通过与环境的交互学习一个动态模型,然后使用该模型生成数据以优化策略或使用该模型进行规划。 基于模型的强化学习方法首先从与环境交互获得的数据中学习一个动态模型,然后使用该动态模型生成大量模拟样本。这样,与真实环境的交互次数将减少,换句话说,样本效率可以大大提高。
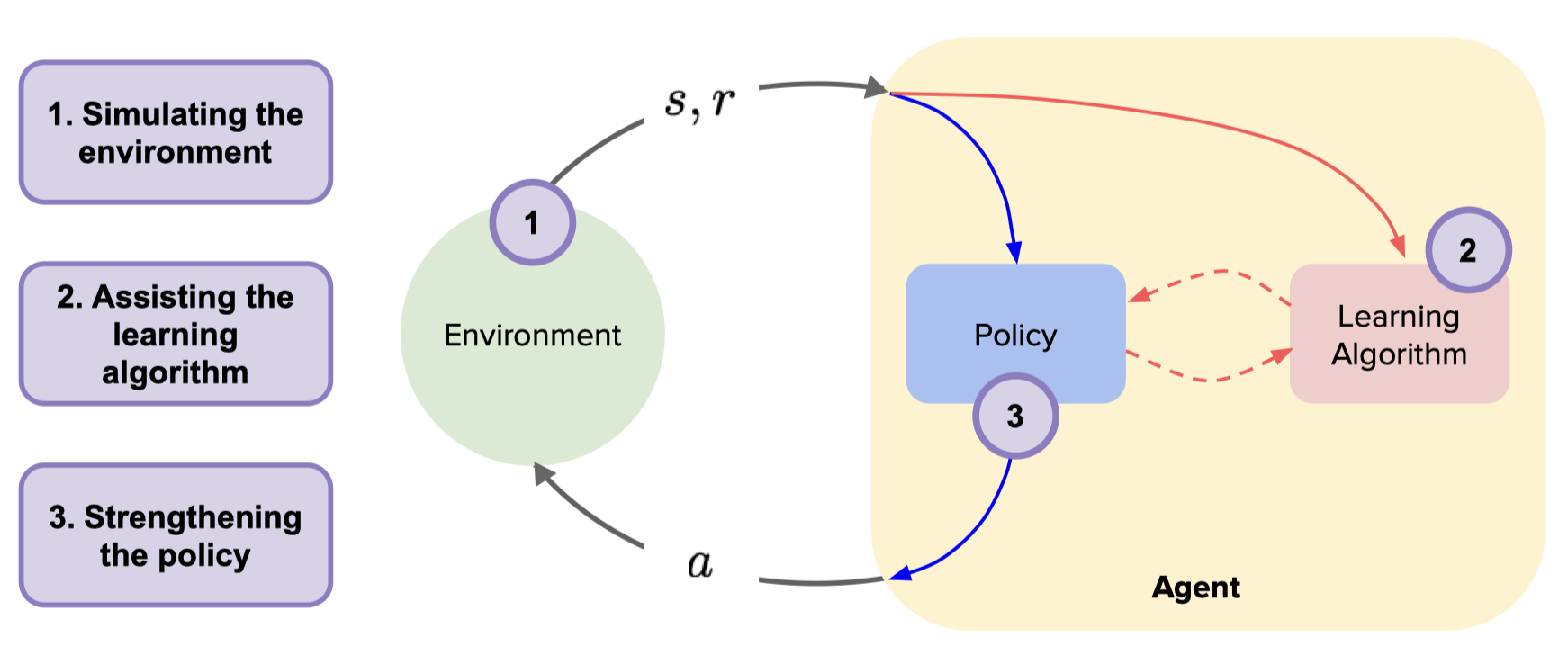
环境模型通常可以抽象为数学上的状态转移函数和奖励函数。 在理想情况下,智能体在学习完动态模型后不再需要与真实环境交互。智能体现在可以查询动态模型以生成模拟样本,通过这些样本可以最大化累积折扣奖励,从而获得最优策略。
问题定义和研究动机¶
通常,基于模型的强化学习研究问题可以分为两类:如何学习一个准确的动态模型,以及如何使用动态模型进行策略优化。
如何构建一个准确的环境模型?
模型学习主要强调通过基于模型的强化学习算法构建环境模型的过程。例如,
World Model [3] 提出了一个基于无监督学习的环境模型,并使用该模型将任务从模拟转移到现实。
但是基于模型的强化学习在模型学习部分也存在几个问题,例如,
动态模型中会出现错误,随着代理与动态模型之间的迭代交互,模型引起的错误会随着时间的推移而累积,使得算法难以收敛到最优解。
环境模型缺乏通用性,每次问题改变时,模型都必须重新建模。
如何使用环境模型进行策略优化?
模型利用主要强调基于模型的强化学习算法使用动态模型来辅助策略学习,例如基于模型的规划或基于模型的策略学习。
研究方向¶
近年来,基于模型的强化学习(Model-Based RL)的论文已经在awesome-model-based-RL [1]中进行了整理和总结。 最经典的基于模型的强化学习算法之一是Dyna风格的强化学习,这是一种结合了基于模型的强化学习和无模型强化学习的算法。 除了经典的Dyna风格的强化学习外,基于模型的强化学习大致还有以下几类:
基于模型的规划算法
基于模型的价值扩展强化学习
策略优化结合模型梯度回传
基于模型的规划算法¶
在学习环境动态模型后,模型可以直接用于规划。此时,强化学习可以转化为一个最优控制问题:可以通过规划算法获得最优策略,规划算法也可以用于生成更好的样本来辅助学习。 这类算法中最常见的是交叉熵方法(CEM)。其思想是假设动作序列服从某种先验分布,采样动作以获得轨迹,并选择好的轨迹来后验更新先验分布。
基于模型的规划算法在每次迭代中大致分为三个步骤:
在第一步中,执行操作后,根据环境动态模型预测下一个状态。
第二步是使用诸如CEM之类的算法来解决动作序列。
在第三步中,执行在第二步中解决的第一个操作,依此类推。
这种类型的典型算法是RS [9], PETS [10], POPLIN [7]。 然而,当解决高维控制任务时,规划的难度和所需的计算量将显著增加,规划效果也会变差,因此它适用于动作维度较低的简单模型。
基于模型的价值扩展强化学习¶
基于模型的规划算法每次输入一个状态,并需要重新规划以获取输出动作,而训练好的策略直接将状态映射到动作,训练好的策略在实际应用中比规划算法更快。 在基于模型和无模型的组合模式中,模型误差会降低整个算法的性能。 MVE [11] 通过使用环境模型展开生成固定数量的H步轨迹来进行基于模型的价值扩展,从而估计价值函数。 因此,Q值的估计结合了基于环境动力学模型的短期预测和基于目标Q值网络的长期预测。步数H限制了复合误差的累积,并提高了Q值的准确性。
STEVE [12] 指出,MVE需要依赖于调整rollout的步数H,即在复杂环境中,如果模型中的步数过大,会引入较大的误差,而在简单环境中,如果步数过小,则会降低Q值的估计精度。 因此,STEVE在不同环境中部署不同的具体步数,计算每一步的不确定性,动态调整并整合不同步数之间的Q值权重,使得每个环境任务下的Q值预测更加准确。
结合模型梯度回传的策略优化¶
除了使用模型的虚拟扩展来生成数据外,如果模型是神经网络或其他可微分函数,还可以利用模型的可微分特性直接辅助策略的学习。这种方法进一步利用了模型。
SVG [13] 使用真实样本来拟合模型,并通过利用模型的可微性来优化价值函数,即使用链式法则和模型的可微性直接推导出价值函数,并使用梯度上升法来优化价值函数并学习策略。 在优化过程中仅使用真实样本,而不使用模型生成虚拟数据。 这样做的优点是可以减轻模型不准确的影响,但同时由于不使用模型生成虚拟数据,样本效率并未得到显著提高。
除了使用模型的梯度外,MAAC [14] 使用H步自举的Q值函数作为强化学习的目标函数。同时,回放缓冲区中的数据包括与真实环境交互的数据和模型虚拟扩展的数据。超参数H可以使目标函数在模型的准确性和Q值函数的准确性之间进行权衡。使用模型的可微性通过反向传播计算梯度可能会遇到深度学习中存在的一类问题,即梯度消失和梯度爆炸。MAAC中使用终端Q函数来缓解这个问题。SVG [13] 和 Dreamer [15] 使用梯度裁剪技巧来实现。此外,使用模型的可微性在梯度优化过程中也可能陷入局部最优问题。[2]
未来研究¶
基于模型的强化学习具有较高的样本效率,但环境模型的训练过程通常耗时较长,因此“如何提高模型的学习效率”是非常必要的。
此外,由于环境模型的通用性不足,通常每次问题变化时都需要重新建模。为了解决不同任务之间模型通用性的问题,“如何将迁移学习和元学习的思想和技术引入基于模型的强化学习”也是一个非常重要的研究问题。
基于模型的强化学习在高维图像观测上的建模和决策,以及基于模型的强化学习与离线强化学习的结合,将是未来强化学习引领Sim2Real的充分条件。