多智能体强化学习¶
问题定义和研究动机¶
在许多现实世界的场景中,人们需要控制同时存在的多个代理来完成特定任务,例如交通控制、机器人协作、自动驾驶和多人在线游戏。因此,强化学习的研究逐渐从单代理领域扩展到多代理强化学习(MARL)。近年来,深度强化学习在多代理环境和游戏中显示出巨大潜力,例如《星际争霸II》的子环境SMAC [7],足球游戏Gfootball,以及自动驾驶环境如Carla。

在多智能体强化学习(MARL)中,策略控制多个智能体同时与环境交互,目标仍然是最大化累积奖励。在这种情况下,环境的状态转移函数和奖励函数取决于所有智能体的联合行动,而不是单个智能体的单一行动。因此,在策略学习过程中,每个智能体的策略更新需要考虑其他智能体的当前策略。
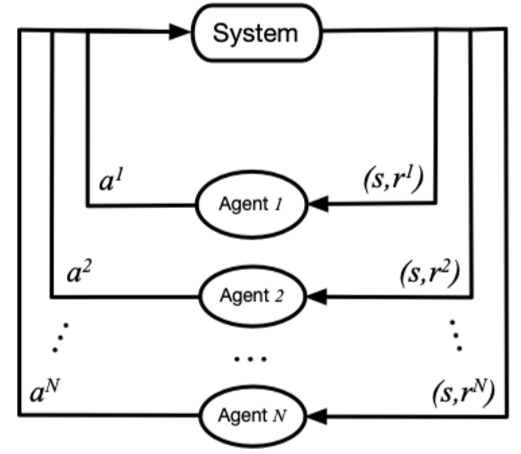
在图1中,\(system\) 表示一个多智能体环境,\(Agent_i\) 表示第i个智能体,\(a_i\) 表示第i个智能体采取的动作,\(r_i\) 表示第i个智能体获得的局部奖励。 在训练过程中,每个智能体分别与环境交互,系统反馈一个联合奖励。
一般来说,多智能体强化学习与单智能体强化学习的主要区别在于以下四点:
环境的非平稳性:当代理做出决策时,其他代理也在采取行动,环境状态的变化与所有代理的联合行动有关。因此,单个代理行动的价值评估会随着其他代理的行动而变化,这将导致MARL训练中的非平稳性。
代理信息获取的限制:在某些环境(如SMAC)中,每个代理可能无法获取全局状态信息,而只能获取局部观察信息。然而,无法知道其他代理的观察信息、动作和其他信息。
个体目标一致性:每个代理的目标可能是最优的全局回报或最优的局部回报。
可扩展性:大规模多代理系统可能涉及高维状态空间和动作空间,这对实际场景中的模型表达能力、算法学习能力和硬件计算能力提出了一定的挑战。
研究方向¶
对于MARL合作任务,最简单的想法是直接将单智能体强化学习方法应用于多智能体系统。具体来说,每个智能体将其他智能体视为环境的一部分,然后利用单智能体强化学习范式。这是独立Q学习、独立PPO的基本思想,但由于环境的非平稳性和智能体观察的局部性,这些方法难以取得良好的效果。
目前,MARL中的合作任务主要采用CTDE范式(集中训练和分散执行),主要包括两种类型的学习方法,基于价值的MARL和Actor-Critic MARL。详情请参见图2:
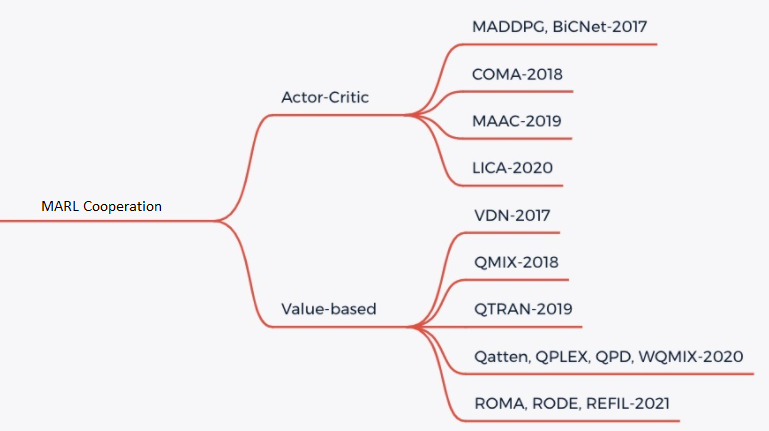
基于价值的MARL
对于基于价值的MARL,主要思想是将联合动作值函数\(Q_tot\)分解为个体动作值函数\(Q_a\),以实现分散执行。为了实现CTDE,我们需要确保分解满足IGM假设:在\(Q_tot\)上执行的全局argmax操作与在每个\(Q_a\)上执行的一组个体argmax操作产生相同的结果。主要有QMIX、WQMIX、QTRAN等方法:
QMIX: QMIX的核心是学习一个单调的Q值混合网络,每个智能体的Q值通过非线性变换求和生成\(Q_tot\)。详情请参阅QMIX [2]
WQMIX: WQMIX的核心与QMIX相同,它也学习一个Q值混合网络,但它通过加权投影方法学习一个可以突破单调性限制的Q值混合网络。详情请参阅WQMIX [1]
QTRAN: QTRAN通过独立学习动作值网络、混合动作值网络和全局状态值网络,突破了单调性限制。详情请参阅QTRAN [4]
QPLEX: QPLEX 使用 Dueling 结构分别分解联合 Q 值 \(Q_tot\) 和每个代理的 Q 值 \(Q_i\)。IGM 一致性被转换为易于实现的优势函数值范围约束,这有助于学习具有线性分解结构的值函数。详情请参阅 QPLEX [8]
演员-评论家多智能体强化学习
对于Actor-Critic MARL,主要思想是使用策略梯度定理来更新策略网络,同时学习一个完全集中的状态-动作值函数,并用它来指导分散策略的优化。
未来研究¶
对于一些具有更多代理和更复杂环境的环境,例如Multi-Agent Petting Zoo的一些子环境,有近一百个代理,纯MARL合作可能无法取得良好效果,这需要代理之间进行实时通信以共享信息。
对于一些实际情况,如自动驾驶,获取实时全局状态所需的带宽压力过大,特别是在车辆数量较多时,几乎不可能获取实时全局状态,因此无法使用CTDE方法进行训练。
在上述情况1和2中,可以使用多智能体之间的MARL通信方法来进一步提高学习效率。
在未来,MARL可以与离线RL技术结合,以进一步提高样本效率。同时,MARL也可以应用于许多领域,如代理行为分析、代理建模、人机协作等。