离线强化学习¶
问题定义和动机¶
离线强化学习(RL),也称为批量强化学习,是RL的一种变体,它有效地利用先前收集的大规模数据集进行大规模现实世界应用。 使用静态数据集意味着在代理的训练过程中,离线RL不执行任何形式的在线交互和探索,这也是与在线强化学习方法最显著的区别。 为了方便起见,我们在以下部分中将非离线强化学习,包括策略上和策略下RL,统称为在线强化学习(Online RL)。
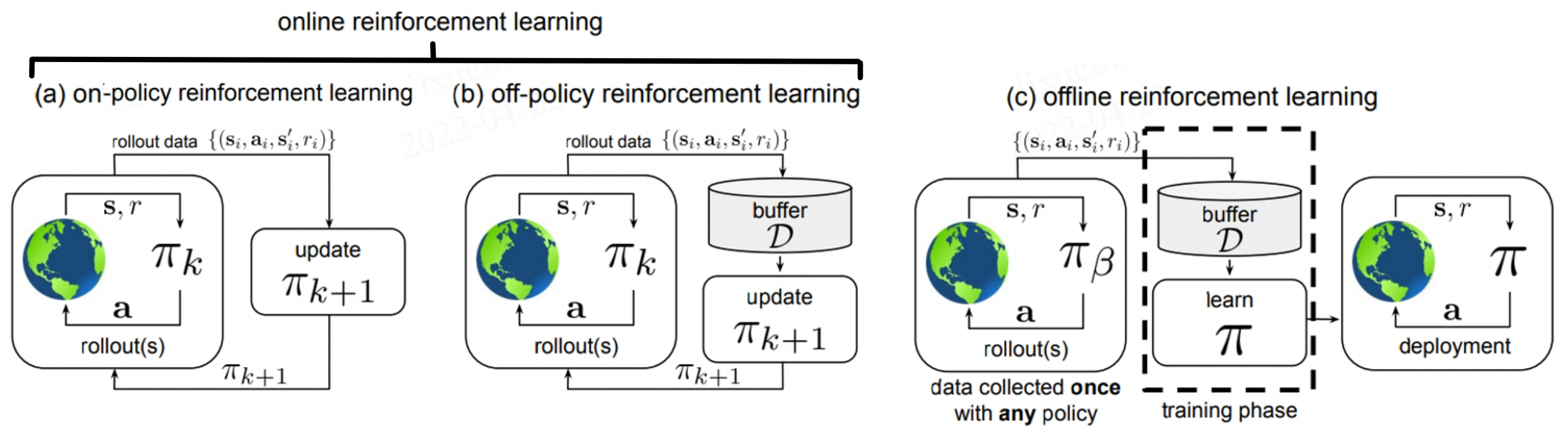
在图中,(a) 代表在线策略强化学习(On-policy RL),其中代理使用当前策略 \(\pi_k\) 与环境交互。只有由当前学习策略生成的数据才能用于更新网络。 (b) 描述了离线策略强化学习(Off-policy RL),它在与环境交互时将历史策略的所有数据存储在经验缓冲区 \(\mathcal{D}\) 中。换句话说,\(\mathcal {D}\) 包含使用策略 \(\pi_0, \pi_1, ..., \pi_k\) 收集的数据,所有这些数据都将用于更新网络 \(\pi_{k+ 1}\)。 对于 (c) 中的离线强化学习(Offline RL),数据集 \(\mathcal{D}\) 是从某些(可能未知的)行为策略 \(\pi_{\beta}\) 预先收集的,并且在训练过程中不会改变。训练过程完全不与 MDP 交互,策略只有在完全训练后才会部署。
为什么要研究离线强化学习?
离线强化学习最近成为一个热门研究课题,原因可以归结为两个方面:
第一个是离线强化学习本身的优势。深度强化学习在游戏等模拟任务中取得了巨大成功,通过有效地与环境互动,我们可以获得表现出色的代理。 然而,在现实世界的任务中,探索环境并收集大规模数据进行重复训练通常成本太高。特别是在自动驾驶和机器人操作等环境中,这可能很危险。 相比之下,离线强化学习研究如何从固定数据集中学习最优策略,这可以显著减轻潜在的风险和成本,因为它不需要任何额外的探索。
此外,过去十年机器学习方法的成功很大程度上归功于可扩展的数据驱动学习方法的出现,这些方法使用更多的数据来获得更好的训练结果。与在线强化学习相比,充分利用大规模静态数据集也是离线强化学习的一个重要优势。
离线强化学习训练
离线强化学习禁止在训练期间进行任何形式的交互和探索。 在这种设置下,我们利用静态数据集 \(\mathcal{D}\) 来训练代理,该数据集由某些行为策略 \(\pi_{\beta}(\mathbf{a}\mid \mathbf{s})\) 收集。 给定 \(\mathcal{D} = \left\{ (\mathbf{s}, \mathbf{a}, r, \mathbf{s}^{\prime})\right\}\),值迭代和策略优化过程可以表示为:
其中策略 \(\hat{\pi} \left(\mathbf{a} \mid \mathbf{s}\right)\) 的贝尔曼算子 \(\hat{\mathcal{B}}^\pi\) 是 \(\hat{\mathcal{B}}^\pi \hat{Q}\left(\mathbf{s}, \mathbf{a}\right) = \mathbb{E}_{\mathbf{s}, \mathbf{a}, \mathbf{s}^{\prime} \sim \mathcal{D}}[ r(\mathbf{s}, \mathbf{a})+\gamma \mathbb{E}_{\mathbf{a}^{\prime} \sim \hat{\pi}^{k}\left(\mathbf{a}^{\prime} \mid \mathbf{s}^{\prime}\right)}\left[\hat{Q}^{k}\left(\mathbf{s}^{\prime}, \mathbf{a}^{\prime}\right)\right] ]\).
离线强化学习 VS 模仿学习
离线强化学习与模仿学习(IL)密切相关,因为后者也是从固定数据集中学习而无需探索。然而,两者之间存在几个关键差异:
到目前为止,离线强化学习算法都是建立在标准的离策略深度强化学习(Deep RL)算法之上的,这些算法倾向于优化某种形式的贝尔曼方程或TD差分误差。
大多数IL问题假设存在一个最优的或至少是高性能的演示者来提供数据,而离线RL可能不得不处理非常次优的数据。
大多数IL问题没有奖励函数。离线RL考虑奖励,这些奖励可以在事后处理并修改。
一些IL问题需要将数据标记为专家与非专家,而离线RL不做此假设。
离线强化学习 VS 离策略强化学习
离策略强化学习通常指的是一类强化学习算法,这些算法允许与环境交互以生成训练样本的策略与当前要更新的策略不同。 基于Q学习的算法、利用Q函数的Actor-Critic算法以及许多基于模型的强化学习算法都属于这一类。 然而,离策略强化学习在学习过程中仍然经常使用额外的交互(即在线数据收集)。
将在线强化学习算法应用于离线设置的障碍
许多先前的研究工作表明,在线强化学习算法在离线RL场景中表现不佳。 在论文[6]中,作者指出这是因为策略倾向于选择分布外的动作(out-of-distribution, OOD)。 只有当待估计数据的分布遵循训练数据的分布时,Q函数的估计才是准确的。 这种关系如下图所示:
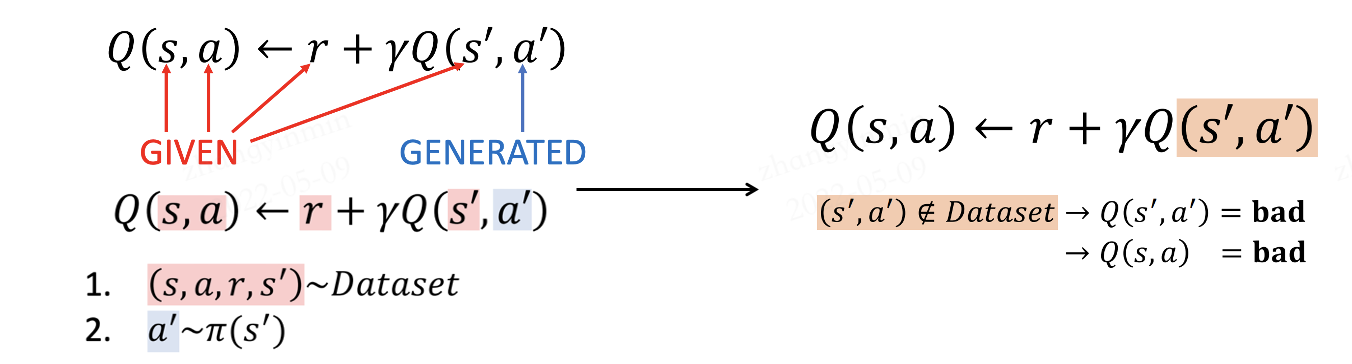
当代理进行在线探索时,数据集和策略都会更新。 策略的马尔可夫静态状态分布和数据集中的实际状态分布始终相同(在线策略设置)或至少相似(离线策略设置)。 然而,在离线场景中,与原始数据集相比,会出现分布偏移。 在期望奖励最大化过程中,如果Q函数高估了未见的\((\mathbf{s}, \mathbf{a})\)对,可能会选择回报低的动作,导致性能不佳。
主要研究方向¶
根据Aviral Kumar和Sergey Levine在NeurIPS 2020教程[1]中的介绍,无模型离线强化学习可以分为以下三类:
策略约束方法
基于不确定性的方法
值正则化方法
此外,还有一些关于离线设置中基于模型的强化学习的工作,这里将不进行讨论。感兴趣的读者可以参考[7] [8]和其他文档。关于离线强化学习的整体发展路线图,可以参考[9]中的概览图:

策略约束方法
这种方法旨在使学习到的策略\(\pi(\mathbf{a} \mid \mathbf{s})\)与行为策略\(\pi_{\beta}(\mathbf{a} \mid \mathbf{s})\)保持足够接近,从而确保精确的Q估计。上述两种策略之间的距离可以表示为\(\mathbf{D}(\pi, \pi_{\beta})\)。在显式约束中,距离被限制为小于特定值\(\mathcal{C}\)。
还存在一些隐式约束,例如策略重建,模仿行为策略 \(\pi_{\beta}(\mathbf{a} \mid \mathbf{s})\) 并带有一定程度的扰动。 在BCQ [2] 中,研究人员提出训练一个生成模型(VAE)来模拟数据集中的动作。 在更新过程中,策略从VAE扰动生成的动作中选择具有最高Q值的动作,从而确保所选动作与数据集中的动作相似。 基于BCQ,使用TD3作为网络结构,从而推导出TD3BC算法。详情请参阅 [3]。
此外,距离\(\mathbf{D}(\pi, \pi_{\beta})\)可以被视为添加到目标或奖励函数中的惩罚项。
基于不确定性的方法
除了直接约束策略外,我们还可以通过有效的不确定性估计,使Q函数对此类查询具有弹性,从而减轻分布外行为的影响。 这种方法需要学习一个不确定性集合或分布\(\mathcal{P}(\mathbf{Q}^{\pi})\)。详细信息请参见[4] [5]。然后我们可以设计一个惩罚项\(\mathcal{P}(\mathbf{Q}^{\pi})\)添加到Q函数中。
其中 \(\mathbf{Unc}(\cdot)\) 表示不确定性的度量,减去它可以提供实际Q函数的保守估计。
值正则化方法
在CQL [6]中,正则化项被插入到目标函数中。这种方法可能具有吸引力,原因有几个,例如适用于演员-评论家和Q学习方法,即使策略没有明确表示,也避免了行为策略的显式建模需求。
与基于不确定性的方法类似,CQL旨在推导出一个保守的Q估计。
其中贝尔曼误差 \(\mathcal{E}(\mathcal{B}, \mathcal{\phi})\) 是经典DQN中的目标,而 \(\mathcal{C}(\mathcal{B}, \mathcal{\phi})\) 表示额外的保守惩罚项。 对 \(\mathcal{C}(\mathcal{B}, \mathcal{\phi})\) 的不同选择会导致具有不同特性的算法。
效果是保守的惩罚会在某些分布 \(\mu(\mathbf{a} \mid \mathbf{s})\) 下压低高Q值。对于 \(\mu(\mathbf{a} \mid \mathbf{s})\) 的一个简单且实用的选择是:
意义在于,根据当前数据最大化预期折现回报的策略。因此,如果惩罚权重\(\alpha\)选择得当,保守惩罚应该主要降低分布外动作的Q值,因为分布内动作将被贝尔曼误差\(\mathcal{E}(\mathcal{B}, \mathcal{\phi})\)“锚定”。
如果 \(\mathcal{C}_{CQL_0}(\mathcal{B}, \mathbf{\phi})\) 在 Q 估计上过于保守,我们可以选择
未来展望¶
传统的离策略强化学习算法通常专注于可以利用离策略数据的动态规划方法。然而,当涉及到完全离线的条件时,这些方法都面临困难。最近,一些改进的离线强化学习方法被提出,这些方法通过策略约束、不确定性估计或价值正则化来考虑分布偏移的统计特性。一般来说,这些方法揭示了离线强化学习实际上是一个反事实推理问题:给定由一组决策产生的数据,推断另一组决策的后果。在传统的机器学习中,我们通常假设训练和测试数据是独立同分布的(i.i.d.)。但离线强化学习放弃了这一假设,这极具挑战性。为了实现这一点,需要新的创新来实施复杂的统计方法,并将其与在线强化学习中的序列决策基础相结合。解决分布偏移、约束动作分布和评估分布下限等方法在当前离线强化研究水平上都有可能取得突破。
在机器学习中,过去十年左右的许多惊人成就很大程度上可以归功于数据驱动的学习范式。在计算机视觉和自然语言处理领域,尽管架构和模型的改进带来了快速的性能提升,尤其是在实际应用中,数据集的规模和多样性的增加仍然是进步的重要驱动力。离线强化学习提供了将强化学习——传统上被视为一种根本性的主动学习范式——转变为数据驱动学科的可能性。然而,在大多数在线强化学习方法的标准设置中,收集大规模且多样化的数据集通常是不切实际的。在许多应用中,如自动驾驶和人机交互,风险和成本是巨大的。因此,我们期待在未来见证新一代的数据驱动强化学习。它不仅能够解决一系列以前无法解决的实际问题,还能充分利用现有应用(如驾驶、机器人等)中更大、更多样化、更具表现力的数据集。