安全强化学习¶
问题定义和研究动机¶
安全强化学习是强化学习的一个细分发展方向。强化学习的目标是学习一个最大化预期回报的策略,但在现实世界的决策问题中,如自动驾驶和机器人场景,部署这种仅最大化预期回报的智能体往往会引发安全问题。
在强化学习训练过程中,通常会出现以下安全问题 [[1]]:
负面副作用
奖励黑客
可扩展监督
安全探索
对分布变化的鲁棒性
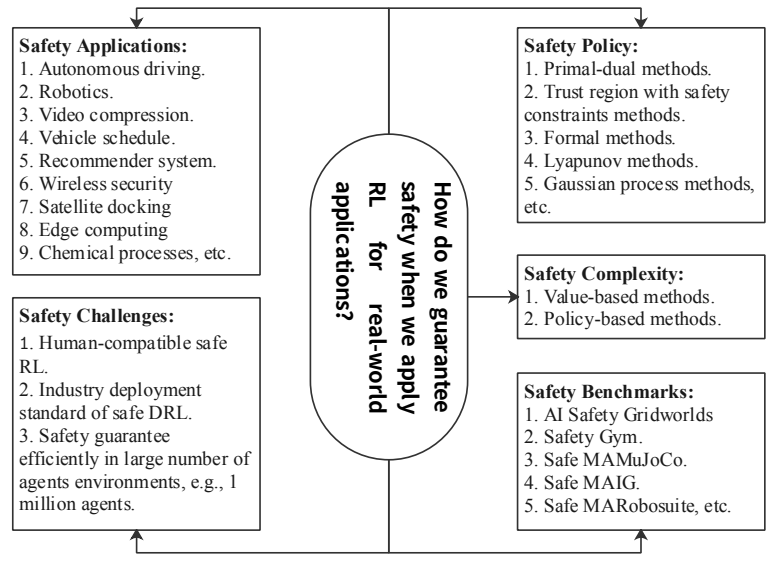
由于这些问题的存在,在实际部署时考虑安全条件是非常必要的。在定义安全强化学习时,有五个关键问题[[2]]:
安全策略。如何优化策略并找到安全策略?
安全复杂性。需要多少训练数据才能找到一个安全的策略?
安全应用。安全强化学习应用的最新发展是什么?
安全基准。我们可以使用哪些基准来公平且全面地检查安全强化学习的性能?
安全挑战。未来的安全强化学习研究将面临哪些挑战?
从统一的角度概述这五个安全强化学习问题的框架如下所示 [[2]]。
安全强化学习通常被建模为约束马尔可夫决策过程(CMDP)。约束马尔可夫决策过程是马尔可夫决策过程(MDP)的扩展,由七个元组\((S, A, P, r, c, b, \mu)\)组成,分别表示状态空间、动作空间、状态转移函数、奖励、成本、成本阈值和折扣因子。代理采取行动后,不仅会收到奖励r,还会收到成本c。策略目标是在不超过成本阈值b的约束下最大化长期奖励:
\(\max_{\pi}\mathbb{E}_{\tau\sim\pi}\big[R(\tau)\big],\quad s.t.\quad\mathbb{E}_{\tau\sim\pi}\big[C(\tau)\big]\leq\kappa.\)

上图是OpenAI发布的safety-gym环境。传统强化学习训练出的最优策略通常以任务为中心,不考虑对环境和自身的影响,是否符合人类期望等。汽车(红色)将以最快速度移动到目标位置(绿色圆柱体),而不会避开地面上的陷阱区域(蓝色圆圈)。如果移动路径上有障碍物(青色立方体),它会被撞开或被迫离开。
方向¶
安全强化学习的理论基础主要是与对偶方法和凸优化相关的知识。主要的理论方法可以分为:
原始对偶。使用拉格朗日乘数法转换为求解对偶问题。
原始问题。使用其他方法来解决原始问题。
训练方案可以分为:
无模型。
基于模型的。
有关当前安全强化学习领域中算法的详细分类,请参见下图(引用自omnisafe):

原始对偶¶
在原始的安全RL问题中,目标和约束都不是凸的,但可以使用拉格朗日乘数法将其转换为对偶问题。对偶问题是一个最小化凸问题,可以解决。这个解决方案有许多经典的工作[[3-7]]。
拉格朗日函数: \(\mathcal{L}(\pi,\lambda)=V(\pi)+\Sigma\lambda_i(U_i(\pi)-c_i),\lambda\geq0\)
拉格朗日对偶函数: \(d(\lambda)=\max_{\pi\in\mathcal{P}(\mathcal{S})}\mathcal{L}(\pi,\lambda)\)
最小化对偶函数:\(D^*=\min_{\lambda\in\mathbb{R}_+}d(\lambda)\) 将获得对偶问题的最优解。
原始¶
尽管使用对偶化方案确保了问题的可解性,但训练迭代的速度非常慢。在优化策略函数的同时,还必须优化对偶函数。同时,选择拉格朗日乘数并不容易。因此,一些方法并不直接专注于解决整个原始问题,而是使用自然策略梯度中的单步更新公式:

在每次更新步骤中解决一个相对简单的单步约束优化问题,以确保每次更新不违反约束并提高性能。自然地,最终将获得一个满足约束的解决方案。代表性的方法是PCPO等。
无模型¶
约束策略优化(CPO) [[3]] 是第一个解决CMDP问题的策略梯度方法。通过优化以下两个方程,您可以确保在满足安全约束的同时,回报单调增加。
\(J\left(\pi'\right)-J(\pi)\geq\frac{1}{1-\gamma}\underset{\stackrel{s\sim d\pi}{a\sim\pi'}}{\operatorname*{E}}\left[A^{\pi}(s,a)-\frac{2\gamma\epsilon^{\pi'}}{1-\gamma}D_{TV}\left(\pi'\|\pi\right)[s]\right]\)
\(J_{C_{i}}\left(\pi^{\prime}\right)-J_{C_{i}}\left(\pi\right)\leq\frac{1}{1-\gamma}\underset{\overset{s\sim d^{\pi}}{a\sim\pi^{\prime}}}{\operatorname*{E}}\left[A_{C_{i}}^{\pi}\left(s,a\right)+\frac{2\gamma\epsilon_{C_{i}}^{\pi^{\prime}}}{1-\gamma}D_{TV}\left(\pi^{\prime}\|\pi\right)\left[s\right]\right]\)
这种方法几乎收敛到安全边界,并且在某些任务上比原始对偶方法表现更好。然而,CPO在计算上比拉格朗日乘数法更昂贵,因为它需要计算费舍尔信息矩阵并使用二次泰勒展开来优化目标。
基于模型的¶
基于模型的深度强化学习(DRL)方法通常比无模型的DRL方法具有更好的学习效率,这在安全强化学习领域也是如此。但在现实生活中,构建准确的环境模型是具有挑战性的,许多模拟环境难以构建模型来辅助深度强化学习方法的部署。
未来研究¶
当我们在现实世界的应用中利用强化学习时,部署过程中会遇到许多挑战。安全强化学习是一个尚未发展很长时间的方向,有许多方面需要探索[[8, 9, 10]_]。例如:
使用博弈论实现安全的多智能体强化学习。在不同的游戏设置中可以考虑不同的游戏,以应用于现实世界。
基于信息论的安全强化学习。信息论可能有助于处理不确定的奖励信号和成本估计,并有效解决大规模多智能体环境中的问题。
利用人脑理论和生物理论。从生物学规律中汲取一些灵感,设计安全的强化学习算法。
人机交互。从与非专家用户的互动中学习,模拟人类行为和现实互动,使机器人能够安全地继承人类偏好,并从人类那里了解更多潜在的解决方案。