分布式¶
使用事件系统¶
在我们开始分布式运行之前,让我们先介绍一下DI-engine的事件系统,所有远程调用都会使用它。
事件系统是一种异步编程范式,其优点在于解耦不同逻辑的代码,提高可读性,并且由于异步执行,提高了资源利用率。事件系统也有一些缺点,因为异步调用可能会使调试更加困难,我们将在稍后的代码规范中描述一些避免这些缺点的方法。
任务对象提供了五个与事件系统相关的方法——emit、on、off、once、wait_for——我们将重点介绍emit和on方法。所有其他方法都源自这两个方法。
with task.start(async_mode=False, ctx=OnlineRLContext()):
task.on("greeting", lambda msg: print("Get msg: %s" % msg))
task.emit("greeting", "Hi")
# >>> Get msg: Hi
以上是事件系统的一个简单示例,通过task.on为greeting事件注册一个回调方法,通过task.emit触发事件并发送msg参数。参数的数量是可变的,只要emit和on回调函数的参数对应即可。接下来,我们将这两行代码拆分为单独的代码片段(以中间件形式编写),它们也可以如下工作。
def receiver():
# Since `on` is a permanent callback, we only need to register it once.
# If you only want to call back once, you can use `once`.
task.on("greeting", lambda msg: print("Get msg: %s" % msg))
def _receiver(ctx):
pass
return _receiver
def sender():
def _sender(ctx):
task.exit("greeting", "Hi %s times" % ctx.total_step)
return _sender
with task.start(async_mode=False, ctx=OnlineRLContext()):
task.use(receiver())
task.use(sender())
task.run(10)
这段代码将在一个进程中发送和接收问候事件十次,让我们看看如何在不同的进程中使用它们。
并行化¶
Parallel 模块是 DI-engine 中的一个并行模块,它可以让你的主函数在多个进程中运行。它内部集成了一个消息中间件,与任务的事件系统一起,允许你在进程之间传递信息而无需感知它。

当使用Parallel执行代码时,任务的内部事件系统将自动将消息路由到连接的进程。这允许您使用来自其他进程的事件和数据,就像在本地使用事件系统一样。
def main():
with task.start(async_mode=False, ctx=OnlineRLContext()):
if task.router.node_id == 0: # 1
task.on("greeting", lambda msg: print("Get msg: %s" % msg))
else:
task.emit("greeting", "Hi") # 2
sleep(10) # 3
if __name__ == "__main__":
Parallel.runner(n_parallel_workers=2)(main) # 4
注意
你可以通过
task.router对象访问Parallel实例,以获取当前进程的编号node_id,这样你就可以在不同的进程中执行不同的函数逻辑。你可以通过
only_local和only_remote参数来控制谁发送数据,这些参数属于task.emit,默认情况下会广播给所有进程。由于
task的with statement在退出时会清除所有已注册的事件,我们在示例中使用sleep来防止任务过早退出。您可以在API文档中查看
Parallel的其他参数,以选择更多的网络模式,包括网状连接、星型连接、使用redis作为消息中间件等。
在Kubernetes上部署¶
我们将分布式操作等同于多进程操作,因此无需在代码中进行任何更改即可从单机环境扩展到多机环境。然而,我们更倾向于使用kubernetes进行DI-engine部署,以更好地利用任务管理和资源隔离技术。
为了能够一键在kubernetes上运行,我们推荐使用DI-engine提供的命令行工具ditask,而不是直接从python脚本启动应用程序。ditask支持Parallel模块的所有参数,您只需在代码中完成主函数即可通过ditask启动应用程序。
ditask --package my_module --main my_module.main --parallel-workers 2
使用ditask,您可以在单台机器上启动多个进程。当我们使用kubernetes启动多个pod时,需要通过环境变量将所有pod的IP地址暴露给每个进程。为此,我们提供了一个特殊的kubernetes任务类型,称为DIJob,以自动配置这些环境变量。
您可以通过DI-orchestrator安装DIJob。安装完成后,以下模板可以帮助您快速在kubernetes上部署DI-engine。
apiVersion: diengine.opendilab.org/v2alpha1
kind: DIJob
metadata:
name: test
spec:
minReplicas: 3
maxReplicas: 3
template:
spec:
containers:
- name: di-container
image: opendilab/ding:latest
imagePullPolicy: Always
env:
- name: PYTHONUNBUFFERED
value: "1"
resources:
requests:
cpu: 6
memory: "10Gi"
limits:
cpu: 6
memory: "10Gi"
command: ["/bin/bash", "-c",]
args:
- |
ditask --package my_module --main my_module.main --parallel-workers 2
注意
上述模板将启动6个DI-engine进程(3个pod,每个pod两个进程)
工作者 & 任务 & 容器 & 任务 & 节点 & …¶
由于DI-engine支持独立部署、k8s和slurm部署,而k8s和slurm本身具有类似节点和任务的概念,这里有一些解释以避免混淆。
def main():
with task.start(async_mode=False, ctx=OnlineRLContext()):
if task.router.is_active: # In distributed mode
if task.router.node_id == 0:
... # Use learner middlewares
elif task.router.node_id == 1:
... # Use evaluator middlewares
else:
... # Use collector middlewares
task.run()
if __name__ == "__main__":
main()
上述代码通过不同的node_id将任务划分为1个learner + 1个evaluator + N个collector(完整代码请参见dqn.py)。其中node_id是ditask中的工作节点数量,标记为0到N。假设我们将工作节点数量设置为4,上述代码将按照learner、evaluator和2个collector的顺序划分为四个进程。
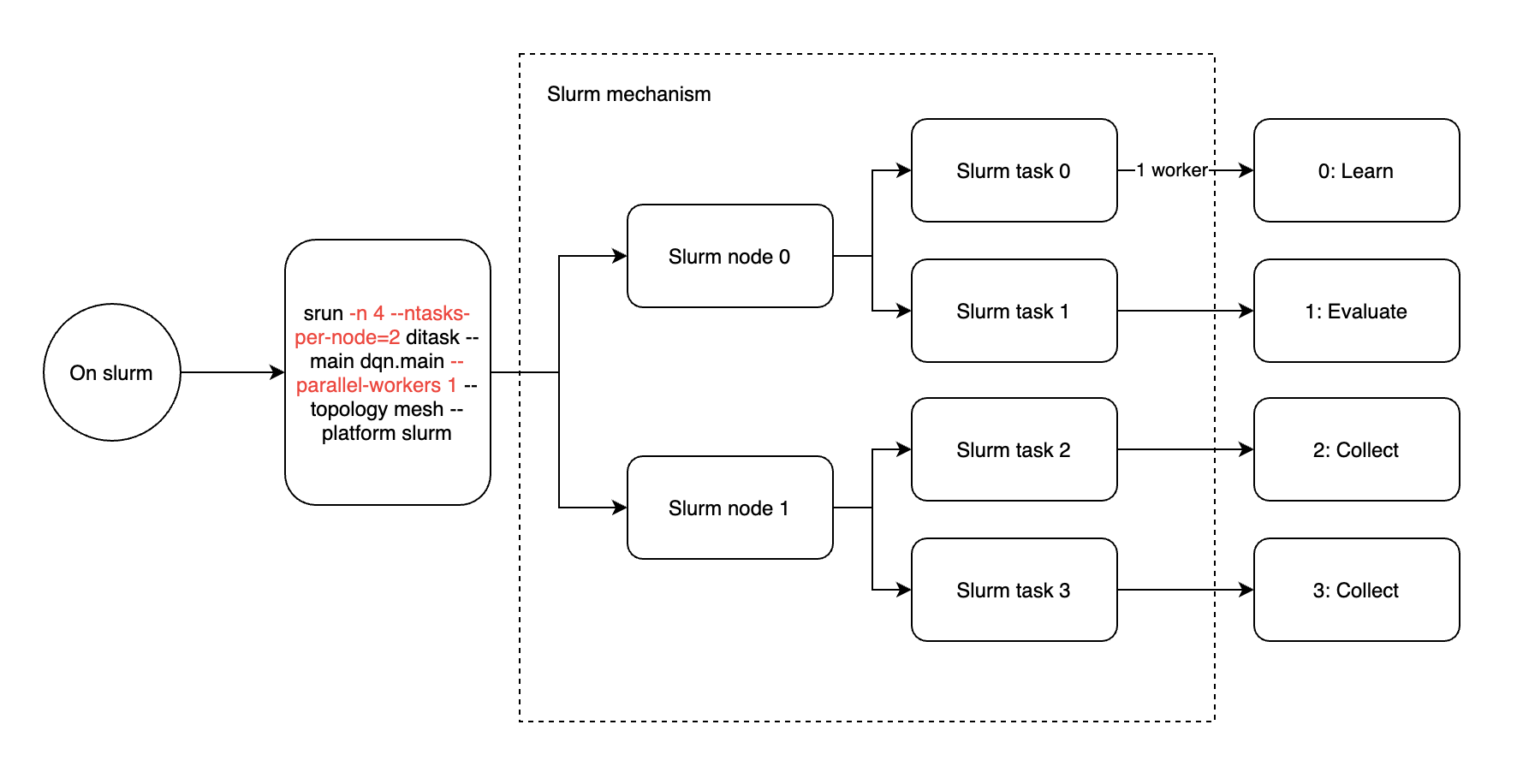
Slurm集群引入了节点和任务两个概念。节点代表集群节点,对应物理机器,每个节点可以分配多个任务,这些任务对应进程。因此,在Slurm中运行ditask时,建议每个ditask只启用一个工作器(ditask参数–parallel-workers 1),并且Slurm任务的数量等于4(srun参数-n 4)。
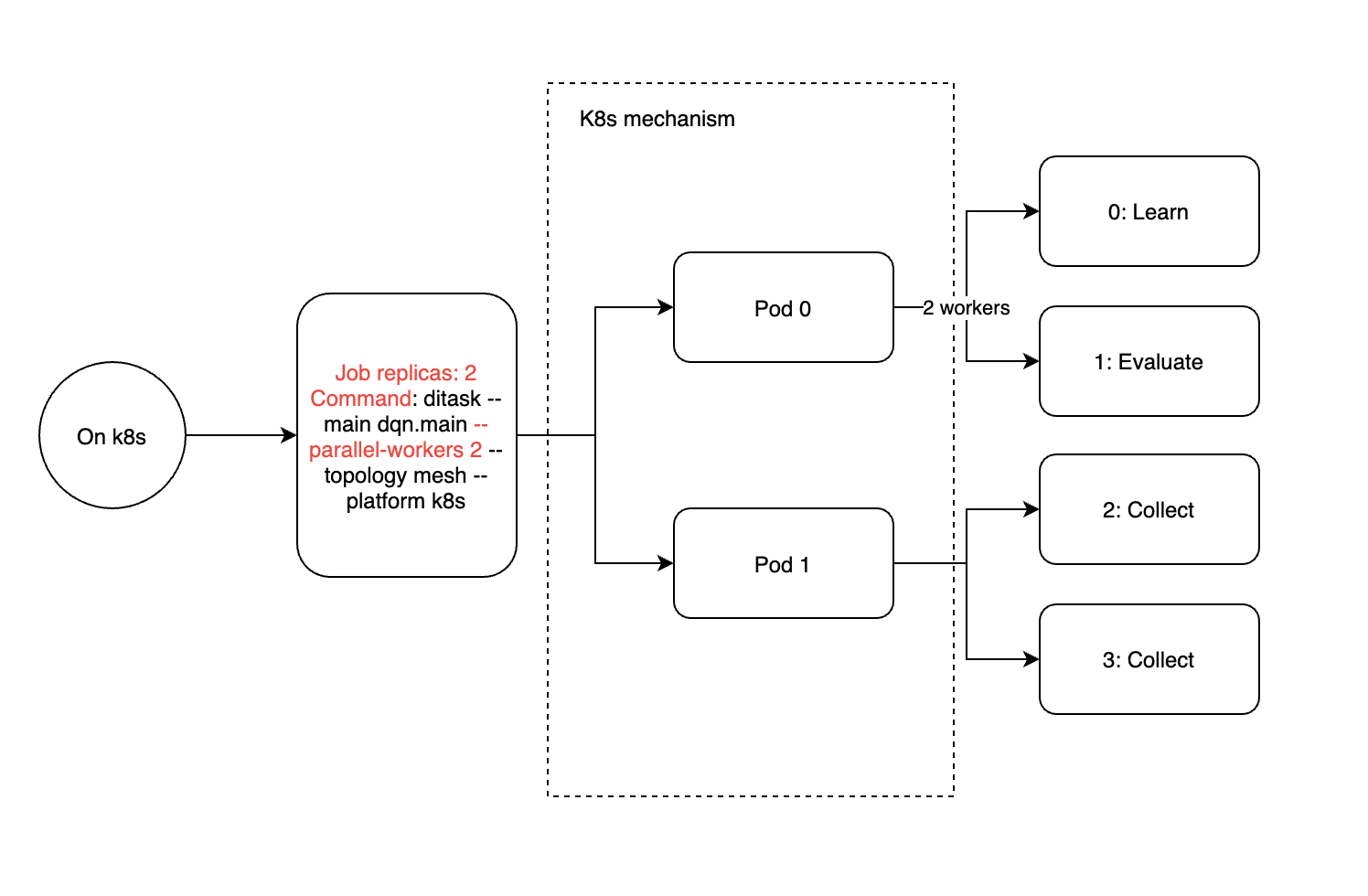
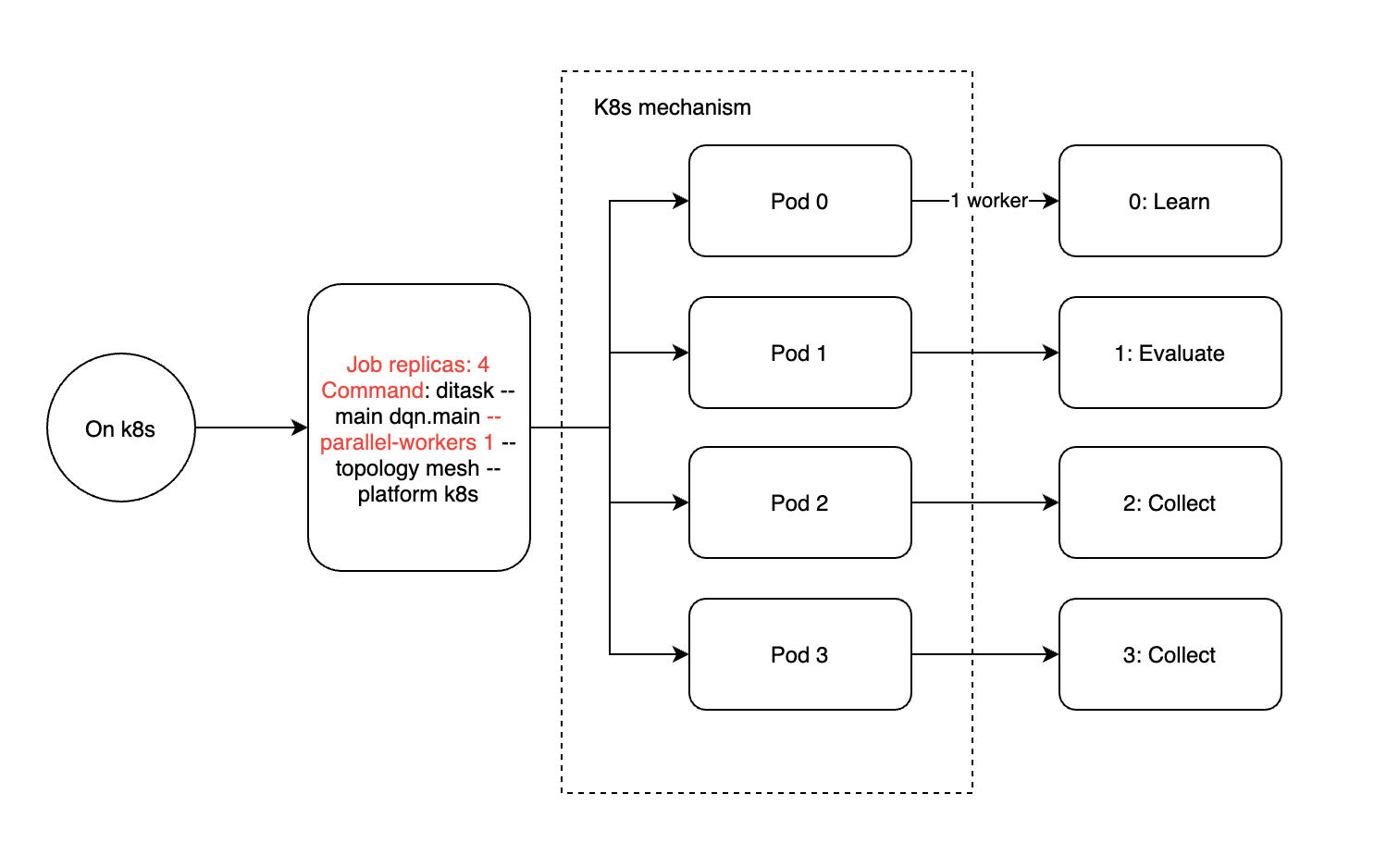
类比来说,K8s集群引入了作业和pod的概念,其中作业可以通过副本配置多个pod,每个pod都有定量的资源分配。在这里,一个pod相当于单台机器内的一个进程,或者slurm中的任务概念。因此,我们建议在k8s中部署ditask时,每个ditask只使用一个工作器(ditask参数–parallel-workers 1)和4个副本。
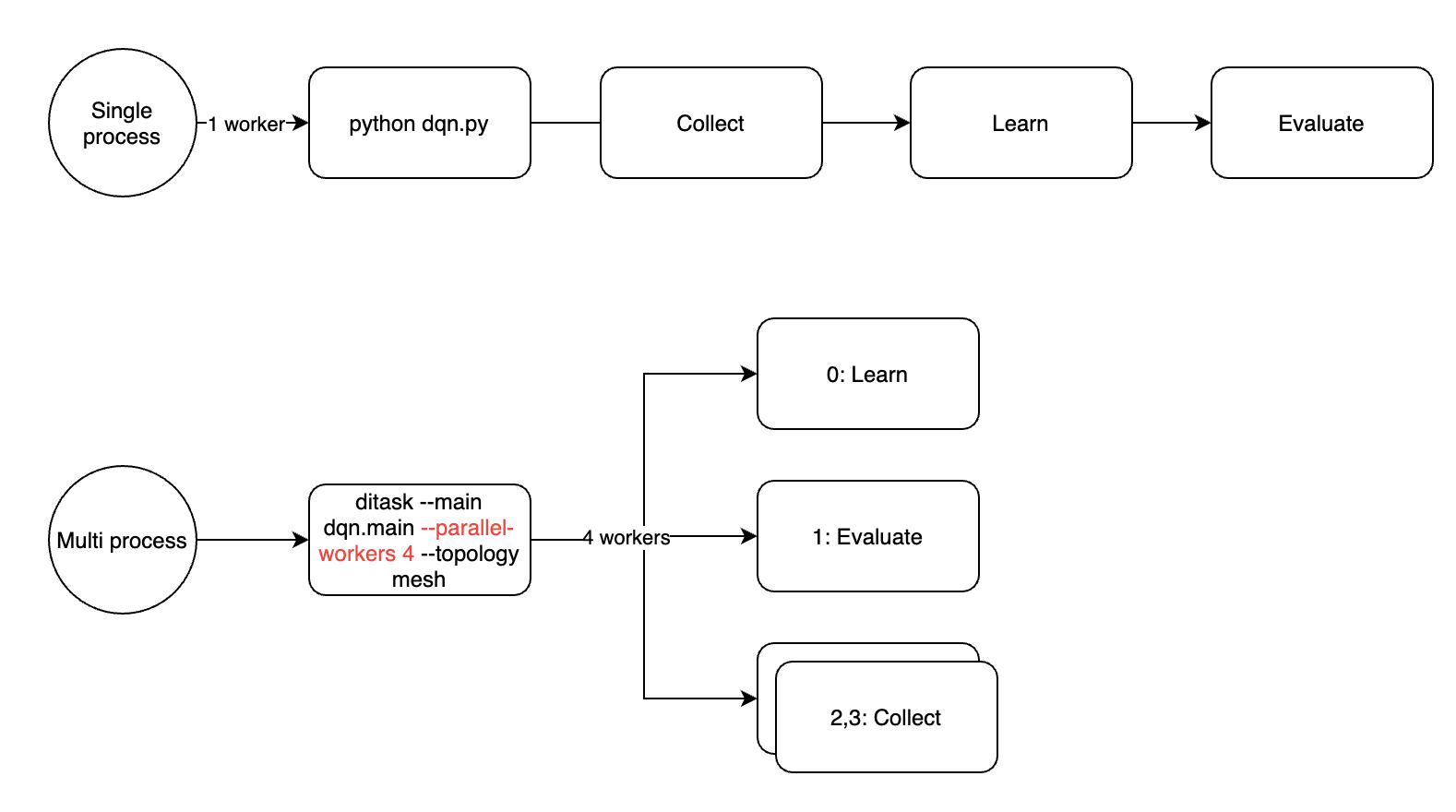
如果出于某些特殊原因(例如,您希望减少pod的数量,因为您没有足够的GPU),您仍然可以在k8s的一个pod或slurm的一个任务中启用多个ditask工作器,实际执行的进程将如下分布。无论哪种方式,--parallel-workers参数仅影响当前容器中的子进程数量,整个训练任务的工作器数量需要乘以ditask主进程的数量(pod的数量或slurm任务的数量)。