中间件¶
在大多数强化学习过程中,环境和代理之间存在一个“收集-学习”循环——从环境中获取数据,训练代理,获取更好的数据,依此类推。我们将在DI-zoo章节中介绍每个环境的特性,这里我们将重点介绍如何实现代理的交互策略。
强化学习的复杂策略决定了很难抽象出与对象交互中涉及的所有实体,而且随着更好的策略和算法不断出现,新的概念和对象层出不穷。因此,我们的想法不是进行对象抽象,而是仅封装过程,并确保封装的代码是可重用和可替换的。这就产生了中间件的概念,这是DI-engine的基础。
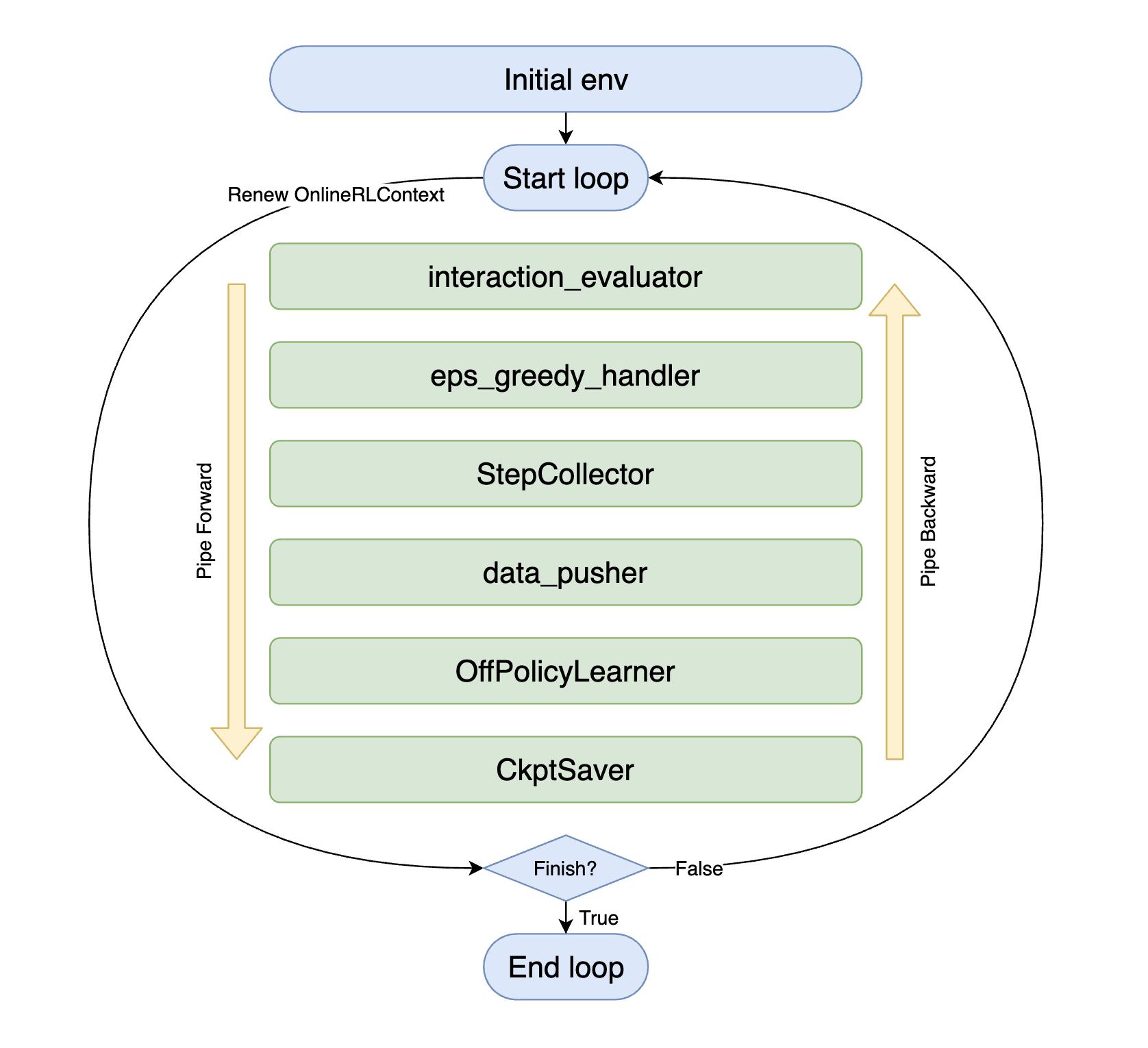
如上所示,每个中间件(图中的绿色部分)都可以仅通过其名称来推测,您只需在DI-engine的中间件库中选择适当的方法来组合它们并完成代理的整个交互策略。
with task.start(async_mode=False, ctx=OnlineRLContext()):
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(eps_greedy_handler(cfg))
task.use(StepCollector(cfg, policy.collect_mode, collector_env))
task.use(data_pusher(cfg, buffer_))
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_))
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100))
task.run(max_step=100000)
一旦你熟悉了中间件,你会发现强化学习的主要流派——Onpolicy、Offpolicy、Offline等——在过程中有许多可重复使用的部分。通过一些简单的选择,你可以将offpolicy过程的交互流程转变为onpolicy过程。
with task.start(async_mode=False, ctx=OnlineRLContext()):
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(StepCollector(cfg, policy.collect_mode, collector_env))
task.use(gae_estimator(cfg, policy.collect_mode))
task.use(multistep_trainer(cfg, policy.learn_mode))
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100))
task.run(max_step=100000)
上下文¶
上下文是在中间件之间传递数据的信使,不同的交互策略决定了它们应该使用什么类型的上下文。
例如,DI-engine 中提供了 OnlineRLContext 和 OfflineRLContext。
@dataclasses.dataclass
class OnlineRLContext(Context):
# common
total_step: int = 0
env_step: int = 0
env_episode: int = 0
train_iter: int = 0
train_data: Union[Dict, List] = None
...
def __post_init__(self):
self.keep('env_step', 'env_episode', 'train_iter', 'last_eval_iter')
OnlineRLContext 保存了在线训练所需的数据,每个中间件的任务是使用这些数据并向上下文提交新数据。例如,OffPolicyLearner 中间件的任务是使用 ctx.train_data 训练模型,并将训练结果写回 ctx.train_iter。
在每个循环开始时,上下文会被一个新的实例替换,这确保了中间件只需要关注单个循环内的数据流,简化了逻辑并减少了内存泄漏的风险。
如果你需要将一些变量保存到下一个循环中,例如env_step、train_iter以及其他需要累积的值,你可以使用ctx.keep方法将其设置为保留字段。 通过ctx.keep调用的变量会为下一次迭代保留,当上下文初始化为新实例时,其他变量将重新初始化。 请注意,理论上,ctx.keep不需要也不应该用于保留集合或更复杂的变量,例如list、dict、torch.tensor或torch.nn.Module。它应该只在需要时将int、float和其他类型的数据保留到下一次迭代。
注意:__post_init__(self) 是一个在 __init__(self) 之后立即调用的方法。在我们的上下文中,它意味着在每个字段初始化后调用此方法。 我们在这个函数中调用 self.keep,因为我们需要在调用 self.keep 之前初始化每个字段以保留选定的变量。
v0.4.2 变更:将 Context 从字典更新为数据类¶
在v0.4.2中,我们将Context从字典更改为数据类。 这一更改的原因是:
防止在开发过程中随意添加新变量,即上下文中的变量必须在Context类的定义中明确定义。
防止使用字符串访问变量,即防止ctx['xxx']。
因为对于中间件来说,通过Context传递数据与通过函数的输入和输出参数传递数据是不同的,后者有强制约束。 在外部随意定义一个新变量,或者使用字符串访问Context中的变量,在阅读代码或合作时很容易导致混淆, 并且在将不同的中间件组合在一起时很容易导致错误。
通过将Context更改为数据类,我们使用属性而不是字符串来访问Context中的特定变量,并防止外部添加新字段。 如果您需要向Context添加新字段, 请在初始化阶段进行。 以下是一个自定义Context的具体示例:
@dataclasses.dataclass
class MyContext(Context):
# common
total_step: int = 0
var1: int = 0
var2: int = 0
var3: Union[Dict, List] = None
var4: List = None
def __post_init__(self):
self.keep('var1', 'var2')
如果您认为需要向DI-engine添加一个新字段,请向DI-engine提交一个PR并解释它。
上下文变量的介绍¶
注意:更新后的位置不包括 ctx.attribute = None 的情况。
OnlineRLContext¶
属性 |
保持 |
类型 |
角色 |
更新位置 |
|---|---|---|---|---|
总步数 |
真 |
整数 |
总迭代步骤的数量。 |
在每个中间件执行循环的开始。 |
环境步骤 |
真 |
整数 |
环境步骤的数量。 |
rolloutor |
环境剧集 |
真 |
整数 |
环境回合的数量。 |
rolloutor |
train_iter |
真 |
整数 |
训练迭代的次数。 |
训练器, 多步训练器 |
训练数据 |
假 |
联合[字典, 列表] |
获取的数据用于训练。 |
gae_estimator, offpolicy_data_fetcher, offline_data_fetcher, her_data_enhancer |
训练输出 |
假 |
联合[字典, 列表[字典]] |
训练输出包括logit、action和其他信息。 |
OffPolicyLearner, HERLearner(List), 训练器, 多步训练器(Dict) |
collect_kwargs |
假 |
字典 |
字典包含epsilon值。 |
eps_greedy_handler |
观测 |
假 |
ttorch.Tensor |
从所有收集器环境中收集的输入观测数据。 |
推理器 |
动作 |
假 |
列表 |
按env_id列出的推断操作。 |
推理器 |
推理输出 |
假 |
字典[int, 字典] |
字典的键是env_id(整数),值是推理结果(字典)。 |
推理器 |
轨迹 |
假 |
列表 |
从环境中收集的轨迹。 |
步骤收集器,n步奖励增强器 |
剧集 |
假 |
列表 |
从环境中收集的片段。 |
剧集收集器 |
轨迹结束索引 |
假 |
列表 |
ctx.trajectories中每个轨迹的结束索引。 |
步骤收集器 |
eval_value |
假 |
浮点数 |
当前评估中的平均奖励。 |
interaction_evaluator, metric_evaluator |
last_eval_iter |
真 |
整数 |
最后一个被评估的 ctx.train_iter。 |
interaction_evaluator, metric_evaluator |
离线强化学习上下文¶
属性 |
保持 |
类型 |
角色 |
更新位置 |
|---|---|---|---|---|
总步数 |
真 |
整数 |
总迭代步骤的数量。 |
在每个中间件执行循环的开始。 |
训练周期 |
假 |
整数 |
训练周期的计数。 |
离线数据获取器 |
train_iter |
真 |
整数 |
训练迭代的次数。 |
训练器, 多步训练器 |
训练数据 |
假 |
联合[字典, 列表] |
获取的数据用于训练。 |
gae_estimator, offpolicy_data_fetcher, offline_data_fetcher, her_data_enhancer |
训练输出 |
假 |
联合[字典, 列表[字典]] |
训练输出包括logit、action和其他信息。 |
OffPolicyLearner, HERLearner(List), 训练器, 多步训练器(Dict) |
eval_value |
假 |
浮点数 |
当前评估中的平均奖励。 |
interaction_evaluator, metric_evaluator |
last_eval_iter |
真 |
整数 |
最后一个被评估的 ctx.train_iter。 |
interaction_evaluator, metric_evaluator |
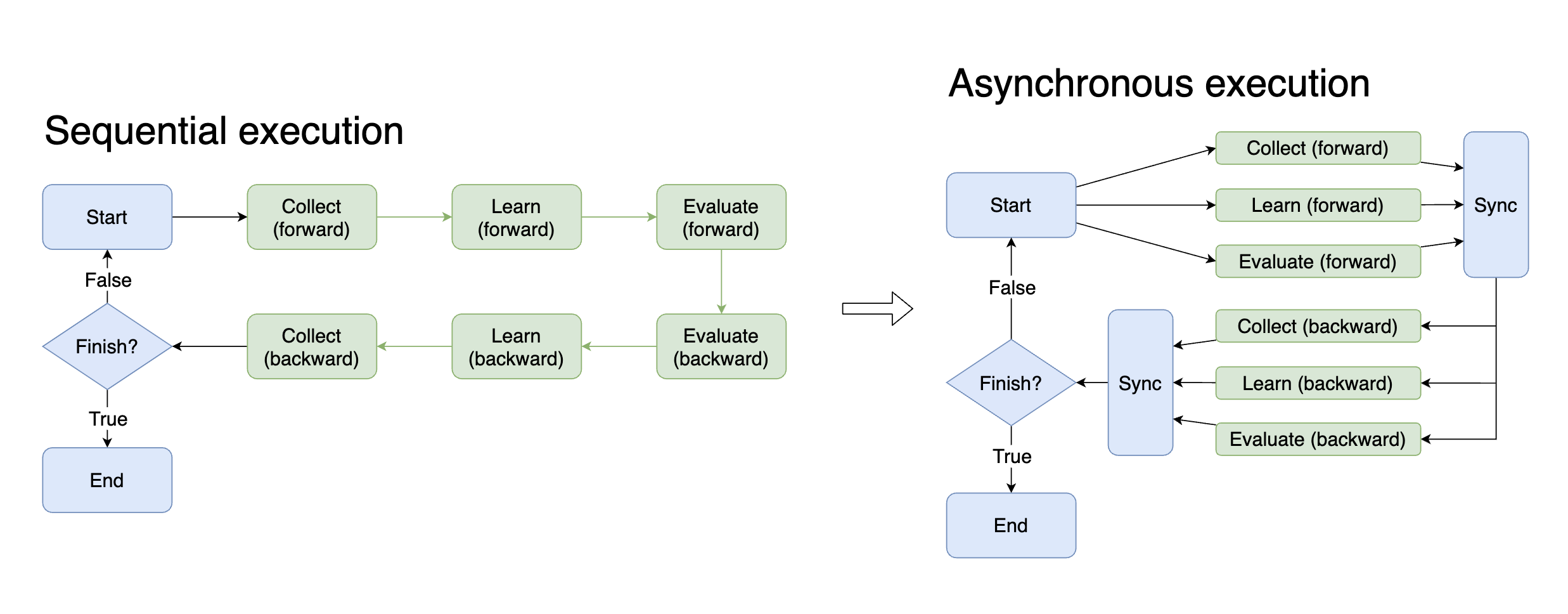
使用任务异步执行任务¶
Task 是 DI-engine 用来管理强化学习交互任务的全局对象。所有运行时状态都保存在任务中,并提供了一些语法糖来帮助简化过程。
在时间紧迫的训练环境中,异步性具有极大的优势。如果可以在模型训练(GPU密集型工作)的同时收集下一次训练(CPU密集型工作)的数据,理论上可以将训练时间减半。为了实现异步性,需要控制复杂的进程并仔细维护各种状态。现在,通过中间件和任务,只需更改一个参数即可在每一步实现异步性。
# Sequential execution
with task.start(async_mode=False, ctx=OnlineRLContext()):
...
# Asynchronous execution
with task.start(async_mode=True, ctx=OnlineRLContext()):
...
除了训练和收集之外,还有许多方法可以利用异步性,例如在训练模型时提前将下一批数据移动到GPU,以及在训练模型时评估历史模型的性能。在实践中,您可能希望尝试更多通过异步执行来加速整个交互过程。
不同阶段的中间件¶
大多数中间件可以对应不同的阶段。您可以在下图中看到现有中间件与阶段之间的对应关系,以便正确组合各种中间件。
