加载预训练模型并恢复训练¶
在使用DI-engine进行强化学习实验时,加载预训练的ckpt文件以从检查点恢复训练是一个常见需求。本文详细解释了如何使用DI-engine加载预训练模型并无缝恢复训练,以cartpole_ppo_config.py为例。
加载预训练模型¶
配置 load_ckpt_before_run¶
要加载预训练模型,首先需要在配置文件中指定预训练的ckpt文件的路径。此路径通过load_ckpt_before_run字段进行配置。
示例代码:
from easydict import EasyDict
cartpole_ppo_config = dict(
exp_name='cartpole_ppo_seed0',
env=dict(
collector_env_num=8,
evaluator_env_num=5,
n_evaluator_episode=5,
stop_value=195,
),
policy=dict(
cuda=False,
action_space='discrete',
model=dict(
obs_shape=4,
action_shape=2,
action_space='discrete',
encoder_hidden_size_list=[64, 64, 128],
critic_head_hidden_size=128,
actor_head_hidden_size=128,
),
learn=dict(
epoch_per_collect=2,
batch_size=64,
learning_rate=0.001,
value_weight=0.5,
entropy_weight=0.01,
clip_ratio=0.2,
# ======== Path to the pretrained checkpoint (ckpt) ========
learner=dict(hook=dict(load_ckpt_before_run='/path/to/your/ckpt/iteration_100.pth.tar')),
resume_training=False,
),
collect=dict(
n_sample=256,
unroll_len=1,
discount_factor=0.9,
gae_lambda=0.95,
),
eval=dict(evaluator=dict(eval_freq=100, ), ),
),
)
cartpole_ppo_config = EasyDict(cartpole_ppo_config)
main_config = cartpole_ppo_config
在上述示例中,load_ckpt_before_run 明确指定了预训练模型的路径 /path/to/your/ckpt/iteration_100.pth.tar。当你运行这段代码时,DI-engine 会自动从该路径加载模型权重,并从中继续训练。
模型加载过程¶
模型加载过程主要发生在entry路径下的主文件中。下面,我们以serial_entry_onpolicy.py文件为例来解释这个过程。
加载预训练模型的关键操作是通过DI-engine的hook机制实现的:
# Learner's before_run hook.
learner.call_hook('before_run')
if cfg.policy.learn.get('resume_training', False):
collector.envstep = learner.collector_envstep
当 load_ckpt_before_run 不为空时,DI-engine 会自动调用 learner 的 before_run 钩子函数,从指定路径加载预训练模型。具体实现可以在 DI-engine 的 learner_hook.py 中找到。
策略本身的检查点保存和加载功能通过_load_state_dict_learn和_state_dict_learn方法实现。例如,在PPO策略中,可以在以下位置找到实现:
从检查点恢复训练¶
恢复时管理日志和TensorBoard路径¶
默认情况下,DI-engine 会为每个实验创建一个新的日志路径,以避免覆盖之前的训练数据和 TensorBoard 日志。但是,如果你想在恢复训练时将日志和 TensorBoard 数据保存在同一目录中,可以通过在配置文件中设置 resume_training=True 来配置此功能(其默认值为 False)。
示例代码:
learn=dict(
... # Other parts of the code
learner=dict(hook=dict(load_ckpt_before_run='/path/to/your/ckpt/iteration_100.pth.tar')),
resume_training=True,
)
当 resume_training=True 时,DI-engine 会将新的日志和 TensorBoard 数据保存在原始路径中。
关键代码:
# Note that the default value of renew_dir is True. When resume_training=True, renew_dir is set to False to ensure the consistency of log paths.
cfg = compile_config(cfg, seed=seed, env=env_fn, auto=True, create_cfg=create_cfg, save_cfg=True, renew_dir=not cfg.policy.learn.get('resume_training', False))
同时,从加载的ckpt文件中恢复的train_iter和collector.envstep将被恢复,使得训练可以从上一个检查点无缝继续。
恢复迭代/步骤计数当恢复时¶
从检查点恢复训练时,训练iter和steps将从检查点中保存的最后一次迭代和步骤计数中恢复。这确保了训练过程从正确的点继续,保持了训练进度的完整性。
首次训练(预训练)结果:
以下图表显示了第一次训练(预训练)的evaluator结果,x轴分别为iter和steps:
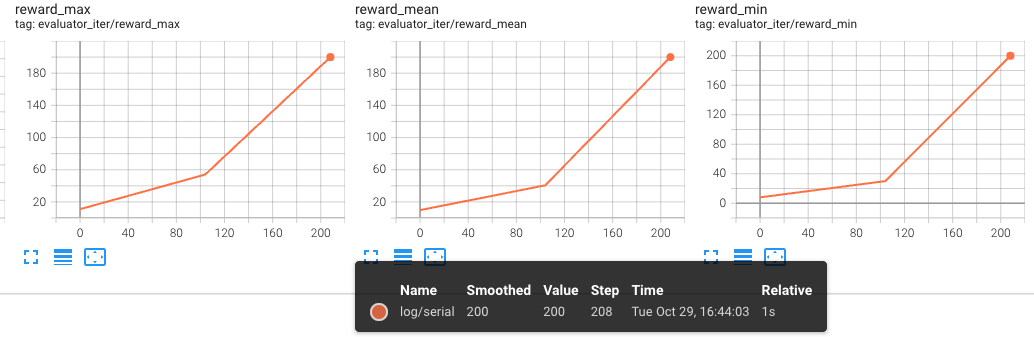
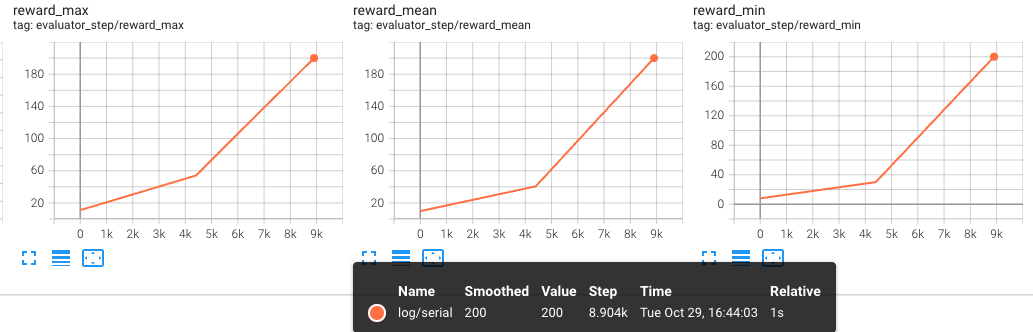
第二次训练(恢复)结果:
以下图表显示了第二次训练(恢复)的evaluator结果,分别在x轴上显示了iter和steps:
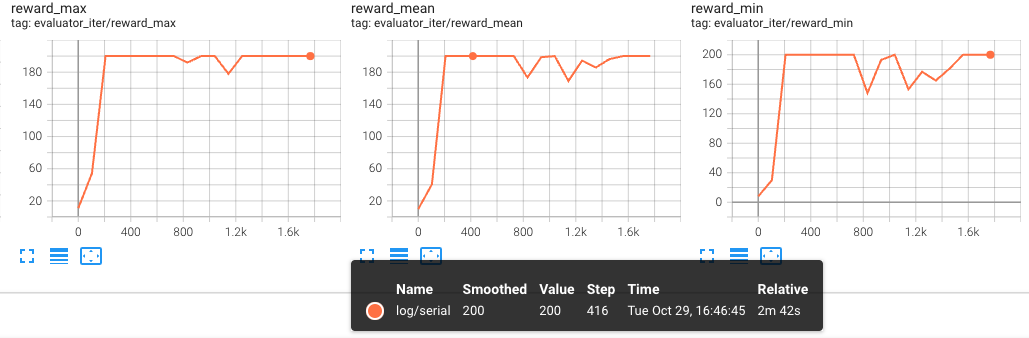
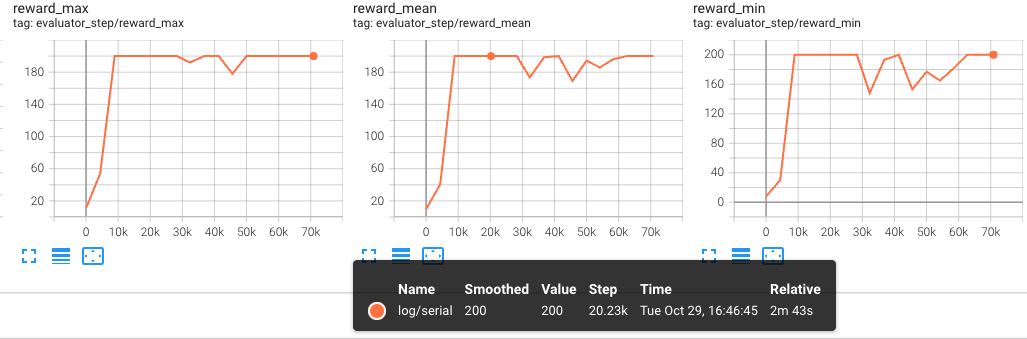
这些图表清楚地表明,训练在恢复后从停止的地方继续,评估指标在相同的迭代/步骤中显示出一致性。
结论¶
在使用DI-engine进行强化学习实验时,加载预训练模型并从检查点恢复训练对于确保稳定、长期的训练至关重要。从本文提供的示例和解释中,我们可以观察到以下内容:
加载预训练模型通过
load_ckpt_before_run字段进行配置,并在训练前通过hook机制自动加载。恢复训练可以通过设置
resume_training=True来实现,确保无缝的日志管理和训练进度继续。在实际实验中,正确管理日志路径和检查点数据可以防止冗余训练和数据丢失,提高实验的效率和可重复性。
我们希望本文能为使用DI-engine的实验提供清晰的指导。