A2C¶
概述¶
A3C(异步优势演员-评论家)算法是一个简单且轻量级的深度强化学习框架,它使用异步梯度下降来优化深度神经网络控制器。另一方面,A2C(优势演员-评论家)是A3C的同步版本,其中策略梯度算法与优势函数结合以减少方差。
快速事实¶
A2C 是一种无模型且基于策略的强化学习算法。
A2C 是一种 在线策略 算法。
A2C 支持 离散 和 连续 动作空间。
A2C 可以配备循环神经网络 (RNN)。
关键方程或关键图表¶
A2C 在策略梯度中使用优势估计。我们通过广义优势估计(GAE)来实现优势:
其中k步优势函数定义为:
伪代码¶

注意
与Q-learning不同,A2C(以及其他actor critic方法)在策略估计和策略改进之间交替进行。
扩展¶
- A2C can be combined with:
多步学习
RNN
广义优势估计(GAE) GAE在使用广义优势估计的高维连续控制中提出,它使用不同步长的优势估计的指数加权平均,以在估计优势的方差和偏差之间进行权衡:
\[\hat{A}_{t}^{\mathrm{GAE}(\gamma, \lambda)}:=(1-\lambda)\left(\hat{A}_{t}^{(1)}+\lambda \hat{A}_{t}^{(2)}+\lambda^{2} \hat{A}_{t}^{(3)}+\ldots\right)\]其中k步优势估计器\(\hat{A}_t^{(k)}\)定义为:
\[\hat{A}_{t}^{(k)}:=\sum_{l=0}^{k-1} \gamma^{l} \delta_{t+l}^{V}=-V\left(s_{t}\right)+r_{t}+\gamma r_{t+1}+\cdots+\gamma^{k-1} r_{t+k-1}+\gamma^{k} V\left(s_{t+k}\right)\]当k=1时,估计器 \(\hat{A}_t^{(1)}\) 是朴素优势估计器:
\[\hat{A}_{t}^{(1)}:=\delta_{t}^{V} \quad=-V\left(s_{t}\right)+r_{t}+\gamma V\left(s_{t+1}\right)\]当使用GAE时,\(\lambda\)的常见值通常属于[0.8, 1.0]。
实现¶
默认配置定义如下:
- class ding.policy.a2c.A2CPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[源代码]
- Overview:
A2C(优势演员-评论家)算法的策略类,提出于https://arxiv.org/abs/1602.01783。
网络接口A2C的定义如下:
- class ding.model.template.vac.VAC(obs_shape: int | SequenceType, action_shape: int | SequenceType | EasyDict, action_space: str = 'discrete', share_encoder: bool = True, encoder_hidden_size_list: SequenceType = [128, 128, 64], actor_head_hidden_size: int = 64, actor_head_layer_num: int = 1, critic_head_hidden_size: int = 64, critic_head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, sigma_type: str | None = 'independent', fixed_sigma_value: int | None = 0.3, bound_type: str | None = None, encoder: Module | None = None, impala_cnn_encoder: bool = False)[source]
- Overview:
与(状态)值演员-评论家(VAC)相关的算法的神经网络和计算图,例如A2C/PPO/IMPALA。该模型现在支持离散、连续和混合动作空间。VAC由四部分组成:
actor_encoder、critic_encoder、actor_head和critic_head。编码器用于从各种观察中提取特征。头部用于预测相应的值或动作逻辑。在高维观察空间(如2D图像)中,我们通常为actor_encoder和critic_encoder使用共享编码器。在低维观察空间(如1D向量)中,我们通常使用不同的编码器。- Interfaces:
__init__,forward,compute_actor,compute_critic,compute_actor_critic.
- compute_actor(x: Tensor) Dict[source]
- Overview:
VAC 前向计算图用于演员部分,输入观察张量以预测动作逻辑值。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。- Returns:
输出 (
Dict): VAC前向计算图的输出字典,包括logit。- ReturnsKeys:
logit (
torch.Tensor): 预测的动作logit张量,对于离散动作空间,它将是相同维度的实值范围张量,表示可能的动作选择,而对于连续动作空间,它将是高斯分布的mu和sigma,mu和sigma的数量与连续动作的数量相同。混合动作空间是离散和连续动作空间的一种组合,因此logit将是一个包含action_type和action_args的字典。- Shapes:
logit (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是action_shape- Examples:
- compute_actor_critic(x: Tensor) Dict[来源]
- Overview:
VAC 前向计算图,包括演员和评论家部分,输入观察张量以预测动作 logit 和状态值。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。- Returns:
输出 (
Dict): VAC前向计算图的输出字典,包括演员和评论家,包含logit和value。- ReturnsKeys:
logit (
torch.Tensor): 预测的动作logit张量,对于离散动作空间,它将是相同维度的可能动作选择的实值范围张量,对于连续动作空间,它将是高斯分布的mu和sigma,mu和sigma的数量与连续动作的数量相同。混合动作空间是离散和连续动作空间的一种组合,因此logit将是一个包含action_type和action_args的字典。值 (
torch.Tensor): 预测的状态值张量。- Shapes:
logit (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是action_shape值 (
torch.Tensor): \((B, )\), 其中 B 是批量大小,(B, 1) 被压缩为 (B, )。- Examples:
注意
compute_actor_critic接口旨在在共享编码器时节省计算,并返回组合的字典输出。
- compute_critic(x: Tensor) Dict[source]
- Overview:
VAC 前向计算图用于评论家部分,输入观察张量以预测状态值。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。- Returns:
输出 (
Dict): VAC前向计算图的输出字典,包括value。- ReturnsKeys:
值 (
torch.Tensor): 预测的状态值张量。- Shapes:
值 (
torch.Tensor): \((B, )\), 其中 B 是批量大小,(B, 1) 被压缩为 (B, )。- Examples:
- forward(x: Tensor, mode: str) Dict[source]
- Overview:
VAC前向计算图,输入观测张量以预测状态值或动作逻辑。不同的
mode将使用不同的网络模块进行前向传播,以获得不同的输出并节省计算。- Arguments:
x (
torch.Tensor): 输入的观测张量数据。模式 (
str): 前向模式,所有模式都在这个类的开头定义。- Returns:
输出 (
Dict): VAC前向计算图的输出字典,其键值因不同的mode而异。- Examples (Actor):
- Examples (Critic):
- Examples (Actor-Critic):
A2C的策略梯度和价值更新实现如下:
def a2c_error(data: namedtuple) -> namedtuple:
logit, action, value, adv, return_, weight = data
if weight is None:
weight = torch.ones_like(value)
dist = torch.distributions.categorical.Categorical(logits=logit)
logp = dist.log_prob(action)
entropy_loss = (dist.entropy() * weight).mean()
policy_loss = -(logp * adv * weight).mean()
value_loss = (F.mse_loss(return_, value, reduction='none') * weight).mean()
return a2c_loss(policy_loss, value_loss, entropy_loss)
注意
我们应用GAE来计算优势,当使用GAE默认参数gae_lambda =0.95更新演员网络时。价值网络更新的目标是通过当前时间步的价值函数加上在收集器中计算的优势函数获得的。
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
乒乓球 (PongNoFrameskip-v4) |
20 |
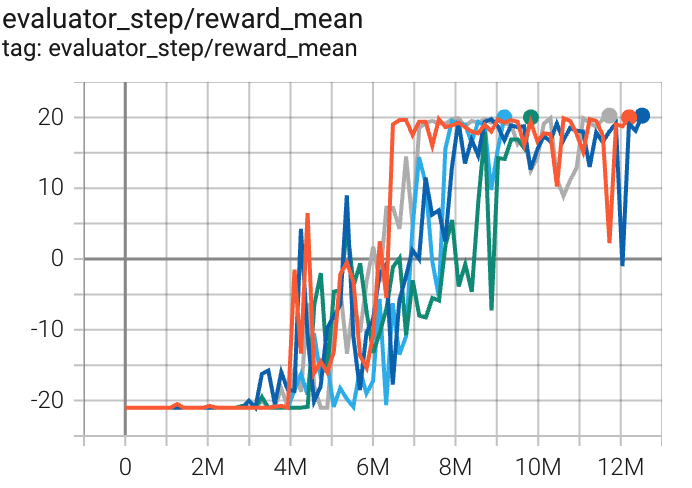
|
Sb3(17) |
|
Qbert (QbertNoFrameskip-v4) |
4819 |
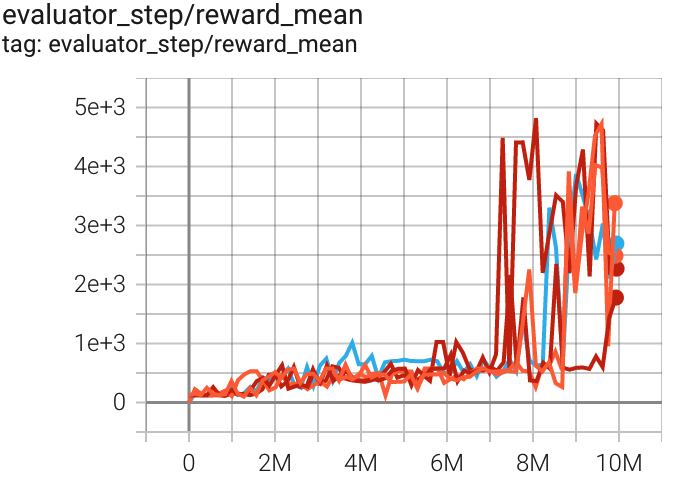
|
Sb3(3882) Rllib(3620) |
|
太空侵略者 (SpaceInvadersNoFrame skip-v4) |
826 |
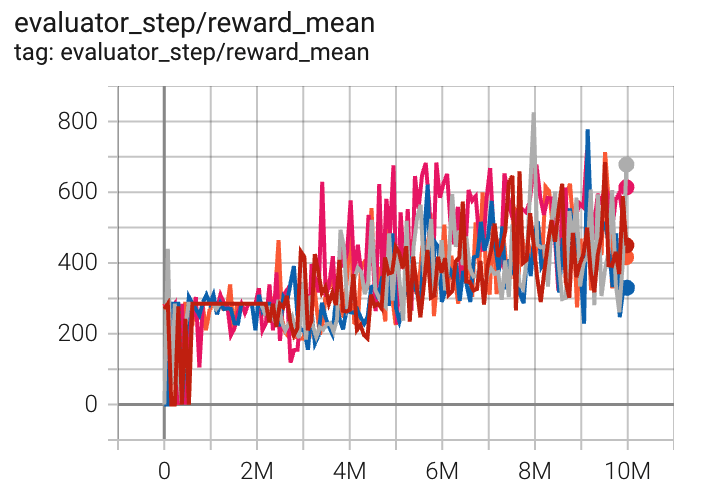
|
Sb3(627) Rllib(692) |
附注:
上述结果是通过在五个不同的随机种子(0, 1, 2, 3, 4)上运行相同的配置获得的
参考文献¶
Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, Koray Kavukcuoglu: “深度强化学习的异步方法”, 2016, ICML 2016; arXiv:1602.01783. https://arxiv.org/abs/1602.01783