ACER¶
概述¶
ACER,全称为带有经验回放的演员-评论家算法,提出了一种带有经验回放的演员-评论家深度强化学习代理,该代理在具有挑战性的环境中表现稳定、样本效率高,并且在离散的57款Atari游戏领域和几个连续控制问题上表现非常出色。它通过使用以下技巧大大提高了样本效率并减少了数据相关性:
带有偏差校正的截断重要性采样,它控制了离策略估计器的稳定性
Retrace Q 值估计,这是一种离策略、低方差且基于回报的算法,已被证明能够收敛
高效的TRPO(信任区域策略优化),能够很好地扩展到大规模问题
随机对决网络(SDNs),旨在估计\(V^\pi\)和\(Q^\pi\),同时在两个估计之间保持一致性。
你可以在论文Sample Efficient Actor-Critic with Experience Replay中找到更多详细信息。
快速事实¶
ACER 是一种无模型和离策略的强化学习算法。
ACER 支持离散动作空间和连续动作空间,两者之间存在一些差异。
ACER 是一种 actor-critic 强化学习算法,它分别优化了 actor 和 critic 网络。
ACER 将行动与学习分离。ACER 中的收集器需要记录行为概率分布。
在以下部分中,我们以离散情况为例详细阐述ACER算法。
关键公式¶
ACER中使用的损失包含策略损失和价值损失。它们是分别更新的,因此需要控制它们的相对更新速度。
Retrace Q值估计¶
给定在行为策略\(\mu\)下生成的轨迹,我们检索一个轨迹\({x_0, a_0, r_0, \mu(\cdot|x_0),..., x_k, a_k, r_k, \mu(\cdot|x_k)}\),Retrace估计器可以递归地表示如下:
其中 \(\bar{\rho}_t\) 是截断的重要性权重,\(\bar{\rho}_t=\min\{c,\rho\}\) 其中 \(\frac{\pi(a_t|x_t)}{\mu(a_t|x_t)}\)。\(\pi\) 是目标策略。 Retrace 是一种基于回报的离策略算法,具有低方差,并且被证明可以收敛到目标策略的价值函数,适用于任何行为策略。 我们通过神经网络 \(Q_{\theta}\) 来近似 Q 值。我们使用均方误差损失:
\[{\text{value}}=\frac{1}{2}(Q^{\text{ret}}(x_t,a_t)-Q_{\theta}(x_t,a_t))^2.\]
策略梯度¶
为了防止高方差,ACER 使用截断的重要性权重,并通过以下分解引入校正项 \(g^{acer}\):
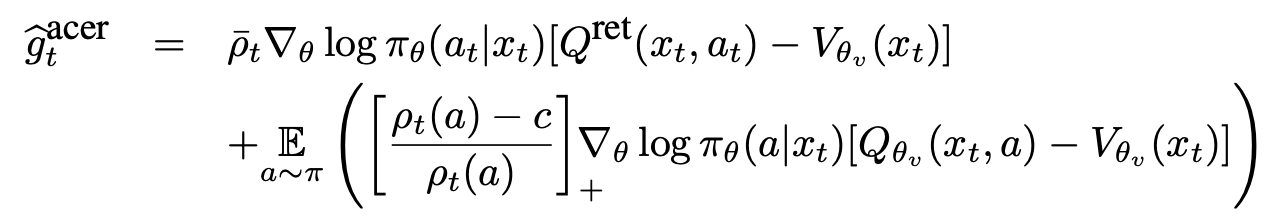
为了确保稳定性,ACER通过解决以下线性化KL散度约束来限制每一步的策略变化:
\(\phi(\theta)\) 是目标策略网络,而 \(\phi(\theta_a)\) 是平均策略网络。 通过让 \(k=\nabla_{\phi_{\theta}(x_t)}D_{KL}[f(\cdot|\phi_{\theta_a}(x_t))\|f(\cdot|\phi_{\theta}(x_t))]\),可以使用KKT条件轻松地以封闭形式导出解决方案:
关键图或网络结构¶
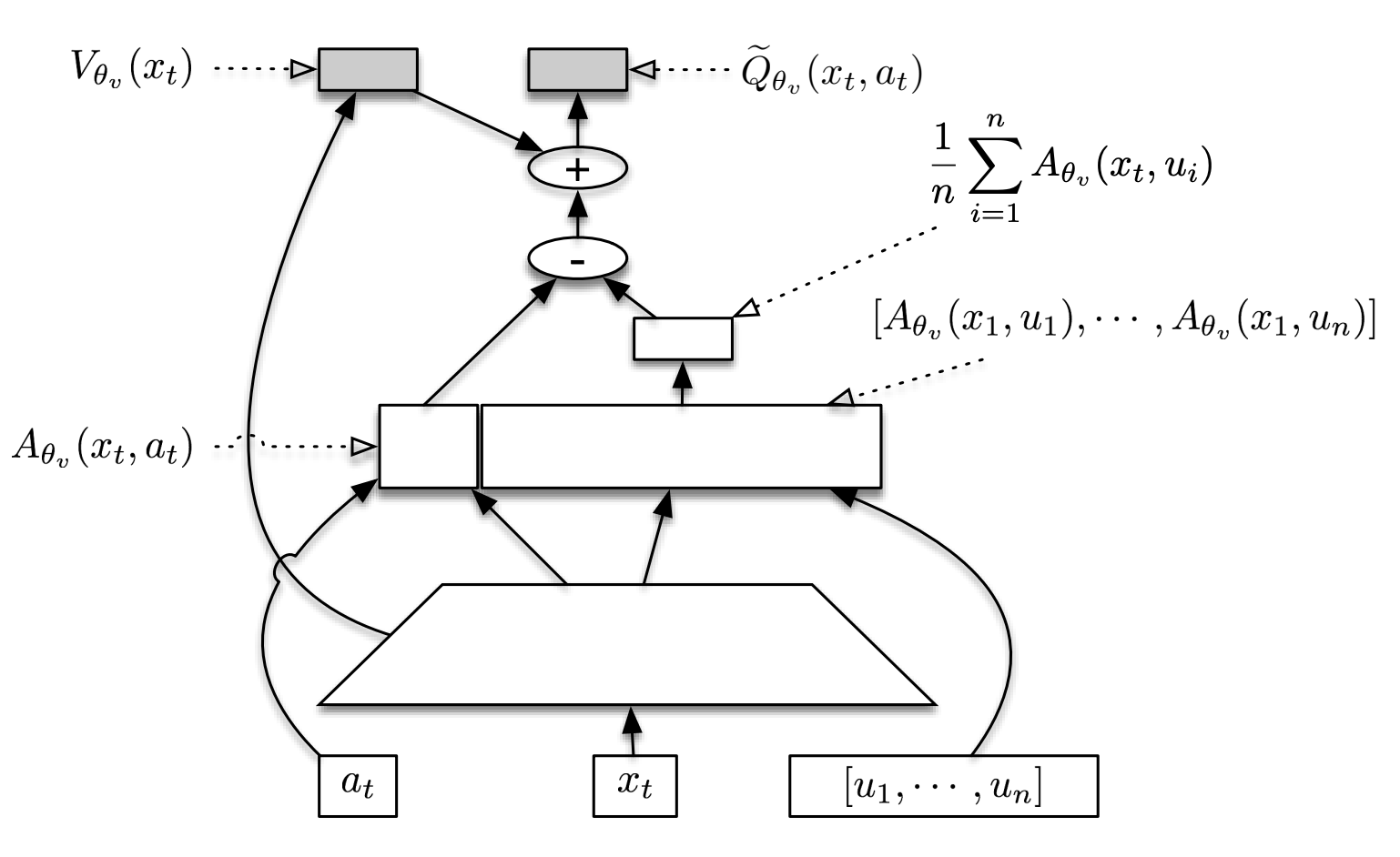
下图展示了SDN结构(图片来自论文《Sample Efficient Actor-Critic with Experience Replay》)。在图中,\([u_1, .... , u_n]\) 被假设为来自 \(\pi_\theta(·|x_t)\) 的样本。
伪代码¶
在应用于离散动作空间和连续动作空间的ACER之间存在一些变化。


在连续动作空间中,不可能为每个动作枚举Q值。 因此,ACER使用采样的动作来近似期望值。

实现¶
这里我们展示了在离散动作空间上的ACER算法。 默认配置定义如下:
- class ding.policy.acer.ACERPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
ACER算法的策略类。
- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
宏碁
RL policy register name, refer toregistryPOLICY_REGISTRYthis arg is optional,a placeholder2
cuda布尔
假
Whether to use cuda for networkthis arg can be diff-erent from modes3
on_policy布尔
假
Whether the RL algorithm ison-policy or off-policy4
trust_region布尔
真
Whether the RL algorithm use trustregion constraint5
trust_region_value浮点数
1.0
maximum range of the trust region6
unroll_len整数
32
trajectory length to calculateQ retrace target7
learn.updateper_collect整数
4
How many updates(iterations) totrain after collector’s onecollection. Onlyvalid in serial trainingthis args can be varyfrom envs. Bigger valmeans more off-policy8
c_clip_ratio浮点数
1.0
clip ratio of importance weights
通常,我们希望以批处理的方式计算所有内容以提高效率。这是在policy._get_train_sample中完成的。
一旦我们在收集器中执行此函数,样本的长度将等于配置中的unroll-len。有关详细信息,请参阅ding.rl_utils.adder的文档。
你可以在这里找到ACER的完整代码here。 这里我们展示该算法的一些细节。
首先,我们使用以下函数来计算retrace Q值。
def compute_q_retraces(
q_values: torch.Tensor,
v_pred: torch.Tensor,
rewards: torch.Tensor,
actions: torch.Tensor,
weights: torch.Tensor,
ratio: torch.Tensor,
gamma: float = 0.9
) -> torch.Tensor:
rewards = rewards.unsqueeze(-1) # shape T,B,1
actions = actions.unsqueeze(-1) # shape T,B,1
weights = weights.unsqueeze(-1) # shape T,B,1
q_retraces = torch.zeros_like(v_pred) # shape (T+1),B,1
n_len = q_retraces.size()[0] # T+1
tmp_retraces = v_pred[-1, ...] # shape B,1
q_retraces[-1, ...] = v_pred[-1, ...]
q_gather = torch.zeros_like(v_pred)
q_gather[0:-1, ...] = q_values[0:-1, ...].gather(-1, actions) # shape (T+1),B,1
ratio_gather = ratio.gather(-1, actions) # shape T,B,1
for idx in reversed(range(n_len - 1)):
q_retraces[idx, ...] = rewards[idx, ...] + gamma * weights[idx, ...] * tmp_retraces
tmp_retraces = ratio_gather[idx, ...].clamp(max=1.0) * (q_retraces[idx, ...] - q_gather[idx, ...]) + v_pred[idx, ...]
return q_retraces # shape (T+1),B,1
之后,我们计算策略损失的值,它将通过以下函数计算带有重要性权重截断和偏差校正损失的演员损失
def acer_policy_error(
q_values: torch.Tensor,
q_retraces: torch.Tensor,
v_pred: torch.Tensor,
target_logit: torch.Tensor,
actions: torch.Tensor,
ratio: torch.Tensor,
c_clip_ratio: float = 10.0
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Overview:
Get ACER policy loss
Arguments:
- q_values (:obj:`torch.Tensor`): Q values
- q_retraces (:obj:`torch.Tensor`): Q values (be calculated by retrace method)
- v_pred (:obj:`torch.Tensor`): V values
- target_pi (:obj:`torch.Tensor`): The new policy's probability
- actions (:obj:`torch.Tensor`): The actions in replay buffer
- ratio (:obj:`torch.Tensor`): ratio of new polcy with behavior policy
- c_clip_ratio (:obj:`float`): clip value for ratio
Returns:
- actor_loss (:obj:`torch.Tensor`): policy loss from q_retrace
- bc_loss (:obj:`torch.Tensor`): correct policy loss
Shapes:
- q_values (:obj:`torch.FloatTensor`): :math:`(T, B, N)`, where B is batch size and N is action dim
- q_retraces (:obj:`torch.FloatTensor`): :math:`(T, B, 1)`
- v_pred (:obj:`torch.FloatTensor`): :math:`(T, B, 1)`
- target_pi (:obj:`torch.FloatTensor`): :math:`(T, B, N)`
- actions (:obj:`torch.LongTensor`): :math:`(T, B)`
- ratio (:obj:`torch.FloatTensor`): :math:`(T, B, N)`
- actor_loss (:obj:`torch.FloatTensor`): :math:`(T, B, 1)`
- bc_loss (:obj:`torch.FloatTensor`): :math:`(T, B, 1)`
"""
actions = actions.unsqueeze(-1)
with torch.no_grad():
advantage_retraces = q_retraces - v_pred # shape T,B,1
advantage_native = q_values - v_pred # shape T,B,env_action_shape
actor_loss = ratio.gather(-1, actions).clamp(max=c_clip_ratio) * advantage_retraces * target_logit.gather(
-1, actions
) # shape T,B,1
# bias correction term, the first target_pi will not calculate gradient flow
bias_correction_loss = (1.0-c_clip_ratio/(ratio+EPS)).clamp(min=0.0)*torch.exp(target_logit).detach() * \
advantage_native*target_logit # shape T,B,env_action_shape
bias_correction_loss = bias_correction_loss.sum(-1, keepdim=True)
return actor_loss, bias_correction_loss
然后,我们执行对target_pi的反向操作。此外,我们需要在信任区域内计算修正梯度:
def acer_trust_region_update(
actor_gradients: List[torch.Tensor], target_logit: torch.Tensor, avg_logit: torch.Tensor,
trust_region_value: float
) -> List[torch.Tensor]:
"""
Overview:
calcuate gradient with trust region constrain
Arguments:
- actor_gradients (:obj:`list(torch.Tensor)`): gradients value's for different part
- target_pi (:obj:`torch.Tensor`): The new policy's probability
- avg_pi (:obj:`torch.Tensor`): The average policy's probability
- trust_region_value (:obj:`float`): the range of trust region
Returns:
- update_gradients (:obj:`list(torch.Tensor)`): gradients with trust region constraint
Shapes:
- target_pi (:obj:`torch.FloatTensor`): :math:`(T, B, N)`
- avg_pi (:obj:`torch.FloatTensor`): :math:`(T, B, N)`
"""
with torch.no_grad():
KL_gradients = [torch.exp(avg_logit)]
update_gradients = []
# TODO: here is only one elements in this list.Maybe will use to more elements in the future
actor_gradient = actor_gradients[0]
KL_gradient = KL_gradients[0]
scale = actor_gradient.mul(KL_gradient).sum(-1, keepdim=True) - trust_region_value
scale = torch.div(scale, KL_gradient.mul(KL_gradient).sum(-1, keepdim=True)).clamp(min=0.0)
update_gradients.append(actor_gradient - scale * KL_gradient)
return update_gradients
通过新的梯度,我们可以继续向后传播,然后相应地更新参数。
最后,我们应该计算Q值的均方损失以更新Q网络
def acer_value_error(q_values, q_retraces, actions):
"""
Overview:
Get ACER critic loss
Arguments:
- q_values (:obj:`torch.Tensor`): Q values
- q_retraces (:obj:`torch.Tensor`): Q values (be calculated by retrace method)
- actions (:obj:`torch.Tensor`): The actions in replay buffer
- ratio (:obj:`torch.Tensor`): ratio of new polcy with behavior policy
Returns:
- critic_loss (:obj:`torch.Tensor`): critic loss
Shapes:
- q_values (:obj:`torch.FloatTensor`): :math:`(T, B, N)`, where B is batch size and N is action dim
- q_retraces (:obj:`torch.FloatTensor`): :math:`(T, B, 1)`
- actions (:obj:`torch.LongTensor`): :math:`(T, B)`
- critic_loss (:obj:`torch.FloatTensor`): :math:`(T, B, 1)`
"""
actions = actions.unsqueeze(-1)
critic_loss = 0.5 * (q_retraces - q_values.gather(-1, actions)).pow(2)
return
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
乒乓球 (PongNoFrameskip-v4) |
20 |
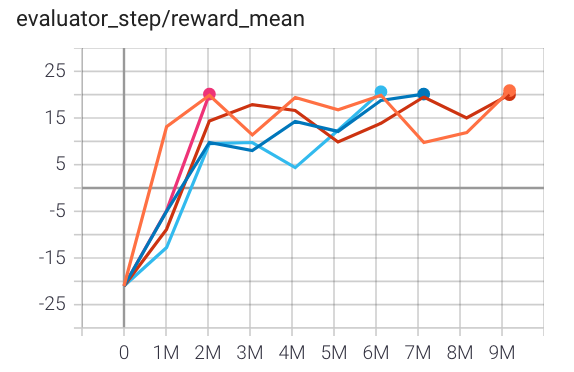
|
||
Qbert (QbertNoFrameskip-v4) |
4000(待办) |
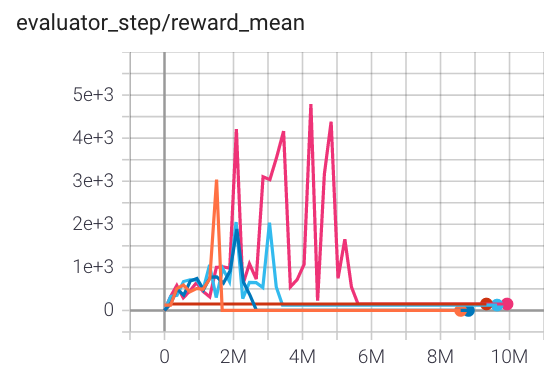
|
||
太空侵略者 (SpaceInvadersNoFrame skip-v4) |
1100 |
|
参考文献¶
王自玉, 维克多·巴普斯特, 尼古拉斯·希斯, 弗拉基米尔·米尼, 雷米·穆诺斯, 科拉伊·卡武克库奥卢, 南多·德弗雷塔斯: “具有经验回放的样本高效演员-评论家”, 2016; [https://arxiv.org/abs/1611.01224 arxiv:1611.01224].