CollaQ¶
概述¶
CollaQ(张等人,2020年),协作Q学习,是一种基于Q学习的多智能体协作方法,它将多智能体协作表述为奖励分配的联合优化问题。CollaQ将单个智能体的分散Q值函数分解为两个项,一个是仅依赖于智能体自身状态的自我项,另一个是与附近智能体状态相关的交互项。CollaQ使用常规的DQN进行联合训练,并通过多智能体奖励分配(MARA)损失进行调节。
快速事实¶
CollaQ 是一种无模型且基于价值的多智能体强化学习方法。
CollaQ 仅支持 离散 动作空间。
CollaQ 是一种 离策略 算法。
CollaQ 考虑了一个部分可观测的场景,其中每个代理只能获得个体观测。
CollaQ 使用 DRQN 架构进行个体 Q 学习。
与QMIX和VDN相比,CollaQ不需要集中式的Q函数,它通过根据联合状态分配奖励来扩展每个代理的个体Q函数。
关键方程或关键图表¶
CollaQ中基于注意力模型的Q函数的整体架构:
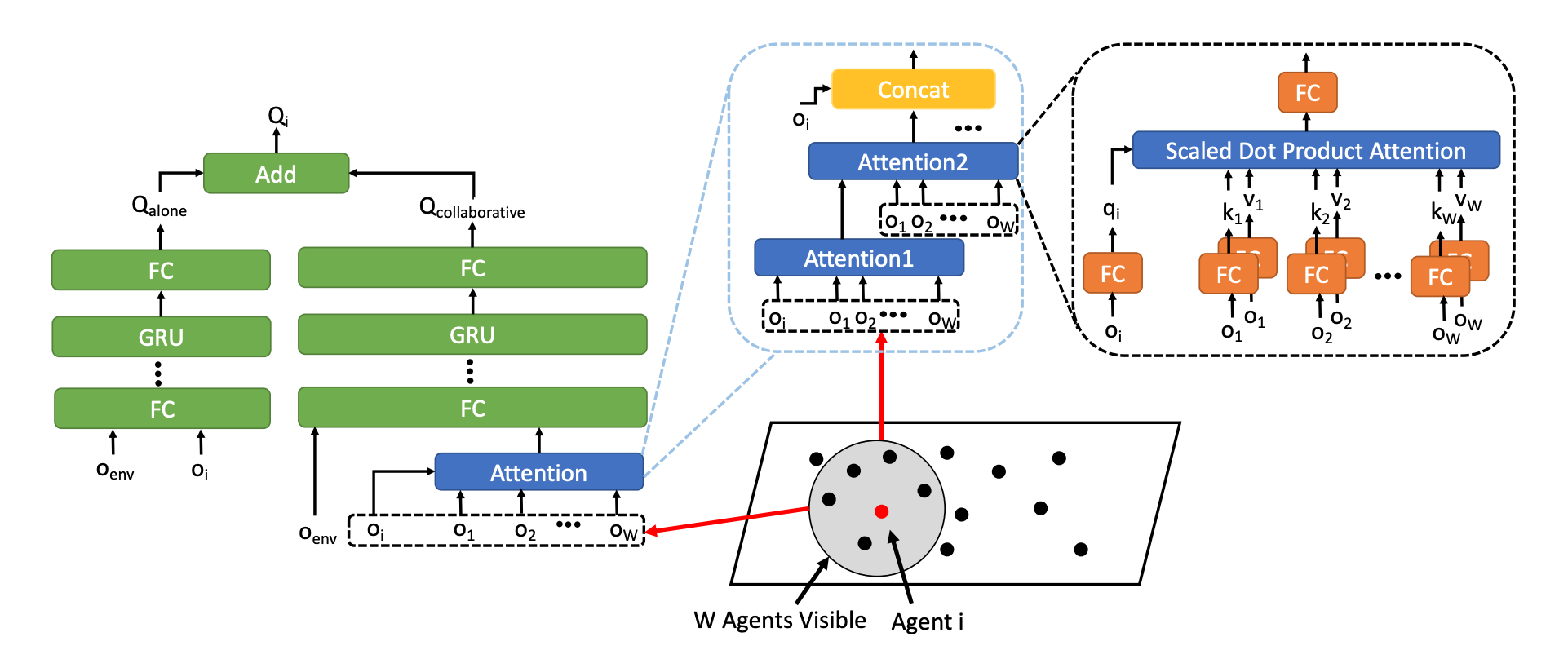
代理i的Q函数:
标准DQN训练与MARA损失的总体训练目标:
扩展¶
CollaQ可以选择是否使用基于注意力的架构。因为观察可能在空间上很大,并且覆盖了那些状态对某个智能体策略贡献不大的智能体。具体来说,CollaQ使用了transformer架构(堆叠多层注意力模块),这在多智能体任务中经验上有助于提高性能。
实现¶
默认配置定义如下:
- class ding.policy.collaq.CollaQPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
CollaQ算法的策略类。CollaQ是一种多智能体强化学习算法
- Interface:
- _init_learn, _data_preprocess_learn, _forward_learn, _reset_learn, _state_dict_learn, _load_state_dict_learn
_init_collect, _forward_collect, _reset_collect, _process_transition, _init_eval, _forward_eval_reset_eval, _get_train_sample, default_model
- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
collaq
POLICY_REGISTRY2
cuda布尔
真
3
on_policy布尔
假
priority布尔
假
5
priority_IS_weight布尔
假
6
learn.update_per_collect整数
20
7
learn.target_update_theta浮点数
0.001
8
learn.discount_factor浮点数
0.99
9
learn.collaq_loss_weight浮点数
1.0
CollaQ 使用的网络接口定义如下:
- class ding.model.template.collaq.CollaQ(agent_num: int, obs_shape: int, alone_obs_shape: int, global_obs_shape: int, action_shape: int, hidden_size_list: list, attention: bool = False, self_feature_range: List[int] | None = None, ally_feature_range: List[int] | None = None, attention_size: int = 32, mixer: bool = True, lstm_type: str = 'gru', activation: Module = ReLU(), dueling: bool = False)[source]
- Overview:
CollaQ(协作Q学习)算法的网络。 它包括两部分:q_network和q_alone_network。 q_network用于获取代理观察的q_value以及代理关心的盟友的部分观察信息。 q_alone_network用于获取代理观察的q_value以及没有代理关心的盟友的观察信息。 通过奖励归因分解实现多代理协作 https://arxiv.org/abs/2010.08531
- Interface:
__init__,forward,_setup_global_encoder
- forward(data: dict, single_step: bool = True) dict[source]
- Overview:
forward 方法计算每个代理的 q_value 和所有代理的总 q_value。 每个代理的 q_value 由 q_network 计算,总 q_value 由 mixer 计算。
- Arguments:
- data (
dict): input data dict with keys [‘obs’, ‘prev_state’, ‘action’]
agent_state (
torch.Tensor): 每个代理的本地状态(obs)agent_alone_state (
torch.Tensor): 每个智能体的单独局部状态,在smac设置中是没有盟友特征的(obs_along)global_state (
torch.Tensor): 全局状态(obs)prev_state (
list): 之前的rnn状态,应该包括3部分: q_network的一个隐藏状态,以及如果q_alone_network的两个隐藏状态用于obs和obs_alone输入动作 (
torch.Tensor或 None): 如果动作为 None,则使用 argmax q_value 索引作为动作来计算agent_q_actsingle_step (
bool): 是否单步前进,如果是,则在前进前添加时间步维度并在前进后移除它- Return:
- ret (
dict): output data dict with keys [‘total_q’, ‘logit’, ‘next_state’]
total_q (
torch.Tensor): 总q值,这是混合器网络的结果agent_q (
torch.Tensor): 每个代理的q值next_state (
list): 下一个RNN状态- Shapes:
agent_state (
torch.Tensor): \((T, B, A, N)\), 其中 T 是时间步长,B 是批量大小,A 是代理数量,N 是观测形状global_state (
torch.Tensor): \((T, B, M)\), 其中 M 是 global_obs_shapeprev_state (
list): 数学:(B, A), 一个长度为B的列表,每个元素是一个长度为A的列表动作 (
torch.Tensor): \((T, B, A)\)total_q (
torch.Tensor): \((T, B)\)agent_q (
torch.Tensor): \((T, B, A, P)\), 其中 P 是动作形状next_state (
list): 数学:(B, A), 一个长度为B的列表,每个元素是一个长度为A的列表- Examples:
在DI-engine中实现的CollaQ在SMAC(Samvelyan等人,2019年)中的基准测试结果,用于星际争霸微操问题,如下所示。
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
5米6米 |
1 |
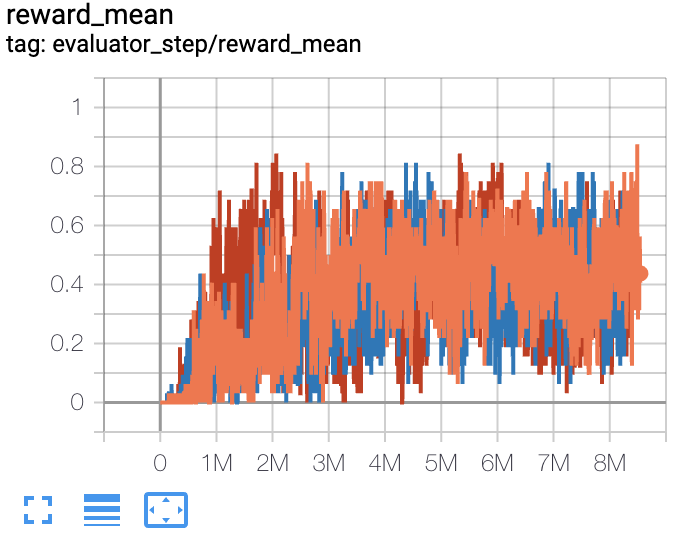
|
Pymarl(0.8) |
|
MMM |
0.7 |
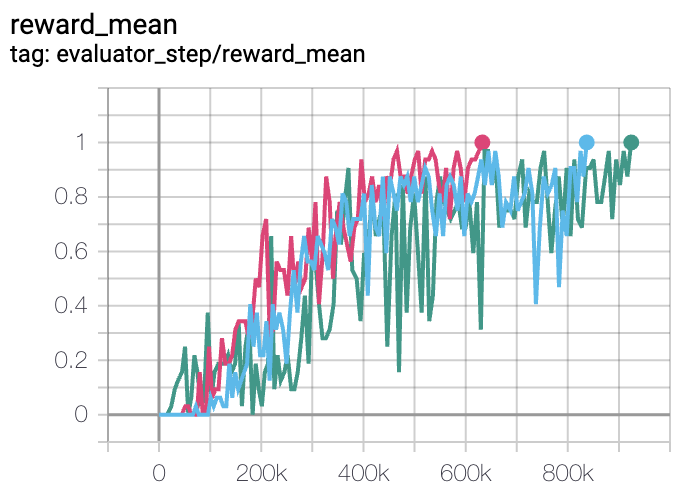
|
Pymarl(1) |
|
3s5z |
1 |
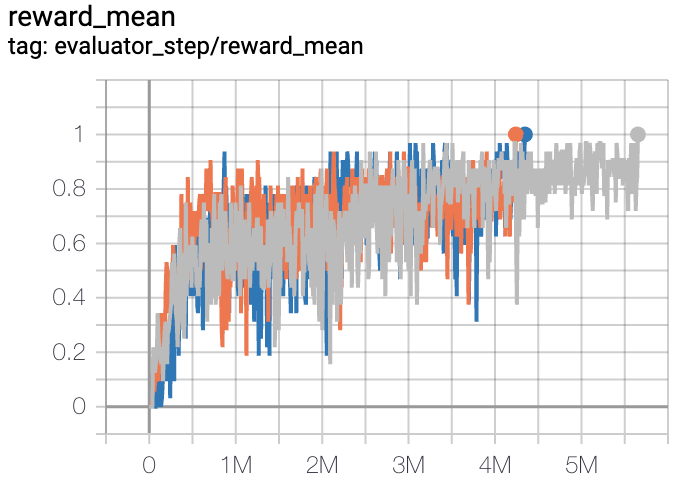
|
Pymarl(1) |
附注:
上述结果是通过在三个不同的随机种子(0, 1, 2)上运行相同的配置获得的。
参考文献¶
张天俊, 徐华哲, 王晓龙, 吴毅, Kurt Keutzer, Joseph E. Gonzalez, 田远东. 多智能体协作通过奖励归因分解. arXiv预印本 arXiv:2010.08531, 2020.
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob Foerster, Shimon Whiteson. 星际争霸多智能体挑战. arXiv preprint arXiv:1902.04043, 2019.