COMA¶
概述¶
COMA(Foerster 等人,2018),反事实多智能体策略梯度,是一种基于多智能体演员-评论家的方法,用于学习完全集中的状态动作函数,并利用它来指导分散策略的优化。COMA 使用集中评论家来训练分散的演员,为每个智能体估计一个反事实优势函数,以解决多智能体信用分配问题。COMA 中使用反事实基线来边缘化单个智能体的动作,同时保持其他智能体的动作不变,集中评论家表示允许高效计算反事实基线。
快速事实¶
COMA 使用集中训练与分散执行的范式。
COMA 是一种无模型和演员评论家方法。
COMA 专注于具有离散动作的设置。COMA 可以通过其他估计方法扩展到连续动作空间。
COMA 使用 on-policy 策略梯度学习来训练评论家。
COMA 的样本效率较差,容易陷入次优的局部最小值。
COMA 考虑了一个部分可观测的环境,其中每个智能体只能获取个体观测。在执行过程中,智能体必须依赖本地的动作-观测历史。
COMA 接受 独立演员-评论家 作为个体价值网络,并通过在代理之间共享参数来加速学习。
由于学习是集中式的,COMA中的集中式评论者估计了基于中央状态的联合行动的Q值。
关键方程或关键图表¶
COMA中分散的参与者、环境和集中式评论者之间的整体信息流:
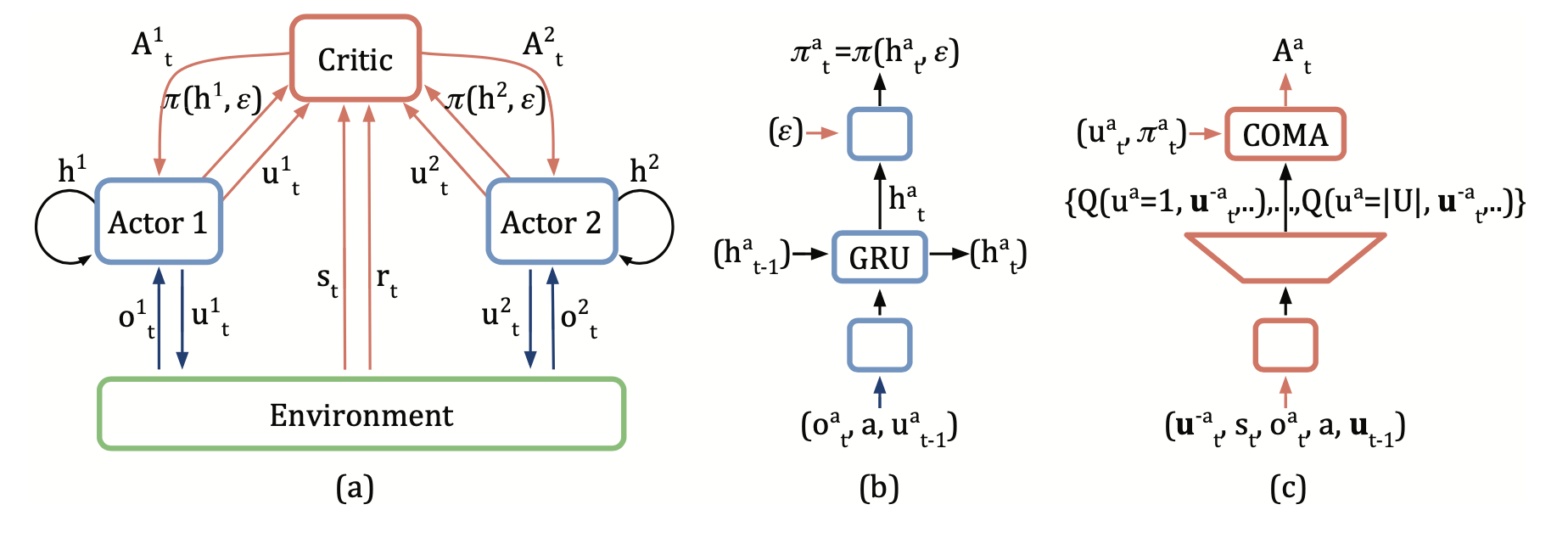
COMA 计算一个优势函数,该函数将当前动作 $u^a$ 的 Q 值与一个反事实基线进行比较,该基线在保持其他代理的动作 \(u^{-a}\) 固定的同时,将 \(u^a\) 边缘化。
优势 \(A^{a}(s, u)\) 计算一个单独的基线,该基线使用集中式评论家来找到仅当 \(a\) 的动作发生变化时的反事实,直接从代理的经验中学习。
方程中的第一项是当前选择动作的全局Q值,它表示在集中关键中的估计Q值。方程中的第二项表示在代理a的所有可能选择动作下可以获得的全局Q值的期望。两者之间的差异反映了当前代理选择的动作相对于平均结果的优势。
与原始的单智能体演员-评论家算法相比,COMA策略梯度使用上述反事实优势来优化所有智能体策略:
注意
COMA 使用反事实基线。每个智能体从经过调整的奖励中学习,该奖励将全局奖励与当该智能体的动作被替换为默认动作时获得的奖励进行比较。
扩展¶
COMA 利用学习集中式评论家的优势来训练分散式演员。同样地,Gupta 等人(2017)提出了一种集中式演员-评论家算法,学习每个代理的评论家,以牺牲集中化的好处为代价,选择更好的可扩展性。
MADDPG (Lowe et al. 2017) 在多智能体环境中扩展了DDPG框架,并为每个智能体学习一个集中式评论家。这些方法使用基于策略的策略梯度学习。
COMA-CC (Vasilev et al. 2021) 通过改变其训练方案来改进COMA,使用整个批次的数据,而不是使用具有一致评论家的小批次。COMA-CC是一个带有替代评论家的离策略版本COMA。对于每个反事实Q值计算,COMA评论家需要\(n\)个输入,每个代理一个,而COMA-CC评论家需要\(nm\)个输入,每个代理和反事实联合动作一个。为了减少计算量,连接观察\((z^1_t, ..., z^n_t)\)在用作评论家输入之前通过编码网络进行压缩。
实现¶
默认配置定义如下:
- class ding.policy.coma.COMAPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[源代码]
- Overview:
COMA算法的策略类。COMA是一种多模型强化学习算法
- Interface:
- _init_learn, _data_preprocess_learn, _forward_learn, _reset_learn, _state_dict_learn, _load_state_dict_learn
_init_collect, _forward_collect, _reset_collect, _process_transition, _init_eval, _forward_eval_reset_eval, _get_train_sample, default_model, _monitor_vars_learn
- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
昏迷
POLICY_REGISTRY2
cuda布尔
假
3
on_policy布尔
真
priority布尔
假
5
priority_IS_weight布尔
假
6
learn.update_per_collect整数
1
7
learn.target_update_theta浮点数
0.001
8
learn.discount_factor浮点数
0.99
9
learn.td_lambda浮点数
0.8
10
learn.value_weight浮点数
1.0
11
learn.entropy_weight浮点数
0.01
使用的网络接口COMA定义如下:
- class ding.model.template.coma.COMA(agent_num: int, obs_shape: Dict, action_shape: int | SequenceType, actor_hidden_size_list: SequenceType)[source]
- Overview:
COMA算法的网络,属于QAC类型的演员-评论家。
- Interface:
__init__,forward- Properties:
模式 (
list): 前向模式的列表,包括compute_actor和compute_critic
- forward(inputs: Dict, mode: str) Dict[source]
- Overview:
COMA网络的前向计算图
- Arguments:
输入 (
dict): 输入数据字典,包含键 ['obs', 'prev_state', 'action']agent_state (
torch.Tensor): 每个代理的本地状态(obs)global_state (
torch.Tensor): 全局状态(obs)动作 (
torch.Tensor): 被掩码的动作- ArgumentsKeys:
必要的:
obs{agent_state,global_state,action_mask},action,prev_state- ReturnsKeys:
- necessary:
compute_critic:
q_valuecompute_actor:
logit,next_state,action_mask- Shapes:
obs (
dict):agent_state: \((T, B, A, N, D)\),action_mask: \((T, B, A, N, A)\)prev_state (
list): \([[[h, c] for _ in range(A)] for _ in range(B)]\)logit (
torch.Tensor): \((T, B, A, N, A)\)next_state (
list): \([[[h, c] for _ in range(A)] for _ in range(B)]\)action_mask (
torch.Tensor): \((T, B, A, N, A)\)q_value (
torch.Tensor): \((T, B, A, N, A)\)- Examples:
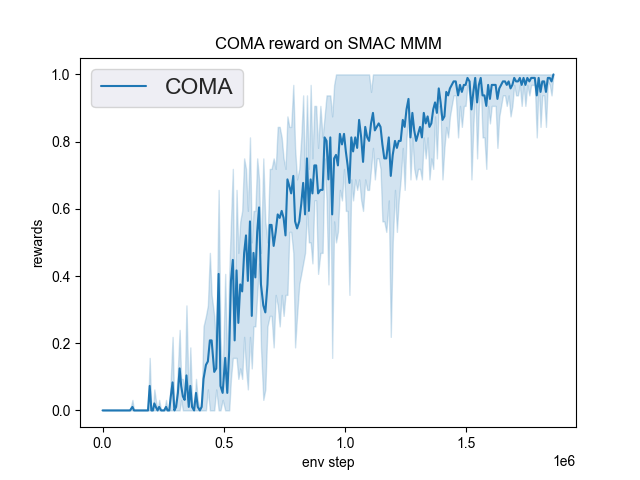
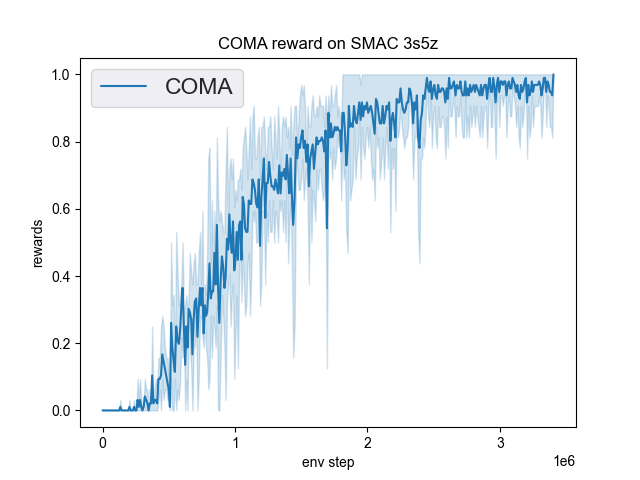
展示了在DI-engine中实现的COMA在SMAC(Samvelyan等人,2019年)中的基准测试结果,用于星际争霸微操问题。
smac 地图 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
MMM |
1.00 |
|
Pymarl(0.1) |
|
3s5z |
1.00 |
|
Pymarl(0.0) |
我们没有展示COMA在5m_vs_6m地图上的性能曲线,因为COMA在这个地图下无法收敛,原作者提出的COMA算法在这个地图下也无法收敛。
参考文献¶
雅各布·福斯特,格雷戈里·法夸尔,特里安塔菲洛斯·阿福拉斯,南塔斯·纳尔代利,西蒙·怀特森。反事实多智能体策略梯度。发表于第三十二届AAAI人工智能会议论文集,2018年。
Jayesh K. Gupta, Maxim Egorov, Mykel Kochenderfer. 使用深度强化学习的协作多智能体控制。国际自主代理和多代理系统会议,2017年。
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, Igor Mordatch. 混合合作-竞争环境中的多智能体演员-评论家方法. arXiv预印本 arXiv:1706.02275, 2017.
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob Foerster, Shimon Whiteson. 星际争霸多智能体挑战. arXiv preprint arXiv:1902.04043, 2019.
Bozhidar Vasilev, Tarun Gupta, Bei Peng, Shimon Whiteson. 半在线训练用于样本高效的多智能体策略梯度。arXiv预印本 arXiv:2104.13446, 2021.