DQfD¶
概述¶
DQfD 是由 DeepMind 在 AAAI 2018 上提出的,详见 Deep Q-learning from Demonstrations。 它首先仅使用演示数据进行预训练,结合了1步TD、n步TD、监督和正则化损失,以便在任务中拥有一个合理的策略,作为学习的良好起点。一旦开始与任务交互,它通过从自生成数据和演示数据中采样来继续学习。 每种类型的数据在每个小批量中的比例由优先回放机制自动控制。
DQfD利用少量的演示数据极大地加速了学习过程,并且在Atari游戏中表现优于PDD DQN、RBS、HER和ADET。
快速事实¶
DQfD 是 DQN 的扩展算法。
将演示存储到专家回放缓冲区中。
使用专家演示预训练网络,并加速后续的强化学习训练过程。
代理收集更多转换以用于新的回放缓冲区(参见detail_explanation)。在新回放缓冲区和专家回放缓冲区的混合上训练网络。
网络使用由四部分组成的特殊损失函数进行训练:一步损失、n步损失、专家大间隔分类损失和L2正则化。
关键方程或关键图表¶
用于更新网络的DQfD总体损失是所有四种损失的组合。
总体损失: \(J(Q) = J_{DQ}(Q) + \lambda_1 J_n(Q) + \lambda_2J_E(Q) + \lambda_3 J_{L2}(Q)\)
一步损失: \(J_{DQ}(Q) = (R(s,a) + \gamma Q(s_{t+1}, a_{t+1}^{max}; \theta^{'}) - Q(s,a;\theta))^2\), 其中 \(a_{t+1}^{max} = argmax_a Q(s_{t+1},a;\theta)\).
n步损失: \(J_n(Q) = r_t + \gamma r_{t+1} + ... + \gamma^{n-1} r_{t+n-1} + max_a \gamma^n Q(s_{t+n},a)\).
大间隔分类损失:\(J_E(Q) = max_{a \in A}[Q(s,a) + L(a_E,a)] - Q(s,a_E)\),\(L(a_E,a)\) 是一个间隔函数,当 \(a = a_E\) 时为 0,否则为正。这种损失迫使其他动作的值至少比演示者动作的值低一个间隔。
L2正则化损失:\(J_{L2}(Q)\) 有助于防止过拟合。
伪代码¶

注意
在第一阶段,代理仅使用演示数据,不进行任何探索。预训练阶段的目标是学习模仿演示者,使用满足贝尔曼方程的价值函数。在此预训练阶段,代理从演示数据中采样小批量数据,并通过应用总损失J(Q)来更新网络。
在第二阶段,代理开始对系统进行操作,收集自生成的数据,并将其添加到其回放缓冲区中。数据被添加到回放缓冲区,直到缓冲区满,然后代理开始覆盖缓冲区中的旧数据。然而,代理从不覆盖演示数据。所有损失都应用于两个阶段的演示数据,而监督损失不应用于自生成的数据。
扩展¶
DeepMind 以多种方式扩展了 DQfD。经过文献搜索,似乎有两个相关的后续工作是:
-
本文的主要思想是通过让许多参与者收集经验来扩大经验回放数据的规模。他们的框架被称为Ape-X,并且他们声称Ape-X DQN在Atari游戏中达到了新的最先进性能。这篇论文与DQfD并不是特别相关,但我们在这里包括它主要是因为后续的一篇论文(见下文)将这种技术与DQfD结合使用。
-
本文提出了Ape-X DQfD算法,正如人们所预期的那样,该算法将DQfD与分布式优先经验回放算法相结合。
实现¶
DI-engine 实现了 DQfD。
DQfD 策略的默认配置定义如下:
- class ding.policy.dqfd.DQFDPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
DQFD算法的策略类,由Double DQN/Dueling DQN/PER/多步TD扩展。
- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
dqn
RL policy register name, refer toregistryPOLICY_REGISTRYThis arg is optional,a placeholder2
cuda布尔
假
Whether to use cuda for networkThis arg can be diff-erent from modes3
on_policy布尔
假
Whether the RL algorithm is on-policyor off-policy4
priority布尔
真
Whether use priority(PER)Priority sample,update priority5
priority_IS_weight布尔
真
Whether use Importance Sampling Weightto correct biased update. If True,priority must be True.6
discount_factor浮点数
0.97, [0.95, 0.999]
Reward’s future discount factor, aka.gammaMay be 1 when sparsereward env7
nstep整数
10, [3, 5]
N-step reward discount sum for targetq_value estimation8
lambda1浮点数
1
multiplicative factor for n-step9
lambda2浮点数
1
multiplicative factor for thesupervised margin loss10
lambda3浮点数
1e-5
L2 loss11
margin_fn浮点数
0.8
margin function in JE, here we setthis as a constant12
per_train_iter_k整数
10
number of pertraining iterations13
learn.updateper_collect整数
3
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingThis args can be varyfrom envs. Bigger valmeans more off-policy14
learn.batch_size整数
64
The number of samples of an iteration15
learn.learning_rate浮点数
0.001
Gradient step length of an iteration.16
learn.target_update_freq整数
100
Frequency of target network update.Hard(assign) update17
learn.ignore_done布尔
假
Whether ignore done for target valuecalculation.Enable it for somefake termination env18
collect.n_sample整数
[8, 128]
The number of training samples of acall of collector.It varies fromdifferent envs19
collect.unroll_len整数
1
unroll length of an iterationIn RNN, unroll_len>1
使用的网络接口DQfD定义如下:
- class ding.model.template.q_learning.DQN(obs_shape: int | SequenceType, action_shape: int | SequenceType, encoder_hidden_size_list: SequenceType = [128, 128, 64], dueling: bool = True, head_hidden_size: int | None = None, head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, dropout: float | None = None, init_bias: float | None = None)[source]
- Overview:
深度Q网络(DQN)算法的神经网络结构和计算图,这是最经典的基于值的离散动作强化学习算法。DQN由两部分组成:
encoder和head。encoder用于从各种观察中提取特征,而head用于计算每个动作维度的Q值。- Interfaces:
__init__,forward.
注意
当前的
DQN支持两种类型的编码器:FCEncoder和ConvEncoder,两种类型的头部:DiscreteHead和DuelingHead。你可以通过继承这个类来自定义你自己的编码器或头部。- __init__(obs_shape: int | SequenceType, action_shape: int | SequenceType, encoder_hidden_size_list: SequenceType = [128, 128, 64], dueling: bool = True, head_hidden_size: int | None = None, head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, dropout: float | None = None, init_bias: float | None = None) None[源代码]
- Overview:
根据相应的输入参数初始化DQN(编码器+头部)模型。
- Arguments:
obs_shape (
Union[int, SequenceType]): 观测空间形状,例如 8 或 [4, 84, 84]。action_shape (
Union[int, SequenceType]): 动作空间形状,例如 6 或 [2, 3, 3]。encoder_hidden_size_list (
SequenceType): 传递给Encoder的hidden_size集合,最后一个元素必须匹配head_hidden_size。决斗 (
Optional[bool]): 是否选择DuelingHead或DiscreteHead (默认)。head_hidden_size (
Optional[int]): 头部网络的hidden_size,默认为None, 然后它将被设置为encoder_hidden_size_list的最后一个元素。head_layer_num (
int): 用于计算Q值输出的头部网络中的层数。activation (
Optional[nn.Module]): 网络中的激活函数类型,如果None则默认设置为nn.ReLU()。norm_type (
Optional[str]): 网络中的归一化类型,详情请参见ding.torch_utils.fc_block。你可以选择 [‘BN’, ‘IN’, ‘SyncBN’, ‘LN’] 中的一个。dropout (
Optional[float]): dropout层的dropout率。如果None,则默认禁用dropout层。init_bias (
Optional[float]): 头部网络中最后一层偏置的初始值。
- forward(x: Tensor) Dict[来源]
- Overview:
DQN 前向计算图,输入观察张量以预测 q_value。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。
- Returns:
输出 (
Dict): DQN前向的输出,包括q_value。
- ReturnsKeys:
logit (
torch.Tensor): 每个可能动作维度的离散Q值输出。
- Shapes:
x (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是obs_shapelogit (
torch.Tensor): \((B, M)\), 其中 B 是批量大小,M 是action_shape
- Examples:
>>> model = DQN(32, 6) # arguments: 'obs_shape' and 'action_shape' >>> inputs = torch.randn(4, 32) >>> outputs = model(inputs) >>> assert isinstance(outputs, dict) and outputs['logit'].shape == torch.Size([4, 6])
注意
为了保持一致性和兼容性,我们将与动作选择相关的网络所有输出命名为
logit。
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
乒乓球 (PongNoFrameskip-v4) |
20 |
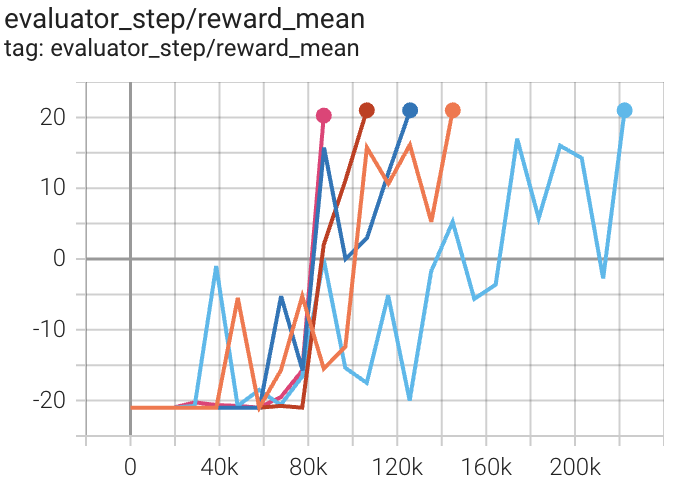
|
||
Qbert (QbertNoFrameskip-v4) |
4976 |
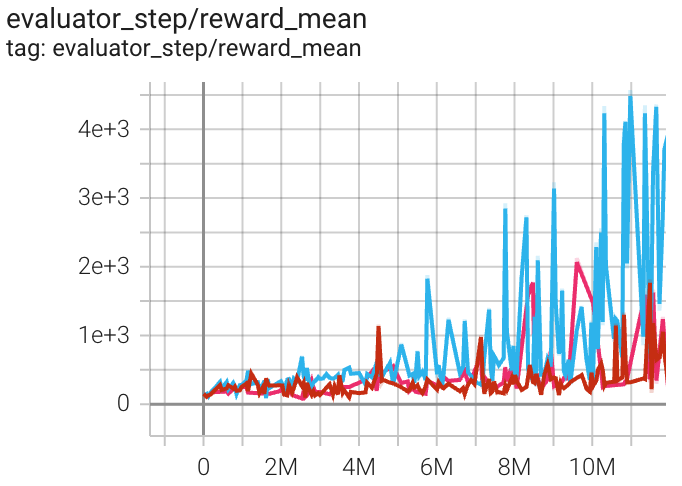
|
||
太空侵略者 (太空侵略者无框架 跳过-v4) |
1969 |
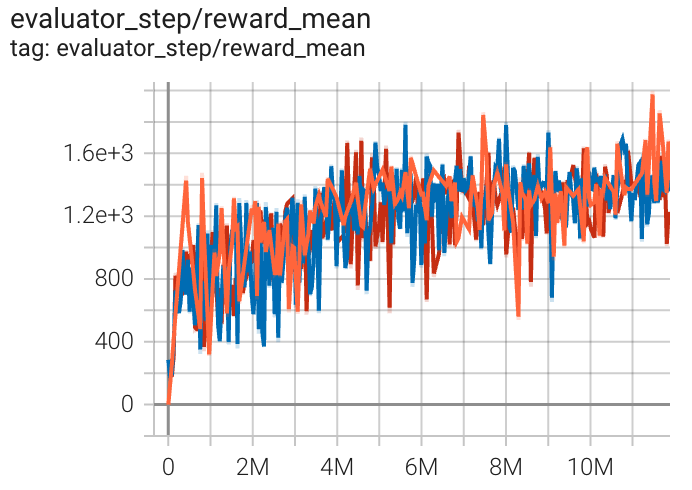
|
参考¶
Hester T, Vecerik M, Pietquin O, 等. 基于演示的深度Q学习[C]//第三十二届AAAI人工智能会议. 2018.