GAIL¶
概述¶
GAIL(生成对抗模仿学习)首次在 生成对抗模仿学习中提出,是一个直接从数据中提取策略的通用框架,就像通过逆向强化学习后的强化学习获得的一样。 作者从占用度量的角度推导了GAIL的优化目标。 与其他学习方法相比,GAIL既不受模仿学习中的复合误差问题的影响,也不需要像逆向强化学习那样昂贵地学习中间奖励函数。但与其他方法类似,GAIL也面临着“维度诅咒”,这使得在高维空间问题中的可扩展性非常有价值。
快速事实¶
GAIL 由一个生成器和一个判别器组成,以对抗的方式进行训练。
生成器针对由判别器提供的替代奖励进行了优化,通常通过策略梯度强化学习方法,如TRPO,因其采样特性。
判别器可以通过典型的梯度下降方法(如Adam)简单地优化,以区分专家数据和生成的数据。
关键方程或关键图表¶
GAIL对抗训练中的目标函数如下:
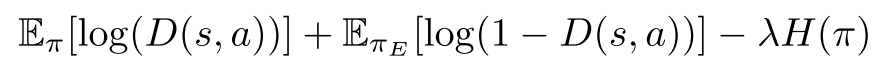
其中pi是生成器策略,D是判别器策略,而\(H(\pi)\)是策略pi的因果熵。这是一个最小-最大优化过程,目标是以迭代对抗的方式进行优化。在训练过程中,D需要最大化目标,而pi需要通过最小化目标来对抗D。
伪代码¶

扩展¶
MAGAIL(多智能体生成对抗模仿学习)
多代理系统往往更加复杂,这是由于多代理之间的异质性、随机性和相互作用。
MAGAIL:多代理生成对抗模仿学习 将GAIL扩展到多代理场景。生成器被重新定义为以分布式方式控制所有代理的策略,而判别器则区分专家并为每个代理生成行为。
伪代码如下:

理解GAIL的其他视角
GAIL 与其他学习方法密切相关,因此可以从不同的角度来理解。
生成对抗网络、逆向强化学习和基于能量的模型之间的联系 指出了GAIL与GAN、IRL以及基于能量的概率估计之间的隐含联系。
实现¶
默认配置定义如下:
- class ding.reward_model.gail_irl_model.GailRewardModel(config: EasyDict, device: str, tb_logger: SummaryWriter)[来源]¶
- Overview:
Gail奖励模型类 (https://arxiv.org/abs/1606.03476)
- Interface:
estimate,train,load_expert_data,collect_data,clear_date,__init__,state_dict,load_state_dict,learn- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
gail
RL policy register name, referto registryPOLICY_REGISTRYthis arg is optional,a placeholder2
expert_data_path字符串
专家数据。 .pkl
Path to the expert datasetShould be a ‘.pkl’file3
learning_rate浮点数
0.001
The step size of gradient descent4
update_per_collect整数
100
Number of updates per collect5
batch_size整数
64
Training batch size6
input_size整数
Size of the input:obs_dim + act_dim7
target_new_data_count整数
64
Collect steps per iteration8
hidden_size整数
128
Linear model hidden size9
collect_count整数
100000
Expert dataset sizeOne entry is a (s,a)tuple10
clear_buffer_per_iters整数
1
clear buffer per fixed itersmake sure replaybuffer’s data countisn’t too few.(code work in entry)
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
专家 |
|---|---|---|---|---|
LunarLander (月球着陆器-v2) |
200 |

|
DQN |
|
BipedalWalker (BipedalWalker-v3) |
300 |
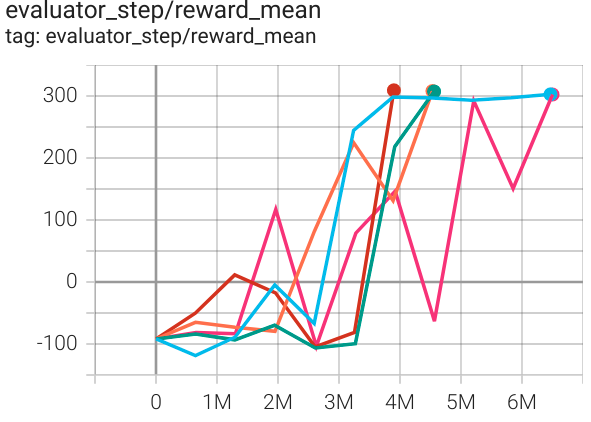
|
SAC |
|
霍珀 (Hopper-v3) |
3500 |
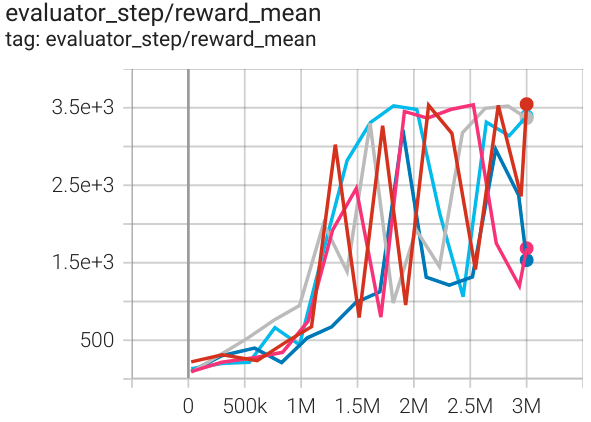
|
SAC |
参考¶
Ho, Jonathan, 和 Stefano Ermon. 利用演示有效解决困难探索问题. [https://arxiv.org/abs/1606.03476 arXiv:1606.03476], 2019.
宋家明等人。多代理生成对抗模仿学习。[https://arxiv.org/abs/1807.09936 arXiv:1807.09936], 2018.
Finn, Chelsea, 等. 生成对抗网络、逆向强化学习和基于能量的模型之间的联系. [https://arxiv.org/abs/1611.03852 arXiv:1611.03852], 2016.