GTrXL¶
概述¶
Gated Transformer-XL,或称为GTrXL,首次在稳定强化学习的Transformer中提出,是一种从Transformer-XL架构改编而来的新颖强化学习框架。它主要引入了两种架构修改,以提高Transformer的稳定性和学习速度,包括:仅在子模块的输入流上放置层归一化,以及用门控层替换残差连接。所提出的架构在具有挑战性的记忆环境中超越了LSTM,并在多个记忆基准测试中取得了最先进的结果,超过了外部记忆架构的性能。
快速事实¶
GTrXL 可以作为许多强化学习算法的骨干。
GTrXL 仅支持顺序观察。
GTrXL 基于 Transformer-XL 并带有 门控连接。
GTrXL 的 DI-engine 实现基于 R2D2 算法。在原始论文中,它基于算法 V-MPO。
关键方程或关键图表¶
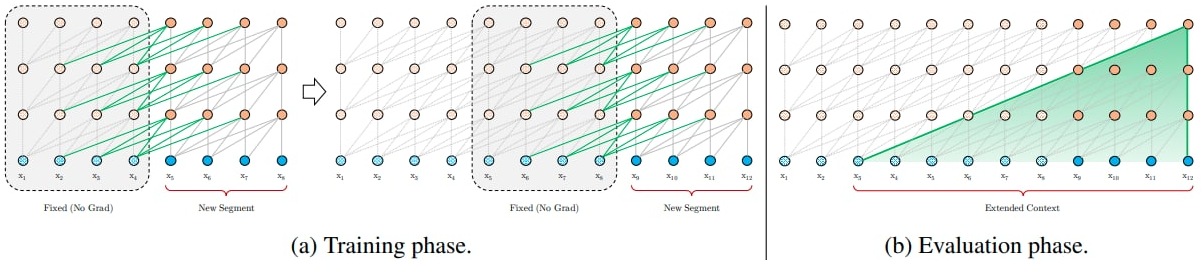
Transformer-XL: 为了解决上下文碎片化问题,Transformer-XL 引入了循环的概念到深度自注意力网络中。 Transformer-XL 不是为每个新片段从头计算隐藏状态,而是重用先前片段中获得的隐藏状态。 重用的隐藏状态作为当前片段的记忆,从而在片段之间建立了循环连接。 因此,由于信息可以通过循环连接传播,建模非常长期的依赖关系成为可能。 为了在不引起时间混淆的情况下启用状态重用,Transformer-XL 提出了一种新的相对位置编码公式,该公式可以推广到比训练期间观察到的更长的注意力长度。
身份映射重排序:将层归一化移动到子模块的输入流中。 这种重排序的一个关键好处是,它现在使得从第一层的变压器输入到最后一层后的变压器输出之间存在一个身份映射。 这与规范变压器形成对比,在规范变压器中,有一系列层归一化操作非线性地变换状态编码。 关于为什么身份映射重排序能改善结果的一个假设如下:假设初始化时子模块产生的值在期望上接近零,状态编码未经变换地传递给策略和价值头,使得代理能够在训练开始时学习马尔可夫策略 (即,网络被初始化使得 \(\pi(·|st,...,s1) ≈ \pi(·|st)\) 和 \(V^\pi(s_t|s_{t-1},...,s_1) ≈ V^\pi(s_t|s_{t-1})\)), 从而忽略了来自注意力-XL记忆的过去观察的贡献。 在许多环境中,反应性行为需要在基于记忆的行为能够有效利用之前被学习。 例如,代理需要先学会如何行走,然后才能学会记住它走过的路径。 通过身份映射重排序,模型的前向传递可以计算为:

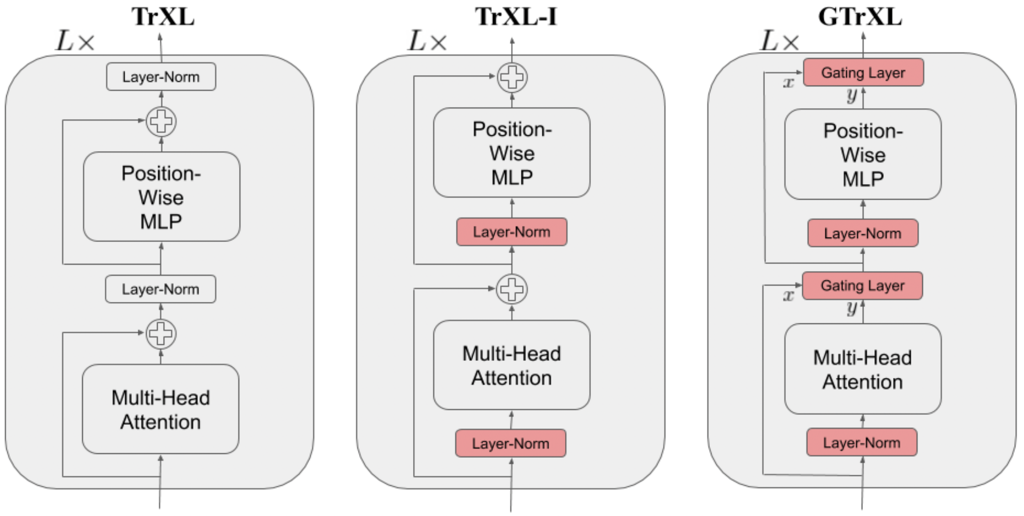
门控层:用门控层替换残差连接。在研究的几种门控函数中,门控循环单元(GRU)表现最佳。 其强大的门控机制可以表示为:
门控身份初始化:作者声称身份映射重排序有助于策略优化,因为它将代理初始化为接近马尔可夫策略或价值函数。 如果这确实是提高稳定性的原因,我们可以显式初始化各种门控机制,使其接近身份映射。 这就是适用门控层中偏置\(b_g^{(l)}\)的目的。作者在消融实验中证明,初始设置\(b_g^{(l)}>0\)会产生最佳结果。
扩展¶
GTrXL 可以与以下内容结合使用:
CoBERL (CoBERL: 对比BERT用于强化学习):
对比BERT(CoBERL)是一种强化学习代理,它结合了新的对比损失和混合LSTM-Transformer架构,以应对提高RL数据效率的挑战。它使用双向掩码预测结合最近对比方法的泛化,来学习RL中Transformer的更好表示,而无需手工设计的数据增强。
R2D2 (分布式强化学习中的循环经验回放):
循环重放分布式DQN(R2D2)展示了如何调整重放和强化学习目标,使其适用于具有循环架构的智能体。LSTM可以被替换或与门控变压器结合,以便我们能够利用分布式经验收集的优势,将循环智能体状态存储在重放缓冲区中,并在训练期间通过重放序列“预热”部分展开的网络。
实现¶
使用的网络接口 GTrXL 定义如下:
- class ding.torch_utils.network.gtrxl.GTrXL(input_dim: int, head_dim: int = 128, embedding_dim: int = 256, head_num: int = 2, mlp_num: int = 2, layer_num: int = 3, memory_len: int = 64, dropout_ratio: float = 0.0, activation: Module = ReLU(), gru_gating: bool = True, gru_bias: float = 2.0, use_embedding_layer: bool = True)[源代码]
- Overview:
GTrXL Transformer 实现,如“Stabilizing Transformer for Reinforcement Learning”中所述 (https://arxiv.org/abs/1910.06764)。
- Interfaces:
__init__,forward,reset_memory,get_memory
- forward(x: Tensor, batch_first: bool = False, return_mem: bool = True) Dict[str, Tensor][source]
- Overview:
在GTrXL上执行前向传递。
- Arguments:
x (
torch.Tensor): 输入张量,形状为 (seq_len, bs, input_size)。batch_first (
bool, 可选): 如果输入数据的形状为 (bs, seq_len, input_size),将此参数设置为 True 以沿第一和第二维度进行转置,并获得形状 (seq_len, bs, input_size)。这不会影响输出内存。默认值为 False。 - return_mem (bool, 可选): 如果为 False,则仅返回输出张量而不返回字典。默认值为 True。
- Returns:
x (
Dict[str, torch.Tensor]): 一个包含形状为 (seq_len, bs, embedding_size) 的transformer输出和形状为 (layer_num, seq_len, bs, embedding_size) 的memory的字典。
- get_memory()[source]
- Overview:
返回GTrXL的内存。
- Returns:
memory (
Optional[torch.Tensor]): 输出的memory,如果memory尚未初始化则为None。形状为(layer_num, memory_len, bs, embedding_dim)。
- reset_memory(batch_size: int | None = None, state: Tensor | None = None)[source]
- Overview:
清除或设置GTrXL的内存。
- Arguments:
batch_size (
Optional[int]): 批量大小。默认值为 None。状态 (
Optional[torch.Tensor]): 输入的记忆,形状为 (层数, 记忆长度, 批次大小, 嵌入维度)。默认值为 None。
我们基于R2D2的GTrXL的默认实现定义如下:
- class ding.policy.r2d2_gtrxl.R2D2GTrXLPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
R2D2的策略类采用Transformer架构GTrXL作为骨干。
- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
r2d2_gtrxl
RL policy register name, refer toregistryPOLICY_REGISTRYThis arg is optional,a placeholder2
cuda布尔
假
Whether to use cuda for networkThis arg can be diff-erent from modes3
on_policy布尔
假
Whether the RL algorithm is on-policyor off-policy4
priority布尔
假
Whether use priority(PER)Priority sample,update priority5
priority_IS_weight布尔
假
Whether use Importance Sampling Weightto correct biased update. If True,priority must be True.6
discount_factor浮点数
0.99, [0.95, 0.999]
Reward’s future discount factor, aka.gammaMay be 1 when sparsereward env7
nstep整数
5, [3, 5]
N-step reward discount sum for targetq_value estimation8
burnin_step整数
1
The timestep of burnin operation,which is designed to warm-up GTrXLmemory difference caused by off-policy9
learn.updateper_collect整数
1
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingThis args can be varyfrom envs. Bigger valmeans more off-policy10
learn.batch_size整数
64
The number of samples of an iteration11
learn.learning_rate浮点数
0.001
Gradient step length of an iteration.12
learn.value_rescale布尔
真
Whether use value_rescale function forpredicted value13
learn.target_update_freq整数
100
Frequence of target network update.Hard(assign) update14
learn.ignore_done布尔
假
Whether ignore done for target valuecalculation.Enable it for somefake termination env15
collect.n_sample整数
[8, 128]
The number of training samples of acall of collector.It varies fromdifferent envs16
collect.seq_len整数
20
Training sequence lengthunroll_len>=seq_len>117
learn.init_memory字符串
零
‘zero’ or ‘old’, how to initialize thememory before each training iteration.
- _data_preprocess_learn(data: List[Dict[str, Any]]) dict[source]
- Overview:
预处理数据以适应学习所需的格式
- Arguments:
数据 (
List[Dict[str, Any]]): 从收集函数中收集的数据
- Returns:
- data (
Dict[str, Any]): the processed data, including at least [‘main_obs’, ‘target_obs’, ‘burnin_obs’, ‘action’, ‘reward’, ‘done’, ‘weight’]
- data (
data_info (
dict): 数据信息,例如 replay_buffer_idx, replay_unique_id
- _forward_learn(data: dict) Dict[str, Any][来源]
- Overview:
学习模式的前向和后向函数。 获取数据,计算损失并优化学习器模型。
- Arguments:
- data (
dict): Dict type data, including at least [‘main_obs’, ‘target_obs’, ‘burnin_obs’, ‘action’, ‘reward’, ‘done’, ‘weight’]
- data (
- Returns:
- info_dict (
Dict[str, Any]): Including cur_lr and total_loss cur_lr (
float): 当前学习率total_loss (
float): 计算出的损失
- info_dict (
- _init_learn() None[source]
- Overview:
初始化GTrXLR2D2Policy的学习者模型。目标模型有2个包装器:'target'用于权重更新,'transformer_segment'用于将轨迹分割成段。学习模型有2个包装器:'argmax'用于选择最佳动作,'transformer_segment'。
- Arguments:
learning_rate (
float): 优化器的学习率gamma (
float): 折扣因子nstep (
int): n步返回的数量value_rescale (
bool): 是否在算法中使用值重新缩放的损失burnin_step (
int): 预热步骤的数量seq_len (
int): 训练序列长度init_memory (
str): ‘zero’ 或 ‘old’,每次训练迭代前如何初始化内存。
注意
_init_learn方法从配置文件中的 self._cfg.learn 获取参数
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
乒乓球 (PongNoFrameskip-v4) |
20 |

|
附注:
上述结果是通过在五个不同的随机种子(0, 1, 2, 3, 4)上运行相同的配置获得的
对于像DQN这样的离散动作空间算法,通常使用Atari环境集进行测试(包括子环境Pong),并且Atari环境通常通过最高平均奖励训练10M
env_step来评估。有关Atari的更多详细信息,请参阅Atari环境教程。
参考¶
Parisotto, Emilio, 等人. “稳定强化学习的变压器。”, 2019; [http://arxiv.org/abs/1910.06764 arXiv:1910.06764]
戴子航等人。“Transformer-XL:超越固定长度上下文的注意力语言模型。”,2019年;[http://arxiv.org/abs/1901.02860 arXiv:1901.02860]