HER¶
概述¶
HER(Hindsight Experience Replay)最初在Hindsight Experience Replay中提出,用于应对由稀疏奖励带来的挑战。HER可以轻松地与任何离策略强化学习算法结合,允许从稀疏且二元的奖励中进行高效样本学习,从而避免了复杂的奖励工程需求。
HER的核心是从失败中学习。HER提出,即使任务的最终目标没有实现,这一过程仍然有用,因为在此过程中可能会实现其他目标。因此,HER从原始过程中创建一个新的过程,通过改变期望的任务目标来为新过程标记新的奖励。
快速事实¶
HER 不是一个独立的算法,它可以与任何离策略算法结合使用。
HER 需要在改变期望目标后定义奖励,但它不需要与环境中的奖励函数相同。
在DI-engine的实现中,HER收集回合数据并将其推入缓冲区,然后对回合进行采样并修改奖励,这将在伪代码部分详细解释。
HER 有不同的策略来创建虚拟目标。它们都来自与正在重放的转换相同的片段,但有以下不同之处:
未来:转换后的状态
episode: 剧集中的任何状态
final: 剧集的最终状态
伪代码¶

注意
与原始论文中提出的伪代码相比,DI-engine采用了一种略有不同的方式来实现HER。在原始论文中,在将转换推入缓冲区之前,它将用于创建几个具有不同目标的转换。然而,这有两个缺点:1)内存浪费。所有转换(原始的和虚拟的)都存储在缓冲区中。2)固定数据集。一旦转换被推入缓冲区,它们将不会被更改。
因此,在DI-engine中,我们首先将原始转换(以完整剧集格式)推入缓冲区。在剧集被采样出来后,我们将开始基于虚拟目标创建更多的转换。目标在每次采样时随机创建,因此即使同一剧集被多次采样出来,创建的新训练数据也不会相同。
实现¶
DI-engine 中的实现不在 ding.policy 中,像许多其他算法一样,而是在 ding.reward_model.her_reward_model 中:
- class ding.reward_model.her_reward_model.HerRewardModel(cfg: dict, cuda: bool = False)[源代码]
- Overview:
后见之明经验回放模型。
注意
her_strategy (
str): HER使用的策略类型,应在[‘final’, ‘future’, ‘episode’]中her_replay_k (
int): 由原始情节生成的新情节的数量。(在情节HER中未使用)episode_size (
int): 每次迭代中采样多少个episode。sample_per_episode (
int): 每集生成多少新样本。
注意
在HER中,我们需要通过改变目标来调整情节轨迹。然而,情节的长度各不相同,可能会有很大的差异。因此,我们建议您通过在配置中指定
episode_size和sample_per_episode,仅使用完整情节中的一些转换。因此,在一次迭代中,batch_size将是episode_size*sample_per_episode。
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
|---|---|---|---|
BitFLip-15位 |
0.9 |
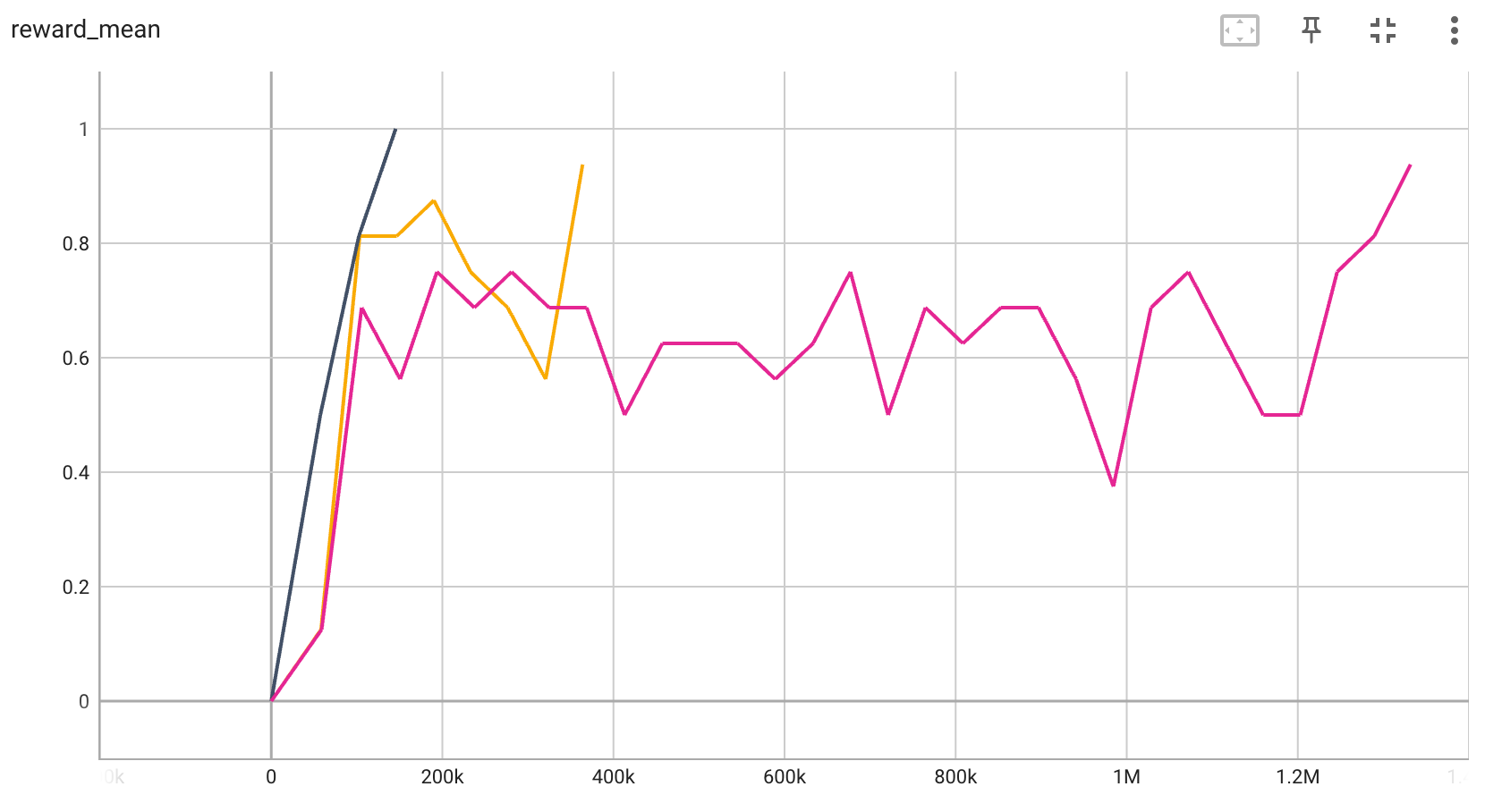
|
|
BitFLip-20位 |
0.9 |
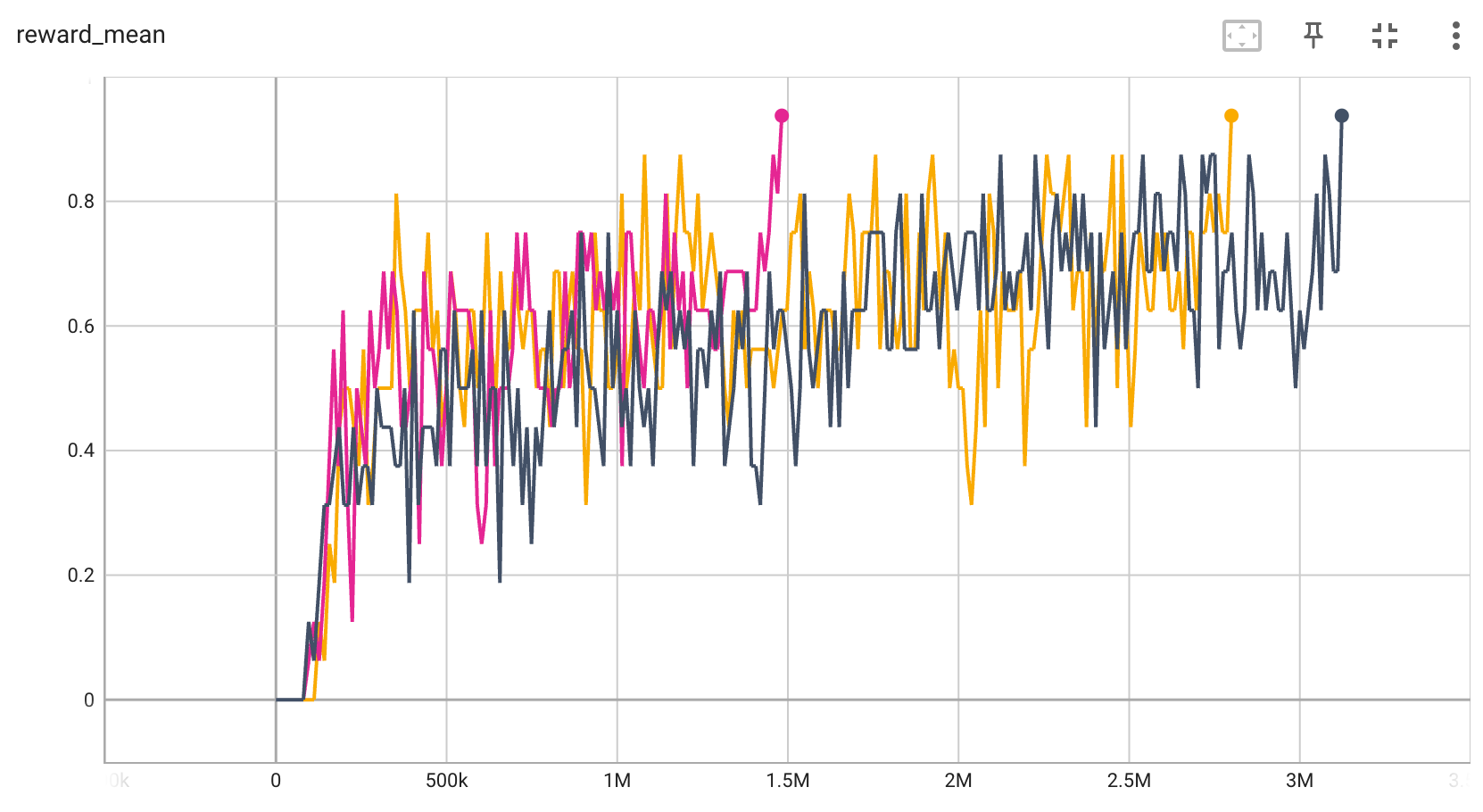
|
附注。
上述结果是通过在3个不同的随机种子(0, 1, 2)上运行相同的配置获得的
参考¶
Andrychowicz M, Wolski F, Ray A, 等. 后见之明经验回放[J]. arXiv 预印本 arXiv:1707.01495, 2017.