PPG¶
概述¶
PPG 是在 Phasic Policy Gradient 中提出的。在以前的方法中,人们需要选择表示策略和价值函数是否需要分开训练还是共享全局信息。分开训练可以避免目标之间的干扰,而使用共享全局信息可以实现有用特征的共享。PPG 能够兼顾两者的优点,通过将优化分为两个阶段,一个用于推进训练,另一个用于提取特征。
核心要点¶
PPG 是一种无模型、基于策略的强化学习算法。
PP 支持离散动作空间和连续动作空间。
PPG 支持离策略模式和在策略模式。
PPG 中有两个价值网络。
在 DI-engine 的实现中,我们对离策略PPG使用了两个缓冲区,它们仅在数据使用次数约束(数据 “max_use” )上有所不同。
重要图示¶
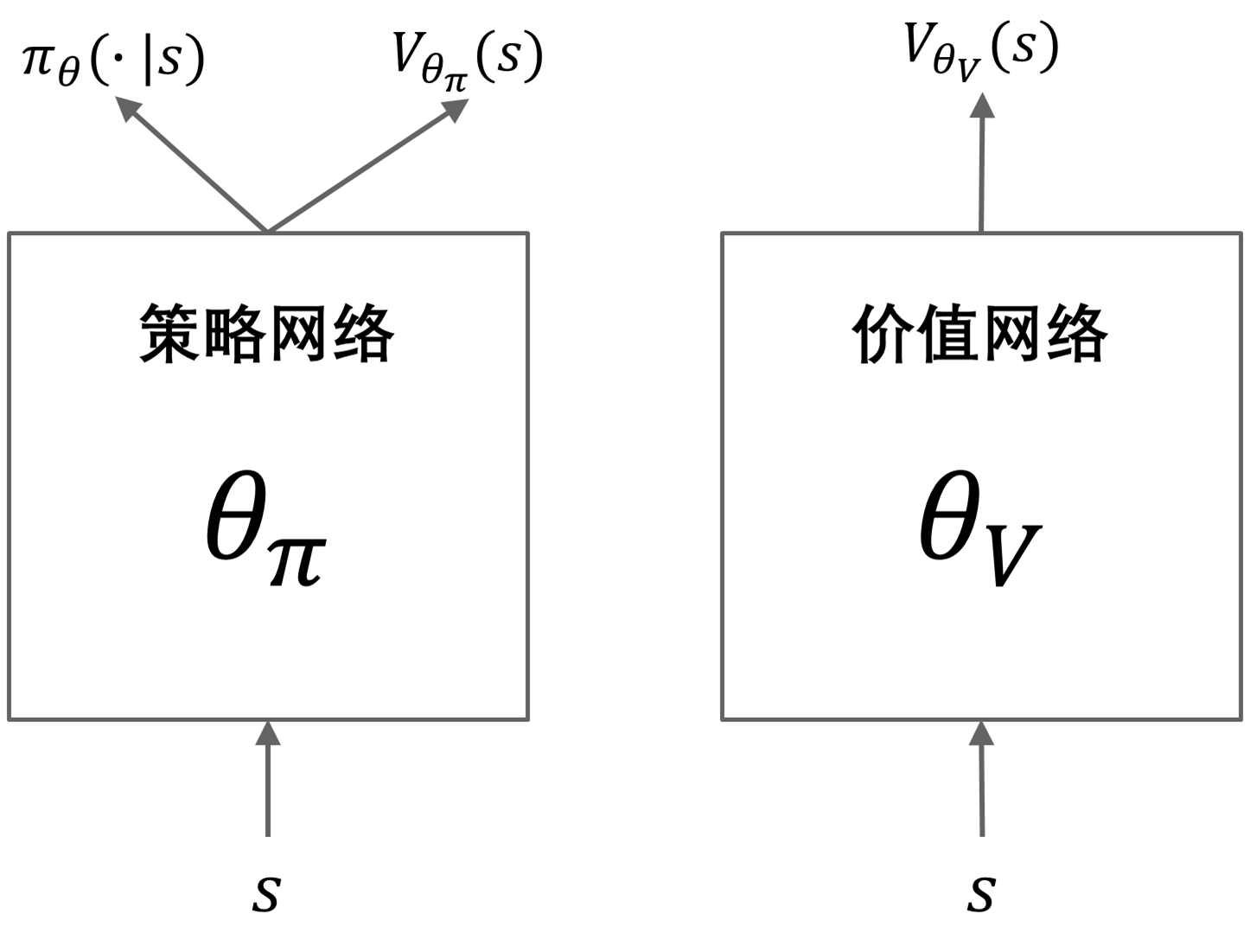
PPG 利用分开的策略和价值网络来减少目标之间的干扰。策略网络包括一个辅助价值头部网络,用于将价值知识提取到策略网络中,具体的网络结构如下所示:
重要公式¶
PPG 的优化分为两个阶段,策略阶段和辅助阶段。在策略阶段,策略网络和价值网络的更新方式类似于 PPO。在辅助阶段,使用联合损失将价值知识提取到策略网络中:
联合损失函数优化辅助目标(蒸馏),同时通过 KL 散度限制(即第二项)保留原始策略。辅助损失定义如下:
伪代码¶
on-policy 训练流程¶
以下流程图展示了 PPG 如何在策略阶段和辅助阶段之间进行交替

注意
在辅助阶段,PPG 还会对值网络进行额外的训练。
off-policy 训练流程¶
DI-engine 实现了采用两个不同数据使用次数约束(”max_use”)缓冲区的 PPG。其中,策略缓冲区提供策略阶段的数据,而值缓冲区提供辅助阶段的数据。整个训练过程类似于 off-policy PPO,但会以固定频率执行额外的辅助阶段。
扩展¶
PPG 可以与以下方法结合使用:
GAE 或其他优势估计方法
多个具有不同的最大数据使用次数限制的回访缓存
在 procgen 环境中,PPO(或 PPG)+ UCB-DrAC + PLR 是最好的方法之一。
实现¶
默认配置如下所示:
- class ding.policy.ppg.PPGPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
PPG算法的策略类。PPG是一种带有辅助阶段训练的梯度策略算法。辅助阶段训练旨在将价值提炼到策略网络中,同时确保策略网络不改变动作预测(kl散度损失)。论文链接:https://arxiv.org/abs/2009.04416。
- Interface:
_init_learn,_data_preprocess_learn,_forward_learn,_state_dict_learn,_load_state_dict_learn,_init_collect,_forward_collect,_process_transition,_get_train_sample,_get_batch_size,_init_eval,_forward_eval,default_model,_monitor_vars_learn,learn_aux.- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
ppg
RL policy register name, refer toregistryPOLICY_REGISTRYthis arg is optional,a placeholder2
cuda布尔
假
Whether to use cuda for networkthis arg can be diff-erent from modes3
on_policy布尔
真
Whether the RL algorithm is on-policyor off-policypriority布尔
假
Whether use priority(PER)priority sample,update priority5
priority_IS_weight布尔
假
Whether use Importance SamplingWeight to correct biased update.IS weight6
learn.update_per_collect整数
5
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingthis args can be varyfrom envs. Bigger valmeans more off-policy7
learn.value_weight浮点数
1.0
The loss weight of value networkpolicy network weightis set to 18
learn.entropy_weight浮点数
0.01
The loss weight of entropyregularizationpolicy network weightis set to 19
learn.clip_ratio浮点数
0.2
PPO clip ratio10
learn.adv_norm布尔
假
Whether to use advantage norm ina whole training batch11
learn.aux_freq整数
5
The frequency(normal update times)of auxiliary phase training12
learn.aux_train_epoch整数
6
The training epochs of auxiliaryphase13
learn.aux_bc_weight整数
1
The loss weight of behavioral_cloningin auxiliary phase14
collect.discount_factor浮点数
0.99
Reward’s future discount factor, aka.gammamay be 1 when sparsereward env15
collect.gae_lambda浮点数
0.95
GAE lambda factor for the balanceof bias and variance(1-step td and mc)
PPG 使用的网络定义如下:
- class ding.model.template.ppg.PPG(obs_shape: int | SequenceType, action_shape: int | SequenceType, action_space: str = 'discrete', share_encoder: bool = True, encoder_hidden_size_list: SequenceType = [128, 128, 64], actor_head_hidden_size: int = 64, actor_head_layer_num: int = 2, critic_head_hidden_size: int = 64, critic_head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, impala_cnn_encoder: bool = False)[source]
- Overview:
来自论文Phasic Policy Gradient的Phasic Policy Gradient (PPG)模型 https://arxiv.org/abs/2009.04416 该模块包含VAC模块和一个辅助评论模块。
- Interfaces:
forward,compute_actor,compute_critic,compute_actor_critic
- compute_actor(x: Tensor) Dict[source]
- Overview:
使用actor计算动作的logits。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。
- Returns:
输出 (
Dict): 包含动作逻辑的输出数据。
- ReturnsKeys:
logit (
torch.Tensor): 预测的动作logit张量,对于离散动作空间,它将是相同维度的实值范围张量,表示可能的动作选择,而对于连续动作空间,它将是高斯分布的mu和sigma,mu和sigma的数量与连续动作的数量相同。混合动作空间是离散和连续动作空间的一种组合,因此logit将是一个包含action_type和action_args的字典。
- Shapes:
x (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是输入特征大小。输出 (
Dict):logit: \((B, A)\), 其中 B 是批量大小,A 是动作空间大小。
- compute_actor_critic(x: Tensor) Dict[来源]
- Overview:
使用actor和critic来计算动作的logits和值。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。
- Returns:
输出 (
Dict): PPG前向计算图的输出字典,包括演员和评论家,包含logit和value。
- ReturnsKeys:
logit (
torch.Tensor): 预测的动作logit张量,对于离散动作空间,它将是相同维度的实值范围张量,表示可能的动作选择,而对于连续动作空间,它将是高斯分布的mu和sigma,mu和sigma的数量与连续动作的数量相同。混合动作空间是离散和连续动作空间的一种组合,因此logit将是一个包含action_type和action_args的字典。值 (
torch.Tensor): 预测的状态值张量。
- Shapes:
x (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是输入特征大小。输出 (
Dict):value: \((B, 1)\), 其中 B 是批量大小。输出 (
Dict):logit: \((B, A)\), 其中 B 是批量大小,A 是动作空间大小。
注意
compute_actor_critic接口旨在在共享编码器时节省计算。
- compute_critic(x: Tensor) Dict[source]
- Overview:
使用critic来计算值。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。
- Returns:
输出 (
Dict): VAC前向计算图的输出字典,包括value。
- ReturnsKeys:
必要的:
value
- Shapes:
x (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是输入特征大小。输出 (
Dict):value: \((B, 1)\), 其中 B 是批量大小。
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
Pong
(PongNoFrameskip-v4)
|
20 |

|
DI-engine PPO off-policy(20)
|
|
Qbert
(QbertNoFrameskip-v4)
|
17775 |
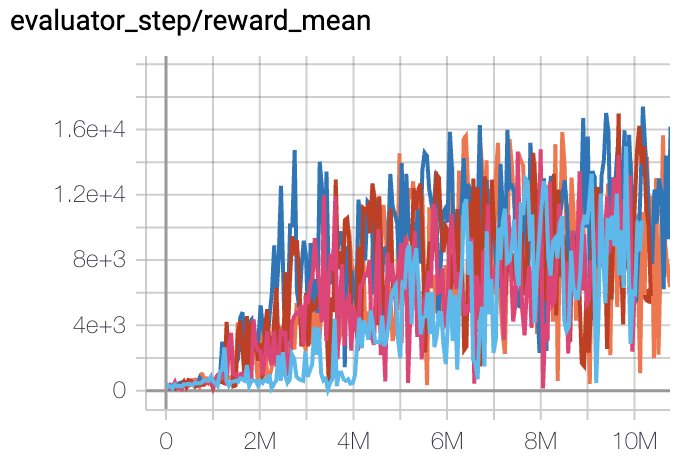
|
DI-engine PPO off-policy(16400)
|
|
SpaceInvaders
(SpaceInvadersNoFrame skip-v4)
|
1213 |
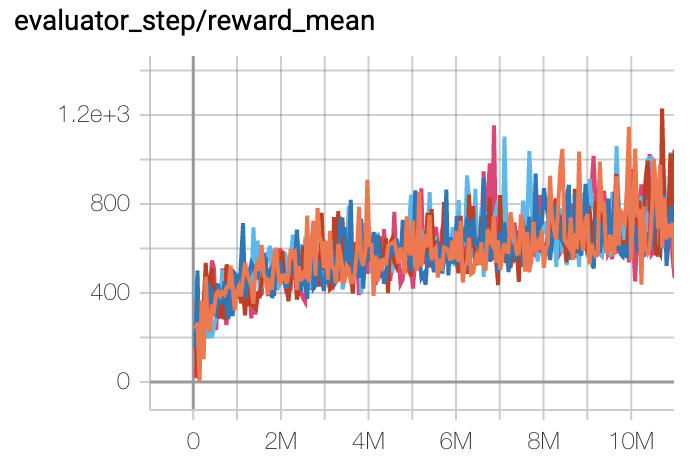
|
DI-engine PPO off-policy(1200)
|
引用¶
Karl Cobbe, Jacob Hilton, Oleg Klimov, John Schulman: “阶段性策略梯度”, 2020; arXiv:2009.04416.