PPO¶
概述¶
PPO(近端策略优化)是在近端策略优化算法中提出的。 关键问题是如何利用现有数据采取最可能的改进步骤来优化策略,而不会意外导致性能崩溃。 PPO遵循TRPO的思想(通过显式的KL散度约束限制策略更新的步骤), 但在目标函数中没有KL散度项, 而是利用专门的裁剪目标来消除新策略远离旧策略的动机。 PPO避免了TRPO中Hessian矩阵的计算,因此实现更简单,并且在经验上至少与TRPO表现相当。
快速事实¶
PPO 是一种无模型和策略梯度的强化学习算法。
PPO支持离散和连续动作空间。
PPO支持离策略模式和在策略模式。
PPO 可以配备 RNN。
PPO 是一种一阶梯度方法,它使用一些技巧来保持新策略接近旧策略。
关键方程或关键图表¶
PPO 在策略梯度中使用裁剪的概率比率,以防止策略变化过快,具体来说,优化目标是:
其中 \(\frac{\pi_{\theta}(a \mid s)}{\pi_{\theta_{k}}(a \mid s)}\) 被称为概率比 \(r_t(\theta)\), \(\theta\) 是当前需要优化的策略参数,\(\theta_k\) 是第k次迭代时的策略参数,\(\gamma\) 是一个小的超参数控制,用于控制策略参数的最大更新步长。
根据这个笔记,PPO-Clip目标可以简化为:
其中,
通常我们无法访问采样状态-动作对 \((s,a)\) 的真实优势值,但幸运的是我们可以计算一个近似值 \(\hat{A}_t\)。 这个裁剪目标背后的思想是:对于 \((s,a)\),如果 \(\hat{A}_t < 0\),最大化 \(L^{C L I P}(\theta)\) 意味着使 \(\pi_{\theta}(a_{t} \mid s_{t})\) 变小,但使 \(\pi_{\theta}(a_{t} \mid s_{t})\) 小于 \((1-\epsilon)\pi_{\theta}(a_{t} \mid s_{t})\) 不会为目标函数带来额外的好处。 类似地,如果 \(\hat{A}_t > 0\),最大化 \(L^{C L I P}(\theta)\) 意味着使 \(\pi_{\theta}(a_{t} \mid s_{t})\) 变大,但使 \(\pi_{\theta}(a_{t} \mid s_{t})\) 大于 \((1+\epsilon)\pi_{\theta}(a_{t} \mid s_{t})\) 不会带来额外的好处。 经验表明,通过优化这个目标函数,策略网络的更新步骤可以控制在合理的范围内。
对于价值函数,为了平衡价值学习中的偏差和方差,PPO采用了广义优势估计器来计算优势,这是贝尔曼残差项的指数加权和,类似于TD(λ):
其中 V 是一个近似值函数,\(\delta_{t}=r_{t}+\gamma V\left(s_{t+1}\right)-V\left(s_{t}\right)\) 是贝尔曼残差项,或在时间步 t 称为 TD 误差。
目标值的计算方式为:\(V_{t}^{target}=V_{t}+\hat{A}_{t}\), 而价值损失被定义为平方误差:\(\frac{1}{2}*\left(V_{\theta}\left(s_{t}\right)-V_{t}^{\mathrm{target}}\right)^{2}\), 为了确保充分的探索,PPO通过添加策略熵奖励来进一步增强目标。
总PPO损失是策略损失、价值损失和策略熵正则化项的加权和:
其中c1和c2是控制不同项相对重要性的系数。
注意
PPO的标准实现包含了许多论文中未描述的额外优化。更多详细信息可以在IMPLEMENTATION MATTERS IN DEEP POLICY GRADIENTS: A CASE STUDY ON PPO AND TRPO中找到。
伪代码¶

注意
这是PPO的策略内版本。在DI-engine中,我们也有PPO的策略外版本,它与策略内PPO几乎相同,除了 我们维护了一个存储最近经验的回放缓冲区, 用于计算PPO损失的数据是从回放缓冲区中采样,而不是从最近收集的批次中采样, 因此策略外PPO能够非常高效地重用旧数据,但可能脆弱且不稳定。
扩展¶
实现¶
默认配置定义如下:
- class ding.policy.ppo.PPOPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[源代码]¶
- Overview:
策略类中的on-policy版本PPO算法。论文链接:https://arxiv.org/abs/1707.06347。
- class ding.model.template.vac.VAC(obs_shape: int | SequenceType, action_shape: int | SequenceType | EasyDict, action_space: str = 'discrete', share_encoder: bool = True, encoder_hidden_size_list: SequenceType = [128, 128, 64], actor_head_hidden_size: int = 64, actor_head_layer_num: int = 1, critic_head_hidden_size: int = 64, critic_head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, sigma_type: str | None = 'independent', fixed_sigma_value: int | None = 0.3, bound_type: str | None = None, encoder: Module | None = None, impala_cnn_encoder: bool = False)[source]
- Overview:
与(状态)值演员-评论家(VAC)相关的算法的神经网络和计算图,例如A2C/PPO/IMPALA。该模型现在支持离散、连续和混合动作空间。VAC由四部分组成:
actor_encoder、critic_encoder、actor_head和critic_head。编码器用于从各种观察中提取特征。头部用于预测相应的值或动作逻辑。在高维观察空间(如2D图像)中,我们通常为actor_encoder和critic_encoder使用共享编码器。在低维观察空间(如1D向量)中,我们通常使用不同的编码器。- Interfaces:
__init__,forward,compute_actor,compute_critic,compute_actor_critic.
- compute_actor(x: Tensor) Dict[source]
- Overview:
VAC 前向计算图用于演员部分,输入观察张量以预测动作逻辑值。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。- Returns:
输出 (
Dict): VAC前向计算图的输出字典,包括logit。- ReturnsKeys:
logit (
torch.Tensor): 预测的动作logit张量,对于离散动作空间,它将是相同维度的实值范围张量,表示可能的动作选择,而对于连续动作空间,它将是高斯分布的mu和sigma,mu和sigma的数量与连续动作的数量相同。混合动作空间是离散和连续动作空间的一种组合,因此logit将是一个包含action_type和action_args的字典。- Shapes:
logit (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是action_shape- Examples:
- compute_actor_critic(x: Tensor) Dict[来源]
- Overview:
VAC 前向计算图,包括演员和评论家部分,输入观察张量以预测动作 logit 和状态值。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。- Returns:
输出 (
Dict): VAC前向计算图的输出字典,包括演员和评论家,包含logit和value。- ReturnsKeys:
logit (
torch.Tensor): 预测的动作logit张量,对于离散动作空间,它将是相同维度的实值范围张量,表示可能的动作选择,而对于连续动作空间,它将是高斯分布的mu和sigma,mu和sigma的数量与连续动作的数量相同。混合动作空间是离散和连续动作空间的一种组合,因此logit将是一个包含action_type和action_args的字典。值 (
torch.Tensor): 预测的状态值张量。- Shapes:
logit (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是action_shape值 (
torch.Tensor): \((B, )\), 其中 B 是批量大小,(B, 1) 被压缩为 (B, )。- Examples:
注意
compute_actor_critic接口旨在在共享编码器时节省计算,并返回组合的字典输出。
- compute_critic(x: Tensor) Dict[source]
- Overview:
VAC 前向计算图用于评论家部分,输入观察张量以预测状态值。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。- Returns:
输出 (
Dict): VAC前向计算图的输出字典,包括value。- ReturnsKeys:
值 (
torch.Tensor): 预测的状态值张量。- Shapes:
值 (
torch.Tensor): \((B, )\), 其中 B 是批量大小,(B, 1) 被压缩为 (B, )。- Examples:
- forward(x: Tensor, mode: str) Dict[source]
- Overview:
VAC前向计算图,输入观测张量以预测状态值或动作对数。不同的
mode将使用不同的网络模块进行前向传播,以获得不同的输出并节省计算。- Arguments:
x (
torch.Tensor): 输入的观测张量数据。模式 (
str): 前向模式,所有模式都在这个类的开头定义。- Returns:
输出 (
Dict): VAC前向计算图的输出字典,其键值因不同的mode而异。- Examples (Actor):
- Examples (Critic):
- Examples (Actor-Critic):
PPO的策略损失和价值损失实现如下:
def ppo_error(
data: namedtuple,
clip_ratio: float = 0.2,
use_value_clip: bool = True,
dual_clip: Optional[float] = None
) -> Tuple[namedtuple, namedtuple]:
assert dual_clip is None or dual_clip > 1.0, "dual_clip value must be greater than 1.0, but get value: {}".format(
dual_clip
)
logit_new, logit_old, action, value_new, value_old, adv, return_, weight = data
policy_data = ppo_policy_data(logit_new, logit_old, action, adv, weight)
policy_output, policy_info = ppo_policy_error(policy_data, clip_ratio, dual_clip)
value_data = ppo_value_data(value_new, value_old, return_, weight)
value_loss = ppo_value_error(value_data, clip_ratio, use_value_clip)
return ppo_loss(policy_output.policy_loss, value_loss, policy_output.entropy_loss), policy_info
ppo_policy_error 和 ppo_value_error 的接口定义如下:
- ding.rl_utils.ppo.ppo_policy_error(data: namedtuple, clip_ratio: float = 0.2, dual_clip: float | None = None) Tuple[namedtuple, namedtuple][source]¶
- Overview:
获取PPO策略损失
- Arguments:
数据 (
namedtuple): ppo 输入数据,包含ppo_policy_data中显示的字段clip_ratio (
float): 比率的裁剪值dual_clip (
float): 在arXiv:1912.09729 公式5中提到的参数c,应在[1, inf)范围内,默认值为5.0,如果你不想使用它,将此参数设置为None- Returns:
ppo_policy_loss (
namedtuple): PPO策略损失项,所有这些都是可微的0维张量ppo_info (
namedtuple): 用于监控的ppo优化信息,所有信息都是Python标量- Shapes:
logit_new (
torch.FloatTensor): \((B, N)\), 其中 B 是批量大小,N 是动作维度logit_old (
torch.FloatTensor): \((B, N)\)动作 (
torch.LongTensor): \((B, )\)adv (
torch.FloatTensor): \((B, )\)权重 (
torch.FloatTensor或None): \((B, )\)policy_loss (
torch.FloatTensor): \(()\), 0维张量entropy_loss (
torch.FloatTensor): \(()\)- Examples:
- ding.rl_utils.ppo.ppo_value_error(data: namedtuple, clip_ratio: float = 0.2, use_value_clip: bool = True) Tensor[source]¶
- Overview:
获取PPO值损失
- Arguments:
数据 (
namedtuple): ppo 输入数据,包含ppo_value_data中显示的字段clip_ratio (
float): 比率的裁剪值use_value_clip (
bool): 是否使用值裁剪- Returns:
value_loss (
torch.FloatTensor): PPO值损失项,所有这些都是可微的0维张量- Shapes:
value_new (
torch.FloatTensor): \((B, )\), 其中 B 是批量大小value_old (
torch.FloatTensor): \((B, )\)返回 (
torch.FloatTensor): \((B, )\)权重 (
torch.FloatTensor或None): \((B, )\)value_loss (
torch.FloatTensor): \(()\), 0维张量- Examples:
实现技巧¶
技巧 |
解释 |
|---|---|
Utilizing generalized advantage estimator to balance bias and variance in value learning.
|
|
the authors claim that when \(\hat{A}_t < 0\), a too large \(r_t(\theta)\) should also be clipped, which introduces dual clip:
\(\max \left(\min \left(r_{t}(\theta) \hat{A}_{t}, {clip}\left(r_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right), c \hat{A}_{t}\right)\)
|
|
In on-policy PPO, each time we collect a batch data, we will train many epochs to improve data efficiency.
And before the beginning of each training epoch, we recompute the advantage of historical transitions,
to keep the advantage is an approximate evaluation of current policy.
|
|
We standardize the targets of the value/advantage function using running estimates of the average
and standard deviation of the value/advantage targets. For more implementation details about
recompute advantage and normalization, users can refer to this discussion.
|
|
Value is clipped around the previous value estimates. We use the value clip_ratio same as that used to clip policy
probability ratios in the PPO policy loss function.
|
|
Using an orthogonal initialization scheme for the policy and value networks.
|
基准测试¶
离策略PPO基准测试:
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
乒乓球 (PongNoFrameskip-v4) |
20 |
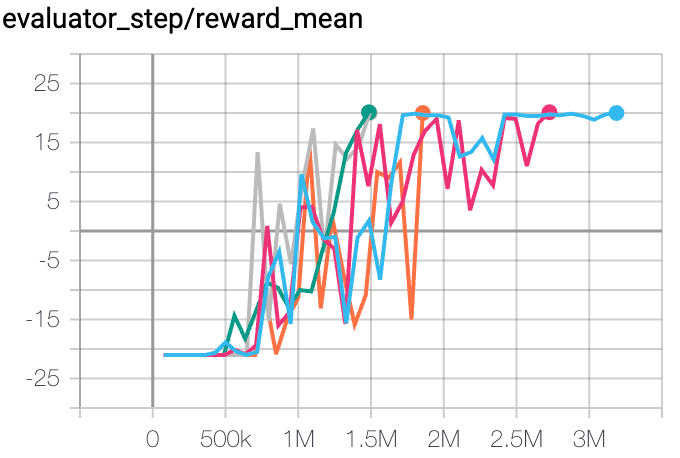
|
||
Qbert (QbertNoFrameskip-v4) |
16400 |
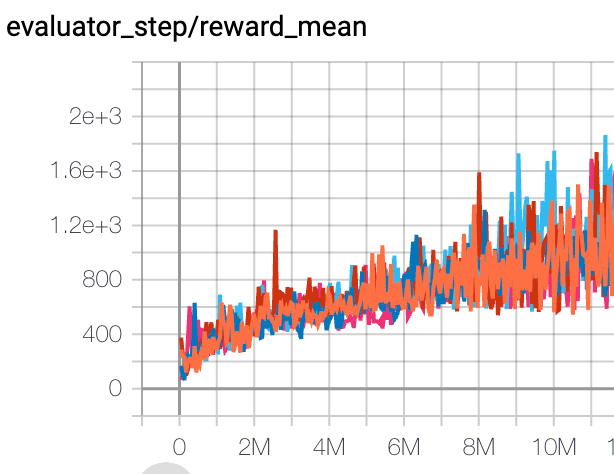
|
||
太空侵略者 (SpaceInvadersNoFrame skip-v4) |
1200 |
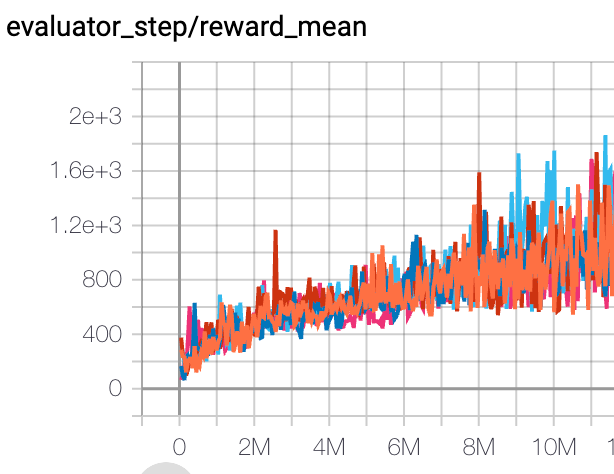
|
策略上的PPO基准测试:
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
乒乓球 (PongNoFrameskip-v4) |
20 |
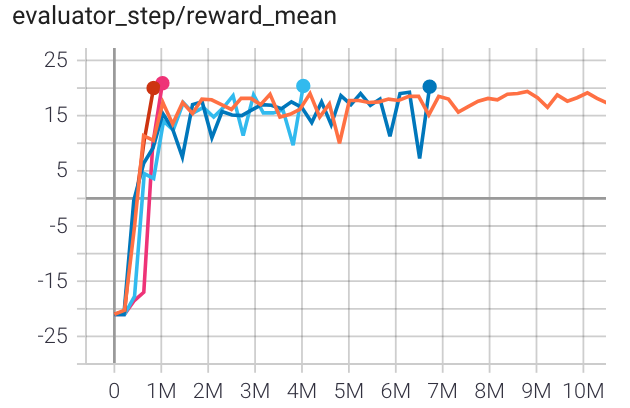
|
RLlib(20) |
|
Qbert (QbertNoFrameskip-v4) |
12146 |
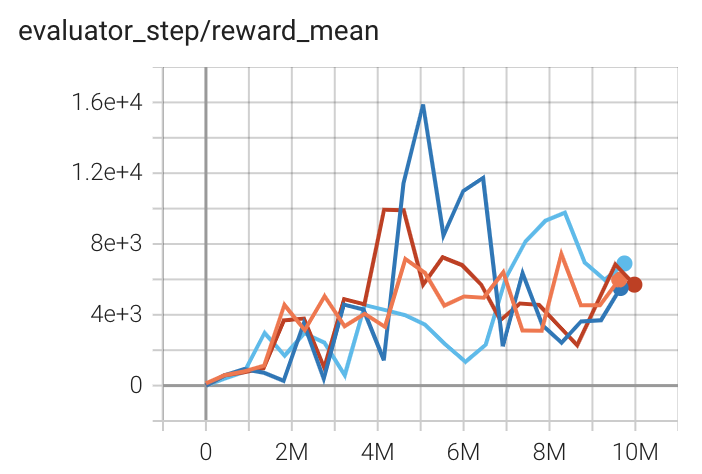
|
RLlib(11085) |
|
太空侵略者 (SpaceInvadersNoFrame skip-v4) |
907 |
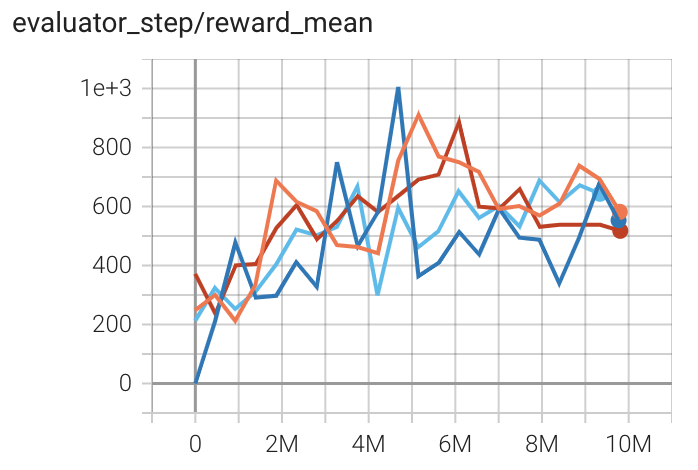
|
RLlib(671) |
|
耐力赛 (EnduroNoFrameskip-v4) |
957 |

|
RLlib(855) |
|
霍珀 (Hopper-v3) |
3000 |
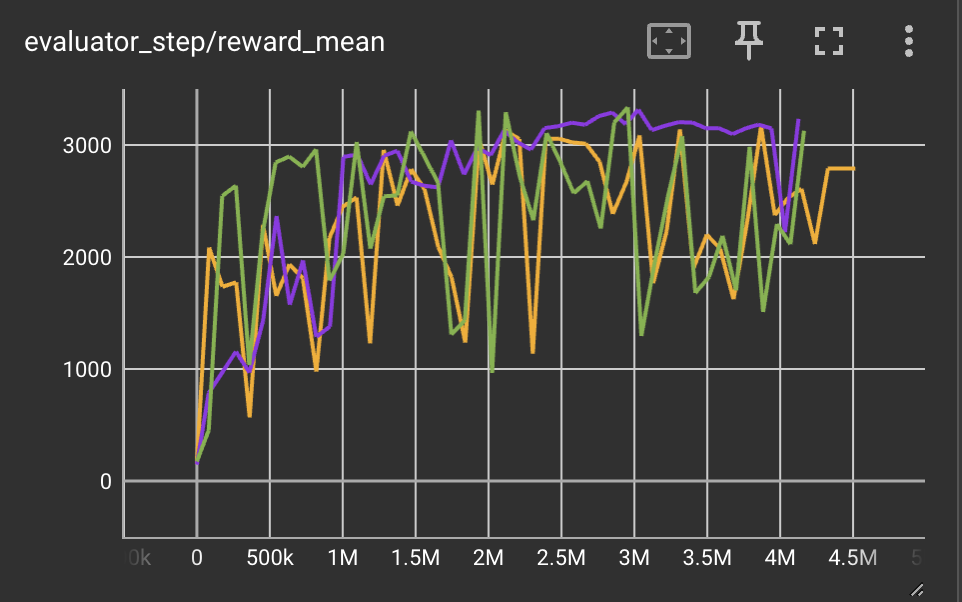
|
天授(3127) Sb3(1567) 旋转中(2500) |
|
Walker2d (Walker2d-v3) |
3700 |
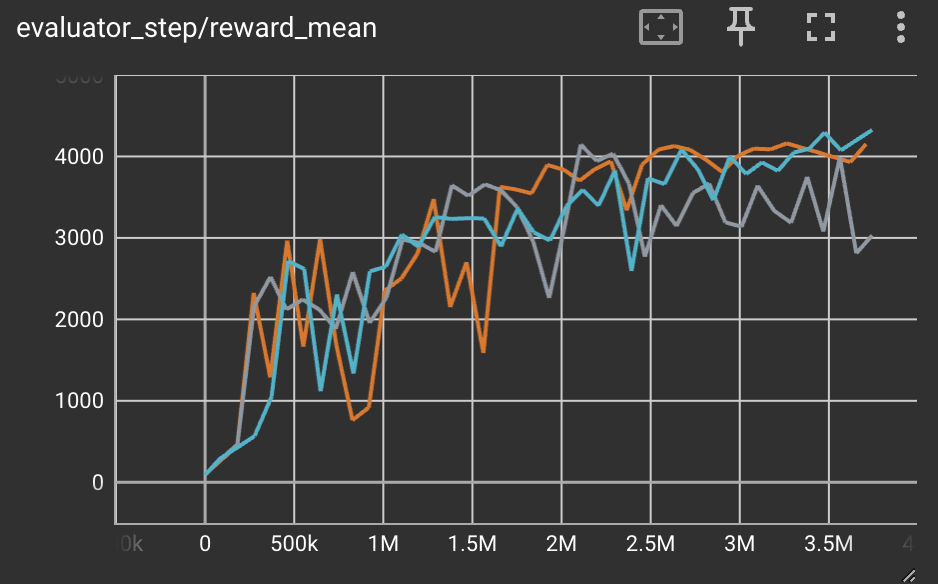
|
天寿(4895) Sb3(1230) 旋转中(2500) |
|
猎豹 (Halfcheetah-v3) |
3500 |
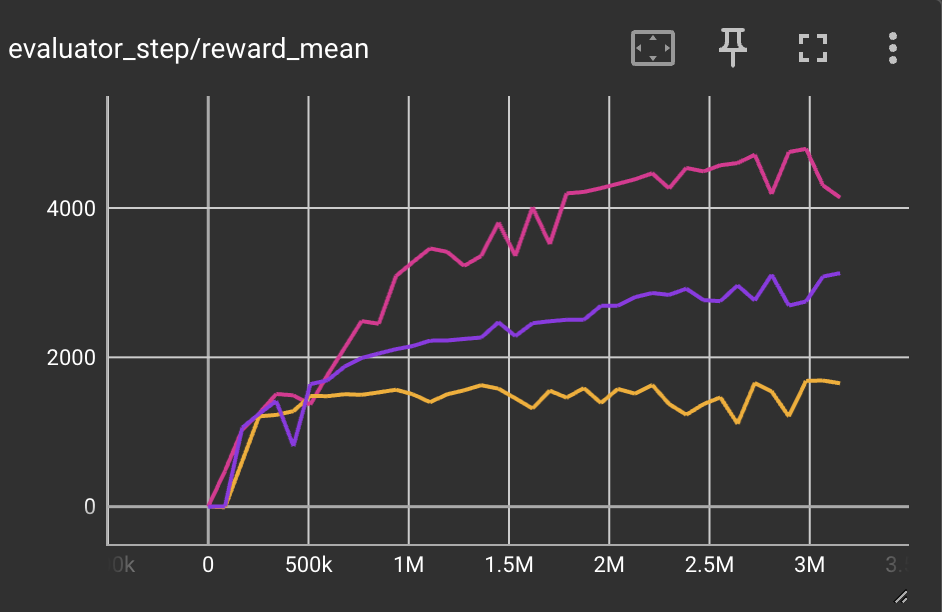
|
Tianshou(7337) Sb3(1976) 旋转中(3000) |
|
蚂蚁 (Ant-v3) |
4200 |
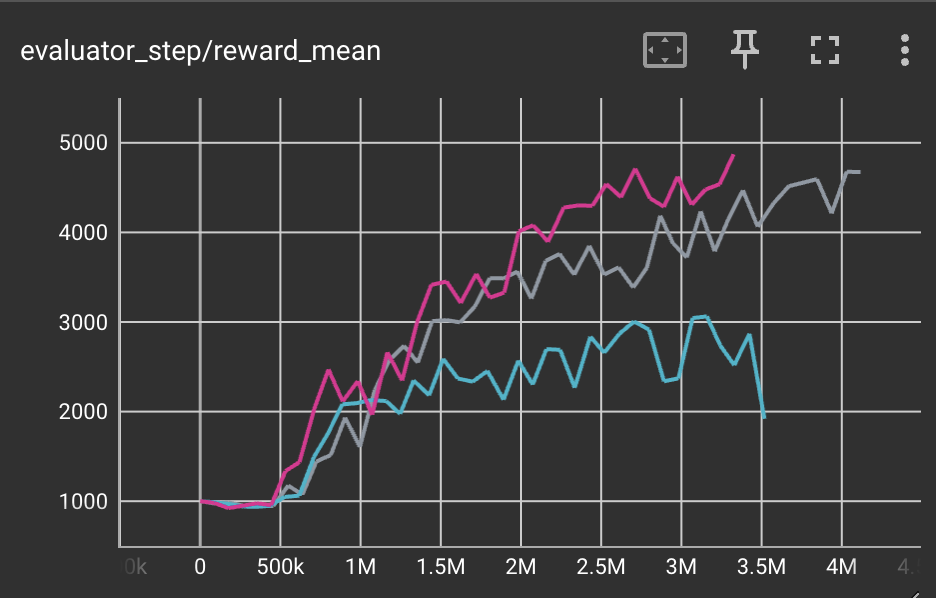
|
天寿(3258) 旋转中(650) |
参考文献¶
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov: “近端策略优化算法”, 2017; [http://arxiv.org/abs/1707.06347 arXiv:1707.06347].
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, Aleksander Madry: “深度策略梯度中的实现问题:以PPO和TRPO为例”,2020年;[http://arxiv.org/abs/2005.12729 arXiv:2005.12729].
Andrychowicz M, Raichuk A, Stańczyk P, 等. 在策略强化学习中什么最重要?一项大规模实证研究[J]. arXiv 预印本 arXiv:2006.05990, 2020.
叶东, 刘志, 孙明, 等. 通过深度强化学习掌握MOBA游戏中的复杂控制[C]//AAAI人工智能会议论文集. 2020, 34(04): 6672-6679.