QTRAN¶
概述¶
QTRAN是由Kyunghwan等人(2019年)提出的。QTRAN是一种用于多智能体强化学习(MARL)的分解方法,它不受此类结构约束的限制,并采用了一种新的方法将原始的联合动作值函数转换为易于分解的形式,同时保持相同的最优动作。
与VDN(Sunehag et al. 2017)和QMIX(Rashid et al. 2018)相比,QTRAN保证了比VDN或QMIX更一般的因式分解,因此覆盖了比之前方法更广泛的MARL任务类别,并且在5m_vs_6m和MMM2地图上表现优于QMIX。
快速事实¶
QTRAN 使用集中训练与分散执行的范式。
QTRAN 是一种无模型和基于价值的方法。
QTRAN 仅支持 离散 动作空间。
QTRAN 是一种 离策略多智能体 强化学习算法。
QTRAN 考虑了一个部分可观测的场景,其中每个智能体只能获得个体观测。
QTRAN 接受 DRQN 作为个体价值网络。
QTRAN通过个体动作值网络、联合动作值网络和状态值网络学习联合值函数。
关键方程或关键图表¶
整体QTRAN架构,包括个体代理网络和混合网络结构:
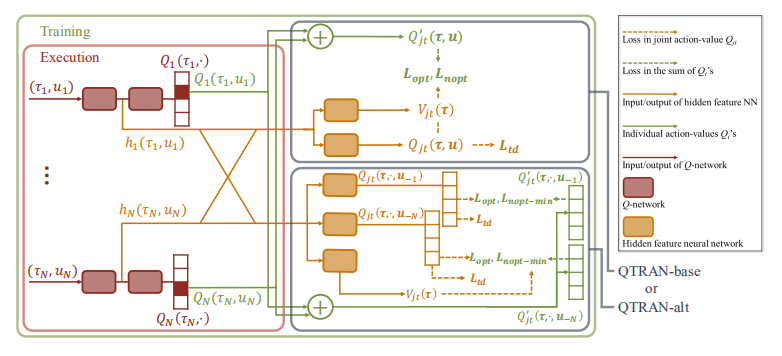
QTRAN通过最小化以下损失来训练混合网络:
伪代码¶
以下流程图展示了QTRAN的训练过程。

扩展¶
QTRAN++ (Son et al. 2019) 作为 QTRAN 的扩展,成功弥合了经验表现与理论保证之间的差距,并在 SMAC 环境中取得了最新的最先进性能。
实现¶
默认配置定义如下:
- class ding.policy.qtran.QTRANPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]
- Overview:
QTRAN算法的策略类。QTRAN是一种多模型强化学习算法,您可以通过以下链接查看论文https://arxiv.org/abs/1803.11485
- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
qtran
POLICY_REGISTRY2
cuda布尔
真
3
on_policy布尔
假
priority布尔
假
5
priority_IS_weight布尔
假
6
learn.update_per_collect整数
20
7
learn.target_update_theta浮点数
0.001
8
learn.discount_factor浮点数
0.99
- The network interface QTRAN used is defined as follows:
- ding.model.template.qtran
别名 <模块 'ding.model.template.qtran' 来自 '/home/docs/checkouts/readthedocs.org/user_builds/di-engine-docs/envs/latest/lib/python3.9/site-packages/ding/model/template/qtran.py'>
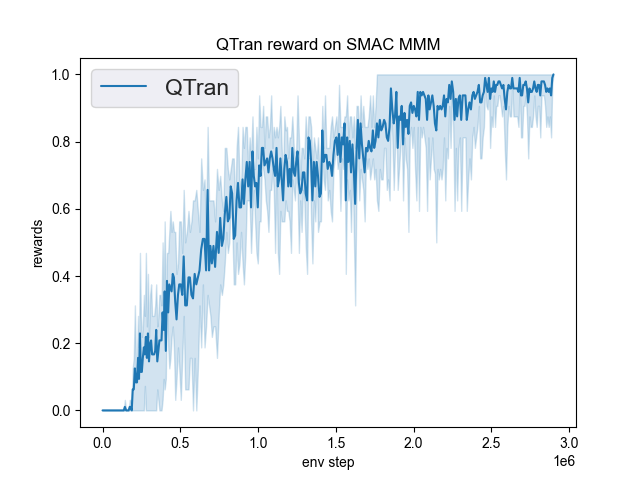
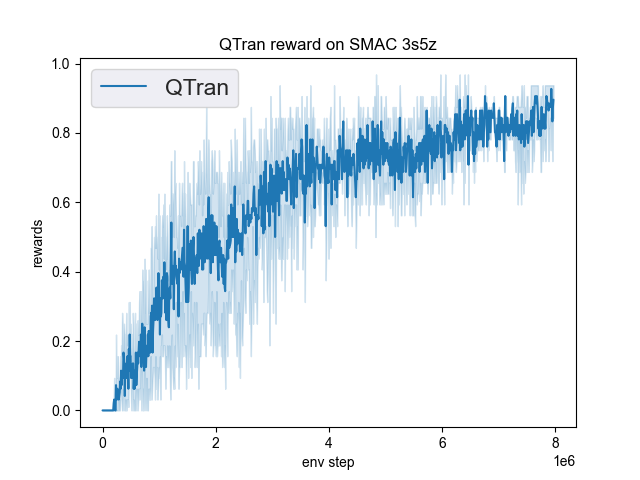
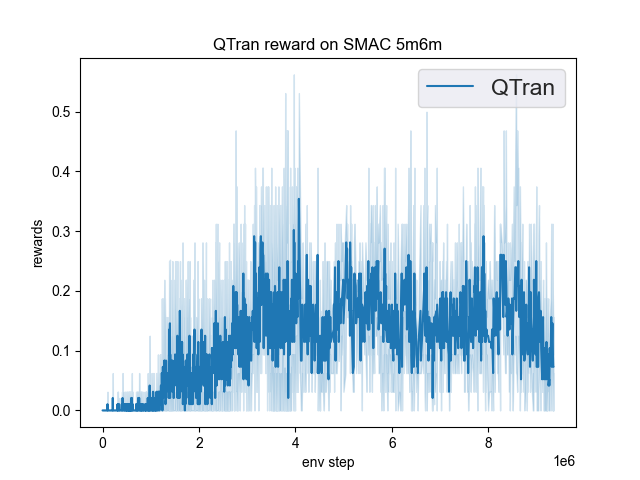
在DI-engine中实现的QTRAN在SMAC(Samvelyan等,2019)中的基准测试结果,用于星际争霸微操问题,已展示。
smac 地图 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
MMM |
1.00 |
|
Pymarl(1.0) |
|
3s5z |
0.95 |
|
Pymarl(0.1) |
|
5米6米 |
0.55 |
|
Pymarl(0.7) |
参考文献¶
QTRAN: 学习通过变换进行因子分解以用于合作多智能体强化学习。ICML, 2019.