R2D2¶
概述¶
R2D2 首次在 分布式强化学习中的循环经验回放 中被提出。 在使用经验回放的RNN训练中,RL算法通常面临表示漂移和循环状态陈旧的问题。 R2D2 采用了两种方法:存储状态和预热,以减轻上述影响。 R2D2 代理整合了这些发现,在 Atari-57 上取得了显著的进展,并在 DMLab-30 上达到了最先进的水平。 作者声称,循环回放分布式DQN(R2D2)是第一个使用单一网络架构和固定超参数集实现这一目标的代理。
快速事实¶
R2D2 是一种离策略、无模型且基于价值的强化学习算法,
R2D2 本质上是一种基于 DQN 的算法,使用了分布式框架、双 Q 网络、决斗架构、n 步 TD 损失和优先经验回放。
R2D2 现在仅支持离散动作空间,并且与 DQN 一样使用eps-greedy进行探索。
R2D2 使用存储状态和预热技术来减轻表示漂移和循环状态陈旧的影响。
R2D2的DI-engine实现提供了res_link键,以支持循环Q网络中的残差链接。
关键方程或关键图表¶
R2D2代理与Ape-X最为相似,基于优先分布式回放和n步双Q学习(n = 5),通过大量执行者(通常为256个)生成经验,并由单一学习者从回放的经验批次中学习。 R2D2的Q网络使用决斗网络架构,并在卷积堆栈后提供一个LSTM层。
与常规的 \((s, a, r, s^')\) 转换元组不同,R2D2 在回放中存储固定长度(m = 80)的 \((s, a, r)\) 序列,相邻序列在时间步上重叠 40 步,并且从不跨越情节边界。具体来说,R2D2 中使用的 n 步目标是:
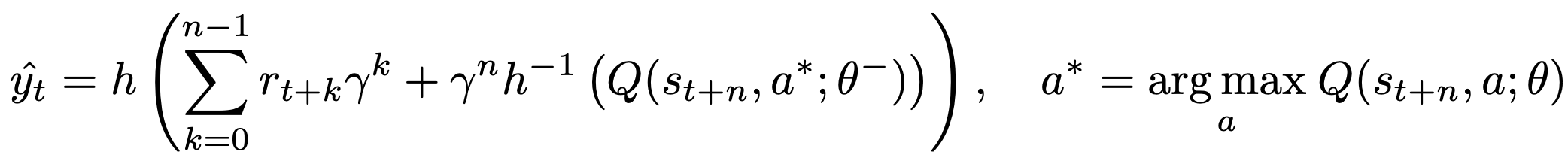
在这里,\(\theta^{-}\) 表示目标网络参数,这些参数每2500个学习步骤从在线网络参数 \(\theta\) 复制而来。
R2D 使用最大和平均绝对 n 步 TD 误差 \(\delta_i\) 的混合作为优先经验回放的优先级指标,应用于序列中:
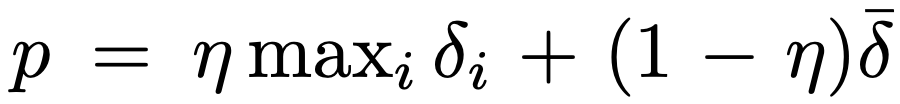
注意
在我们的DI-engine实现中,在每个展开步骤中,基于LSTM的Q网络的输入仅仅是观察和最后的隐藏状态,不包括奖励和one-hot动作。
有关如何在DI-engine中使用RNN的更多详细信息,用户可以参阅How to use RNN, 关于R2D2中的数据整理过程,用户可以参阅data-arrangement部分, 关于R2D2中的预热技术,用户可以参阅burn-in-in-r2d2部分。
扩展¶
R2D2 可以与以下内容结合使用:
实现¶
R2D2Policy 的默认配置定义如下:
- class ding.policy.r2d2.R2D2Policy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[源代码]
- Overview:
R2D2的策略类,来自论文分布式强化学习中的循环经验回放。 R2D2提出应使用几种技巧来改进DRQN,即一些循环经验回放技巧和用于离策略训练的预热机制。
- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
r2d2
RL policy register name, refer toregistryPOLICY_REGISTRYThis arg is optional,a placeholder2
cuda布尔
假
Whether to use cuda for networkThis arg can be diff-erent from modes3
on_policy布尔
假
Whether the RL algorithm is on-policyor off-policy4
priority布尔
假
Whether use priority(PER)Priority sample,update priority5
priority_IS_weight布尔
假
Whether use Importance Sampling Weightto correct biased update. If True,priority must be True.6
discount_factor浮点数
0.997, [0.95, 0.999]
Reward’s future discount factor, aka.gammaMay be 1 when sparsereward env7
nstep整数
3, [3, 5]
N-step reward discount sum for targetq_value estimation8
burnin_step整数
2
The timestep of burnin operation,which is designed to RNN hidden statedifference caused by off-policy9
learn.updateper_collect整数
1
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingThis args can be varyfrom envs. Bigger valmeans more off-policy10
learn.batch_size整数
64
The number of samples of an iteration11
learn.learning_rate浮点数
0.001
Gradient step length of an iteration.12
learn.value_rescale布尔
真
Whether use value_rescale function forpredicted value13
learn.target_update_freq整数
100
Frequence of target network update.Hard(assign) update14
learn.ignore_done布尔
假
Whether ignore done for target valuecalculation.Enable it for somefake termination env15
collect.n_sample整数
[8, 128]
The number of training samples of acall of collector.It varies fromdifferent envs16
collect.unroll_len整数
1
unroll length of an iterationIn RNN, unroll_len>1
网络接口 R2D2 的定义如下:
- class ding.model.template.q_learning.DRQN(obs_shape: int | SequenceType, action_shape: int | SequenceType, encoder_hidden_size_list: SequenceType = [128, 128, 64], dueling: bool = True, head_hidden_size: int | None = None, head_layer_num: int = 1, lstm_type: str | None = 'normal', activation: Module | None = ReLU(), norm_type: str | None = None, res_link: bool = False)[源代码]
- Overview:
DRQN(DQN + RNN = DRQN)算法的神经网络结构和计算图,这是用于序列数据和部分可观测环境的最常见的DQN变体。DRQN由三部分组成:
encoder、head和rnn。encoder用于从各种观测中提取特征,rnn用于处理序列观测和其他数据,head用于计算每个动作维度的Q值。- Interfaces:
__init__,forward.
注意
当前的
DRQN支持两种类型的编码器:FCEncoder和ConvEncoder,两种类型的头:DiscreteHead和DuelingHead,三种类型的 rnn:normal (LSTM with LayerNorm)、pytorch和gru。您可以通过继承此类来自定义自己的编码器、rnn 或头。- forward(inputs: Dict, inference: bool = False, saved_state_timesteps: list | None = None) Dict[source]
- Overview:
DRQN 前向计算图,输入观测张量以预测 q_value。
- Arguments:
输入 (
torch.Tensor): 输入数据的字典,包括观察值和先前的RNN状态。推理: (:obj:’bool’): 是否启用推理前向模式,如果为True,我们展开一个时间步的转换,否则,我们展开整个序列的转换。
saved_state_timesteps: (:obj:’Optional[list]’): 当推理为False时,我们展开序列转换,然后我们将使用此列表来指示如何保存和返回隐藏状态。
- ArgumentsKeys:
obs (
torch.Tensor): 原始观测张量。prev_state (
list): 之前的RNN状态张量,其结构取决于lstm_type。
- Returns:
输出 (
Dict): DRQN前向的输出,包括logit(q_value)和下一个状态。
- ReturnsKeys:
logit (
torch.Tensor): 每个可能动作维度的离散Q值输出。next_state (
list): 下一个RNN状态张量,其结构取决于lstm_type。
- Shapes:
obs (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是obs_shapelogit (
torch.Tensor): \((B, M)\), 其中 B 是批量大小,M 是action_shape
- Examples:
>>> # Init input's Keys: >>> prev_state = [[torch.randn(1, 1, 64) for __ in range(2)] for _ in range(4)] # B=4 >>> obs = torch.randn(4,64) >>> model = DRQN(64, 64) # arguments: 'obs_shape' and 'action_shape' >>> outputs = model({'obs': inputs, 'prev_state': prev_state}, inference=True) >>> # Check outputs's Keys >>> assert isinstance(outputs, dict) >>> assert outputs['logit'].shape == (4, 64) >>> assert len(outputs['next_state']) == 4 >>> assert all([len(t) == 2 for t in outputs['next_state']]) >>> assert all([t[0].shape == (1, 1, 64) for t in outputs['next_state']])
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
Pong (PongNoFrameskip-v4)
|
20 |
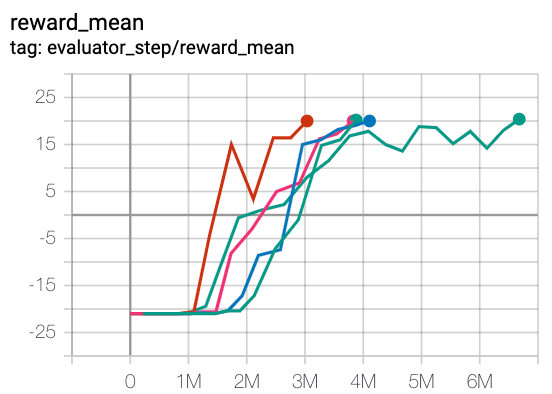
|
||
Qbert (QbertNoFrameskip-v4)
|
6000 |
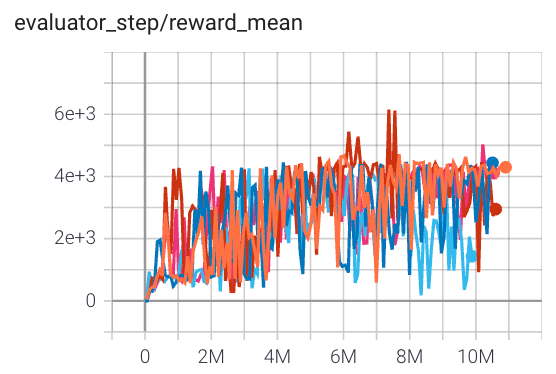
|
||
SpaceInvaders (SpaceInvadersNoFrameskip-v4)
|
1400 |

|
参考文献¶
Kapturowski S, Ostrovski G, Quan J, 等. 分布式强化学习中的循环经验回放[C]//国际学习表示会议. 2018.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller: “使用深度强化学习玩Atari游戏”, 2013; arXiv:1312.5602.
Schaul, T., Quan, J., Antonoglou, I., & Silver, D. (2015). 优先经验回放. arXiv 预印本 arXiv:1511.05952.
Van Hasselt, H., Guez, A., & Silver, D. (2016年3月). 使用双Q学习的深度强化学习. 在AAAI人工智能会议论文集 (第30卷, 第1期).
王, Z., 绍尔, T., 赫塞尔, M., 哈塞尔特, H., 兰克托特, M., & 弗雷塔斯, N. (2016年6月). 深度强化学习的对决网络架构. 在国际机器学习会议上 (pp. 1995-2003). PMLR.
Horgan D, Quan J, Budden D, 等. 分布式优先经验回放[J]. arXiv 预印本 arXiv:1803.00933, 2018.