彩虹¶
概述¶
Rainbow 是在 Rainbow: Combining Improvements in Deep Reinforcement Learning. 它将许多独立的改进方法应用于DQN,包括: Double DQN, priority, dueling head, multi-step TD-loss, C51 (distributional RL) 和 noisy net。
要点摘要¶
Rainbow 是一种 无模型(model-free) 和 基于值(value-based) 的强化学习算法。
Rainbow 仅支持 离散动作空间 。
Rainbow 是一种 异策略(off-policy) 算法。
Usually, Rainbow 使用 eps-greedy , 多项式采样 或者 noisy net 进行探索。
Rainbow 可以与循环神经网络 (RNN) 结合使用。
Rainbow 的 DI-engine 实现支持 多离散(multi-discrete) 动作空间。
关键方程或关键图表¶
双DQN¶
Double DQN, 是在 Deep Reinforcement Learning with Double Q-learning 中提出的一种常见的 DQN 变体。传统的DQN维护一个目标Q网络,该网络周期性地使用当前的Q网络进行更新。双重DQN通过解耦解决了Q值的过高估计问题。它使用当前的Q网络选择动作,但使用目标网络估计Q值,具体而言:
优先经验回放(PER)¶
DQN 从经验回放缓冲区均匀地进行采样。理想情况下,我们希望更频繁地采样那些有更多可学习内容的 transition。作为评估学习潜力的一种替代方法,优先级经验回放会根据最新的绝对 TD 误差转化得到的概率来采样对应的transition,具体而言:
在优先级经验回放(PER)的原始论文中,作者展示了在57个Atari游戏中,PER在大多数游戏上都取得了改进,特别是在 Gopher, Atlantis, James Bond 007, Space Invaders 等游戏中。
决斗网络¶
Ddueling network 是一种为基于值的强化学习算法设计的网络架构。它包含两个计算流,一个用于状态值函数 \(V\) ,另一个用于状态相关的动作优势函数 \(A\) 。 这两个流共享一个公共的卷积编码器,并通过一个特殊的聚合器合并,产生状态-动作值函数Q的估计,如图所示。
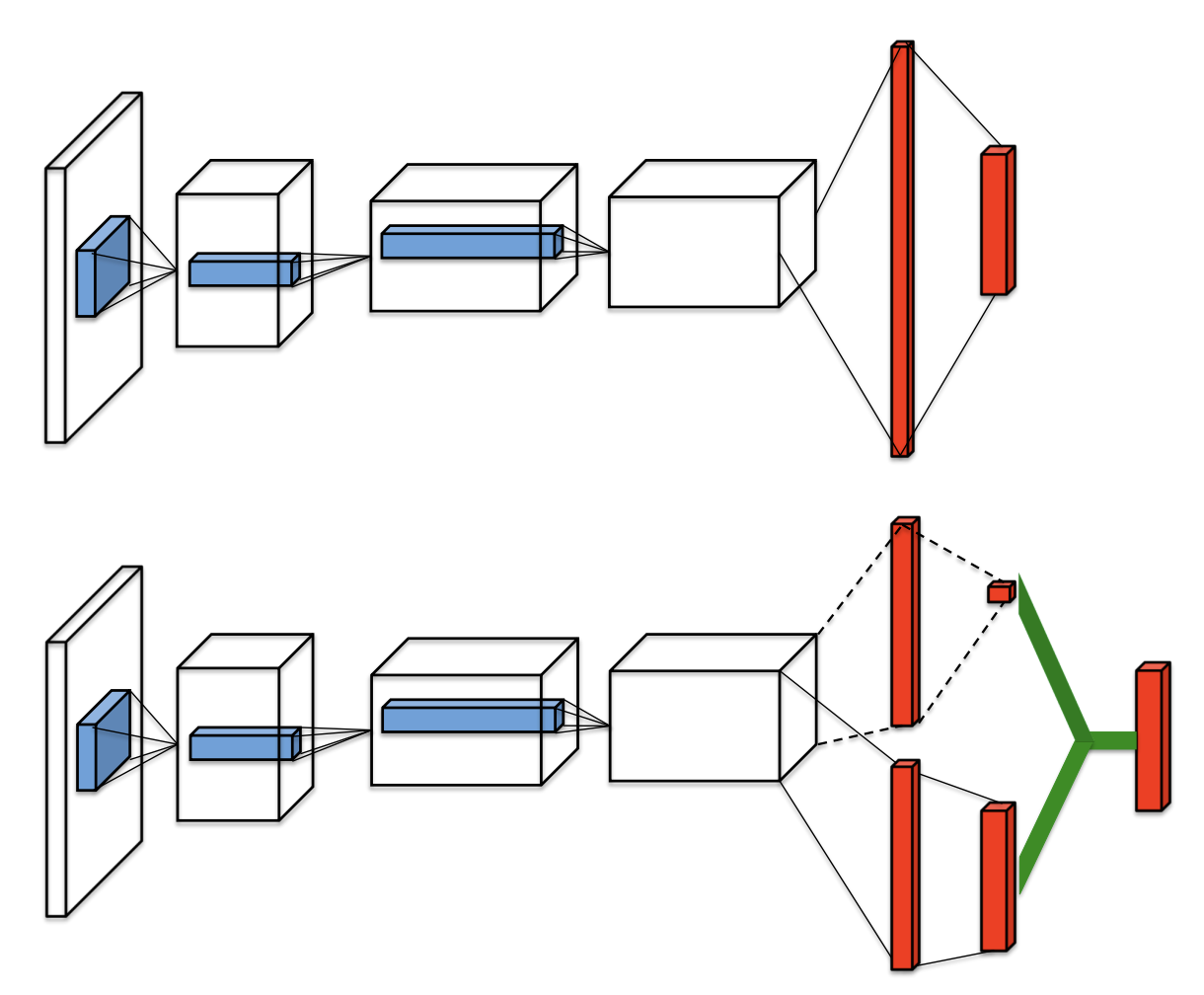
给定 \(Q\) ,我们无法唯一地恢复 \(V\) 和 \(A\) 。因此,我们通过以下的动作值分解方式来强制使优势函数为零:
通过这种方式,可以解决可识别性问题,并增加优化过程的稳定性。Rainbow的网络架构是一种针对回报分布进行调整的 dueling network 网络架构。
多步学习¶
DQN的多步变体通过最小化替代损失来定义,具体如下:
其中,截断的n步回报定义为:
在文章 Revisiting Fundamentals of Experience Replay, 作者分析认为,当使用多步学习时,更大容量的回放缓冲区显著提高了性能,并且他们认为原因是多步学习带来了更大的方差,而这一方差可以通过更大的回放缓冲区来进行补偿。
分布式强化学习¶
Distributional RL 最初是在 A Distributional Perspective on Reinforcement Learning 中提出的。它通过使用离散分布来学习逼近回报的分布,而不是期望回报。它的分布由一个向量 \(\boldsymbol{z}\) 支持, 即 \(z^{i}=v_{\min }+(i-1) \frac{v_{\max }-v_{\min }}{N_{\text {atoms }}-1}\) ,其中 \(i \in\left\{1, \ldots, N_{\text {atoms }}\right\}\), \(N_{\text {atoms }} \in \mathbb{N}^{+}atoms\) 。 它在t时刻的近似分布 \(d_{t}\) 在这个支持向量上被定义, 在每个原子 \(i\) 上的概率为 \(p_{\theta}^{i}\left(S_{t}, A_{t}\right)\) 最终的分布可以表示为 \(d_{t}=\left(z, p_{\theta}\left(S_{t}, A_{t}\right)\right)\) 。 然后,通过最小化分布 \(d_{t}\) 和目标分布之间的Kullback-Leibler散度,得到了一种 Q-learning 的 distributional variant 。
在这里, \(\Phi_{\boldsymbol{z}}\) 是目标分布在固定支持 \(\boldsymbol{z}\) 上的L2投影。
噪声网络¶
Noisy Nets使用一个噪声线性层,它结合了确定性和噪声流:
随着时间的推移,网络可以学习忽略噪声流,但在状态空间的不同部分以不同的速率进行学习,从而实现一种自适应的状态条件探索,即一种自退火机制。当动作空间很大时,例如在 Montezuma’s Revenge 等游戏中噪声网络通常比 \(\epsilon\)-greedy 方法取得更好的改进效果,这是由于 \(\epsilon\)-greedy 往往会在收集足够数量的动作奖励之前迅速收敛到一个 one hot 分布。 在我们的实现中,噪声在每次前向传播时都会重新采样,无论是在数据收集还是训练过程中。当使用双重Q学习时,目标网络也会在每次前向传播之前重新采样噪声。噪声采样过程中,噪声首先从 \(N(0,1)\) 中进行采样,然后通过一个保持符号的平方根函数进行调节,即 \(x \rightarrow x.sign() * x.sqrt()\).
集成方法¶
首先,我们将一步的 distributional loss 替换为多步损失:
然后,我们将多步 distributional loss 与 Double DQN相结合,通过使用在线网络选择贪婪动作,并使用目标网络评估该动作。KL损失也被用来优先选择转换:
网络有共享的表征层, 之后将其输入到 \(N_{atoms}\) 输出的值流 \(v_\eta\) 中,以及 \(N_{atoms} \times N_{actions}\) 输出的优势函数流 \(a_{\psi}\), 在这里 \(a_{\psi}^i(a)\) 表示与原子i和动作a对应的输出。对于每个原子 \(z_i\) , 值流和优势流被聚合,类似于 Dueling DQN,然后通过softmax层进行处理,以获得用于估计回报分布的归一化参数化分布:
扩展¶
Rainbow 可以与以下技术相结合使用:
循环神经网络 (RNN)
实现¶
Rainbow 默认参数如下:
- class ding.policy.rainbow.RainbowDQNPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[来源]
- Overview:
- Rainbow DQN contain several improvements upon DQN, including:
目标网络
决斗架构
优先经验回放
n步回报
噪声网络
配电网
因此,RainbowDQNPolicy 类继承自 DQNPolicy 类
- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
彩虹
RL policy register name, refer toregistryPOLICY_REGISTRYthis arg is optional,a placeholder2
cuda布尔
假
Whether to use cuda for networkthis arg can be diff-erent from modes3
on_policy布尔
假
Whether the RL algorithm is on-policyor off-policy4
priority布尔
真
Whether use priority(PER)priority sample,update priority5
model.v_min浮点数
-10
Value of the smallest atomin the support set.6
model.v_max浮点数
10
Value of the largest atomin the support set.7
model.n_atom整数
51
Number of atoms in the support setof the value distribution.8
other.eps.start浮点数
0.05
Start value for epsilon decay. It’ssmall because rainbow use noisy net.9
other.eps.end浮点数
0.05
End value for epsilon decay.10
discount_factor浮点数
0.97, [0.95, 0.999]
Reward’s future discount factor, aka.gammamay be 1 when sparsereward env11
nstep整数
3, [3, 5]
N-step reward discount sum for targetq_value estimation12
learn.updateper_collect整数
3
How many updates(iterations) to trainafter collector’s one collection. Onlyvalid in serial trainingthis args can be varyfrom envs. Bigger valmeans more off-policy
Rainbow使用的网络接口被定义如下:
- class ding.model.template.q_learning.RainbowDQN(obs_shape: int | SequenceType, action_shape: int | SequenceType, encoder_hidden_size_list: SequenceType = [128, 128, 64], head_hidden_size: int | None = None, head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, v_min: float | None = -10, v_max: float | None = 10, n_atom: int | None = 51)[源代码]
- Overview:
RainbowDQN的神经网络结构和计算图,它结合了分布式强化学习和DQN。您可以参考论文《Rainbow: Combining Improvements in Deep Reinforcement Learning》https://arxiv.org/pdf/1710.02298.pdf了解更多详情。
- Interfaces:
__init__,forward
注意
RainbowDQN 默认包含决斗架构。
- forward(x: Tensor) Dict[来源]
- Overview:
使用观测张量来预测Rainbow输出。 通过Rainbow的MLPs前向设置更新参数。
- Arguments:
- x (
torch.Tensor): 编码后的嵌入张量,形状为
(B, N=hidden_size)。
- x (
- Returns:
- outputs (
Dict): 使用
MLP和RainbowHead设置运行并返回结果预测字典。
- outputs (
- ReturnsKeys:
logit (
torch.Tensor): 与输入x大小相同的 Logit 张量。分布 (
torch.Tensor): 大小为(B, N, n_atom)的分布张量
- Shapes:
x (
torch.Tensor): \((B, N)\), 其中 B 是批量大小,N 是 head_hidden_size。logit (
torch.FloatTensor): \((B, M)\), 其中 M 是 action_shape。分布(
torch.FloatTensor): \((B, M, P)\), 其中 P 是 n_atom。
- Examples:
>>> model = RainbowDQN(64, 64) # arguments: 'obs_shape' and 'action_shape' >>> inputs = torch.randn(4, 64) >>> outputs = model(inputs) >>> assert isinstance(outputs, dict) >>> assert outputs['logit'].shape == torch.Size([4, 64]) >>> # default n_atom: int =51 >>> assert outputs['distribution'].shape == torch.Size([4, 64, 51])
基准¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
乒乓球 (PongNoFrameskip-v4) |
21 |
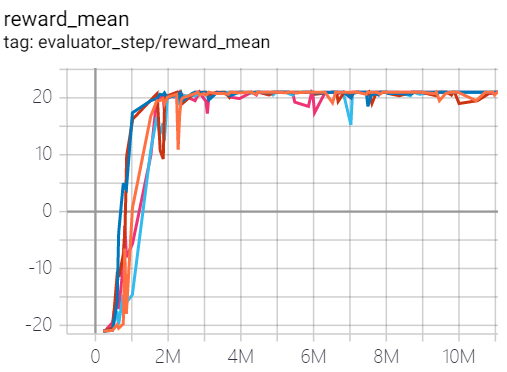
|
Tianshou(21) |
|
Qbert (QbertNoFrameskip-v4) |
20600 |
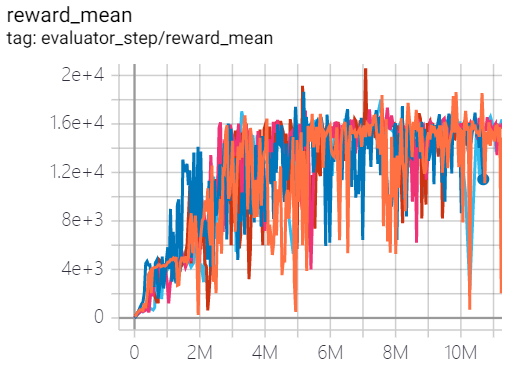
|
Tianshou(16192.5) |
|
太空侵略者 (SpaceInvadersNoFrame skip-v4) |
2168 |

|
Tianshou(1794.5) |
附注:
上述结果是通过在五个不同的随机种子 (0, 1, 2, 3, 4)上运行相同的配置获得的。
对于离散动作空间算法,通常使用 Atari 环境集进行测试(包括子环境 Pong ) ,而 Atari 环境通常通过训练10M个环境步骤的最高平均奖励来评估。有关 Atari 的更多详细信息, 请参阅 Atari Env Tutorial .
关于Rainbow算法的实验技巧¶
我们在LunarLander环境上进行了实验, 把 rainbow (dqn) 策略与 n-step, dueling, priority, and priority_IS 等基准比较. 实验的代码链接在这里 here.
请注意,配置文件默认设置为 dqn ,如果我们想采用 rainbow 需要将策略类型更改如下:
lunarlander_dqn_create_config = dict(
env=dict(
type='lunarlander',
import_names=['dizoo.box2d.lunarlander.envs.lunarlander_env'],
),
env_manager=dict(type='subprocess'),
policy=dict(type='rainbow'),
)
以下是关于实验设置的详细说明:
实验设置 |
备注 |
|---|---|
基础 |
一步DQN (n步=1, 决斗=False, 优先级=False, 优先级_IS=False) |
n步 |
n步DQN (n步=3, 决斗=False, 优先级=False, 优先级重要性采样=False) |
决斗 |
使用决斗头技巧 (n步=3, 决斗=True, 优先级=False, 优先级_IS=False) |
优先级 |
使用优先经验回放缓冲区(n步=3,决斗=False,优先级=True,优先级_IS=False) |
priority_IS |
使用重要性采样技巧(n步=3,决斗=False,优先级=True,优先级_IS=True) |
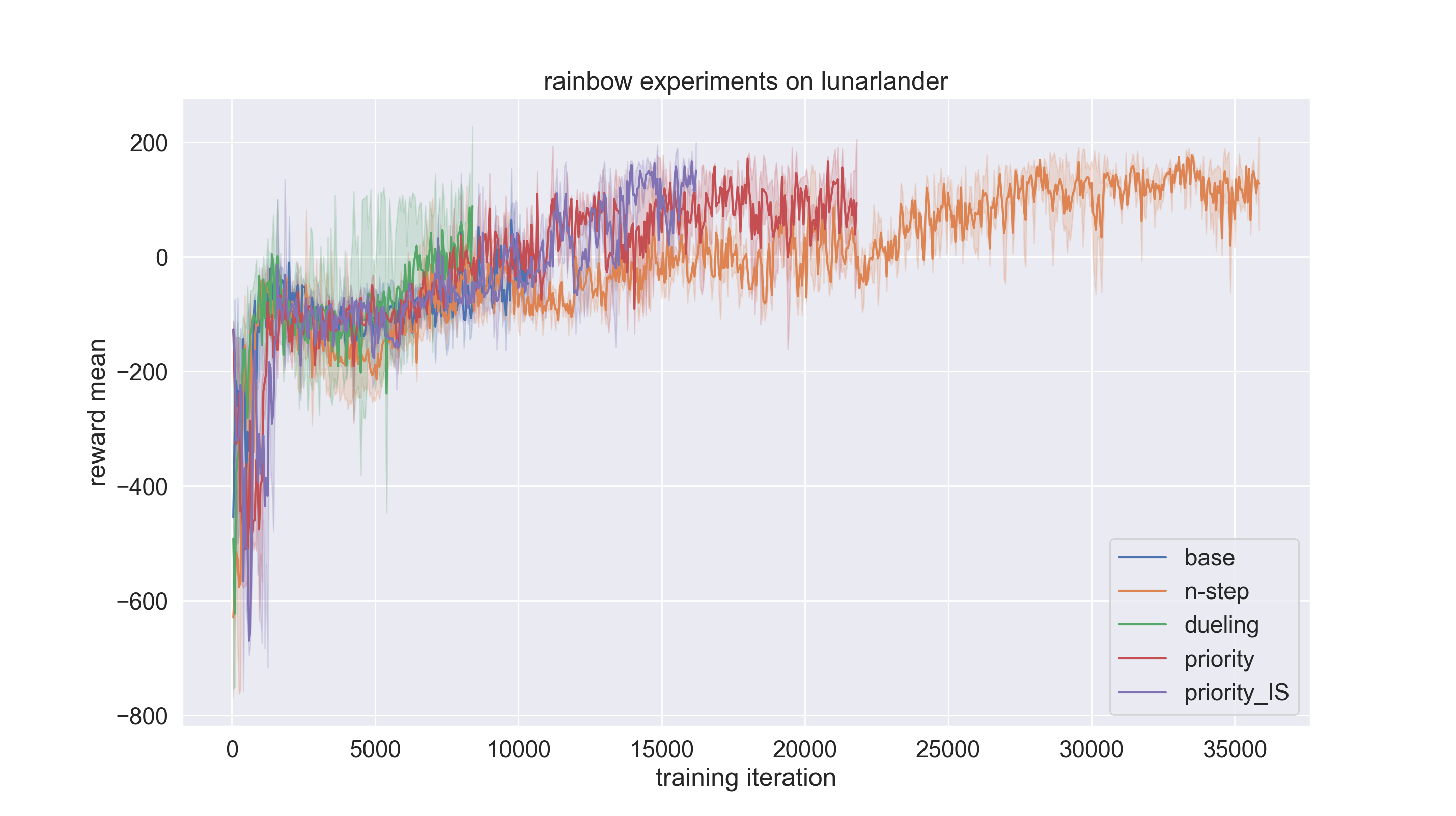
reward_mean相对于training iteration被作为评估指标。每个实验设置将使用随机种子0、1和2进行三次运行,并对结果进行平均,以确保结果的随机性。
if __name__ == "__main__":
serial_pipeline([main_config, create_config], seed=0)
通过在配置文件中设置
exp_name,实验结果可以保存在指定路径。否则,它将保存在‘./default_experiment’目录中。
from easydict import EasyDict
from ding.entry import serial_pipeline
nstep = 1
lunarlander_dqn_default_config = dict(
exp_name='lunarlander_exp/base-one-step2',
env=dict(
......
结果如下图所示。可以看到,通过使用技巧,收敛速度大大加快。在这个实验设置中, Dueling trick 对性能的贡献最大。
参考文献¶
(DQN) Mnih, Volodymyr, 等人。 “通过深度强化学习实现人类水平的控制。” 2015; [https://deepmind-data.storage.googleapis.com/assets/papers/DeepMindNature14236Paper.pdf]
(彩虹) Matteo Hessel, Joseph Modayil, Hado van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, David Silver: “彩虹:结合深度强化学习的改进”,2017年;[http://arxiv.org/abs/1710.02298 arXiv:1710.02298].
(Double DQN) Van Hasselt, Hado, Arthur Guez, 和 David Silver: “使用双Q学习的深度强化学习。”, 2016; [https://arxiv.org/abs/1509.06461 arXiv:1509.06461]
(PER) Schaul, Tom, 等人: “优先经验回放。”, 2016; [https://arxiv.org/abs/1511.05952 arXiv:1511.05952]
William Fedus, Prajit Ramachandran, Rishabh Agarwal, Yoshua Bengio, Hugo Larochelle, Mark Rowland, Will Dabney: “重温经验回放的基础”, 2020; [http://arxiv.org/abs/2007.06700 arXiv:2007.06700].
(决斗网络) Wang, Z., Schaul, T., Hessel, M., Hasselt, H., Lanctot, M., & Freitas: “深度强化学习的决斗网络架构”, 2016; [https://arxiv.org/abs/1511.06581 arXiv:1511.06581]
(多步) Sutton, R. S., 和 Barto, A. G.: “强化学习:导论”. 麻省理工学院出版社, 剑桥 MA. 1998;
(分布强化学习) Bellemare, Marc G., Will Dabney, 和 Rémi Munos.: “强化学习的分布视角。”, 2017; [https://arxiv.org/abs/1707.06887 arXiv:1707.06887]
(噪声网络) Fortunato, Meire, 等人: “用于探索的噪声网络。”, 2017; [https://arxiv.org/abs/1706.10295 arXiv:1706.10295]