RND¶
概述¶
RND(随机网络蒸馏)首次在 通过随机网络蒸馏进行探索 中提出,它为深度强化学习方法引入了一种易于实现且计算开销最小的探索奖励。该探索奖励是一个神经网络预测由固定随机初始化神经网络给出的观察特征的误差。RND声称,这是第一个在不使用演示或访问游戏底层状态的情况下,在《蒙特祖马的复仇》中实现优于人类平均表现的方法。
快速事实¶
探索方法背后的洞察力是,我们首先建立一种方法来衡量状态的新颖性,即, 我们对该状态的了解程度,或者我们访问过类似状态的次数。 然后我们根据状态的新颖性度量分配探索奖励。 如果访问的状态更新颖,或者说该状态被探索的次数很少,代理将获得更大的内在奖励。相反, 如果代理对该状态更熟悉,或者说,该状态已经被探索了很多次, 代理在该状态上将获得较小的内在奖励。
RND 是一种基于预测误差的探索方法,可以应用于非表格情况。基于预测误差的方法的主要思想是将内在奖励定义为与代理转换相关的问题的预测误差,例如学习前向动态模型、学习逆向动态模型,甚至是随机生成的问题,这正是 RND 算法中的情况。
RND 涉及 两个神经网络:一个固定且随机初始化的目标网络,用于设置预测问题,以及一个预测网络,该网络在代理收集的数据上进行训练。
在RND论文中,基础的强化学习算法是离策略的PPO。通常,RND内在奖励生成模型可以方便地与许多不同的强化学习算法结合,例如DDPG、TD3、SAC。
关键方程或关键图表¶
以下两张图来自OpenAI的博客。 RND的总体概览如下:
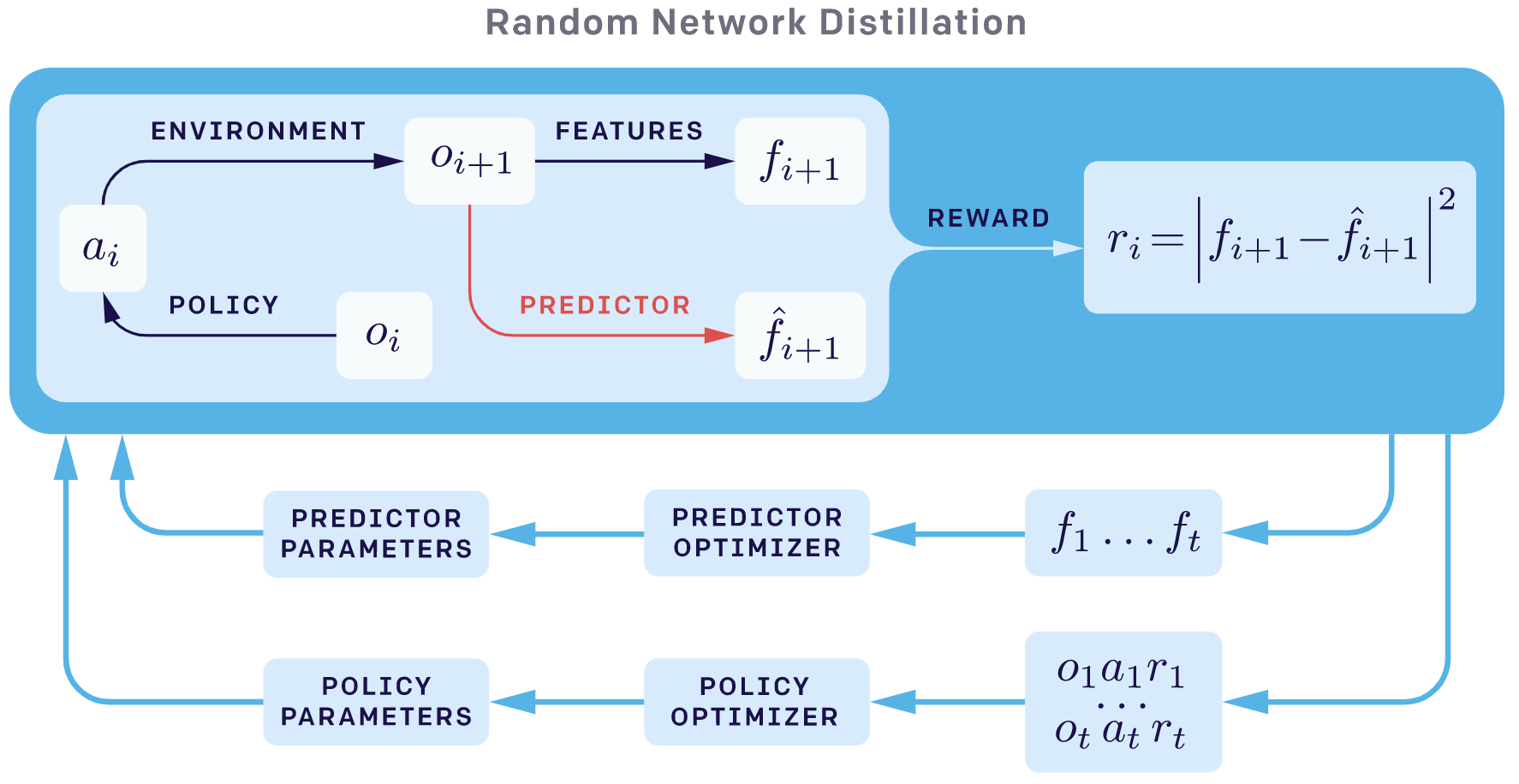
next_sate_prediction探索方法的整体概览如下:
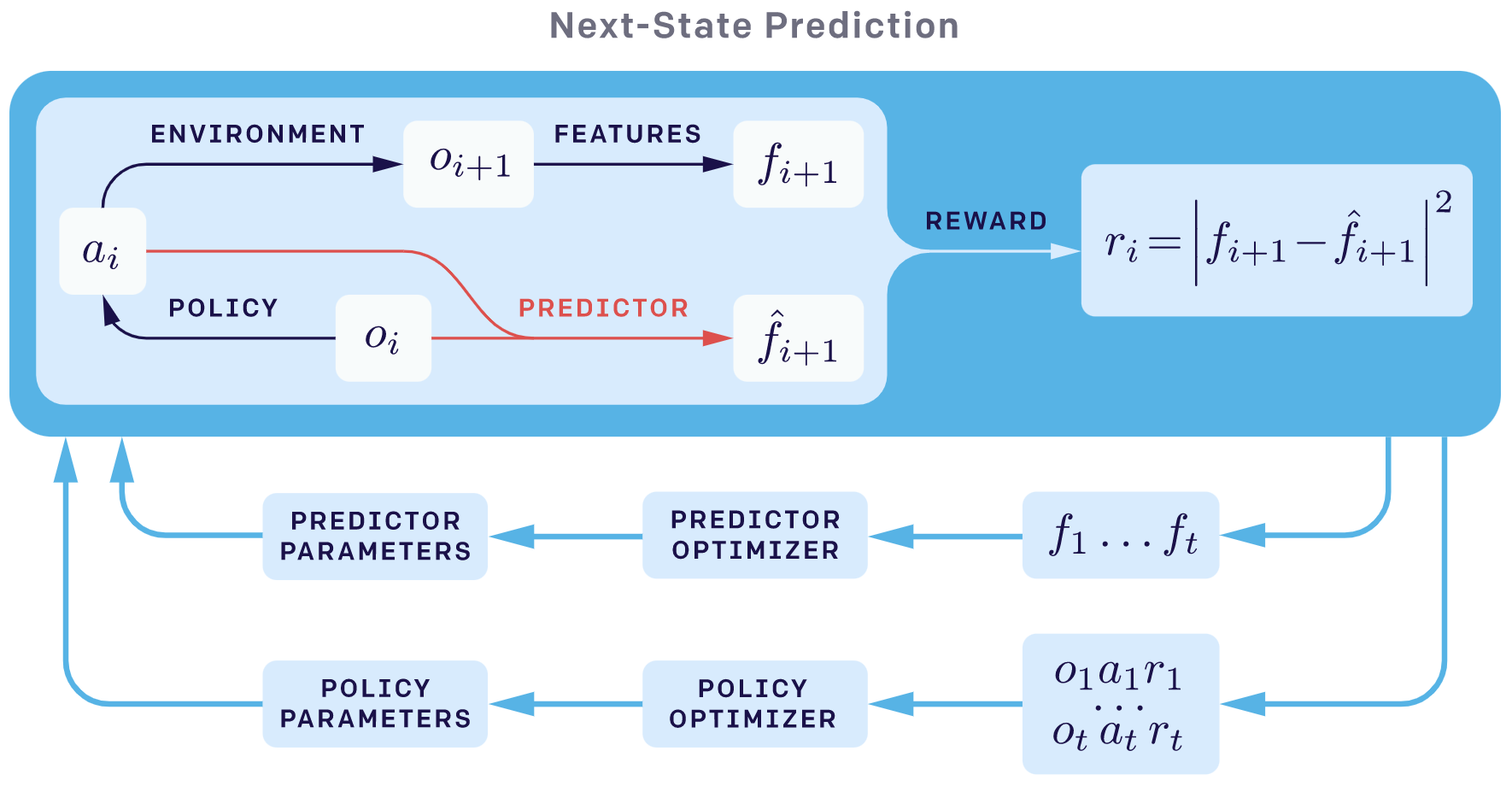
在RND论文中,作者指出预测误差可以归因于以下因素:
训练数据量。预测误差在预测器看到很少类似示例的地方较高。
随机性。由于目标函数是随机的,预测误差很高。随机转换是前向动态预测中此类误差的来源。
模型误设。预测误差高是因为预测所需的信息缺失,或者预测器的模型类别过于有限,无法适应目标函数的复杂性。
因子1是一个有用的误差来源,因为它量化了经验的新颖性,而因子2和3则导致了嘈杂电视问题,这在基于next_sate_prediction的探索方法中是一个严重的问题。 RND避免了因子2和3,因为目标网络被选择为确定性的,并且与预测器网络的模型类具有相同的网络结构。
在RND中,目标网络将观察结果映射到一个嵌入\(f: O → R^k\),并且通过梯度下降训练预测神经网络\(\hat{f}: O → R^k\),以最小化相对于其参数\(θ_\hat{f}\)的期望均方误差\(|f (x; θ) − f (x)|\)。在不熟悉的状态下,很难预测固定随机初始化神经网络的输出,因此预测误差较高,所以RND可以将预测误差视为访问状态的新颖性度量。
但是RND仍然面临一些问题,其中之一是RND的奖励可能会随着时间的推移逐渐消失,因为随着训练的进展,预测网络可以越来越准确地拟合随机初始化神经网络的输出。 感兴趣的读者可以参考后续的改进工作Never Give Up: Learning Directed Exploration Strategies 和Agent57: Outperforming the Atari Human Benchmark。
重要的实现细节¶
1. 内在奖励归一化和权重因子。 使用最小-最大归一化方法对内在奖励进行归一化,即首先减去小批量最小值,然后除以小批量最大值与小批量最小值之间的差值。经过最小-最大归一化后,RND内在奖励被缩放到[0,1]范围内。我们还应该使用一些权重因子来控制探索和利用的平衡。 对于MiniGrid,在每个回合中,我们将最后一个非零的正原始奖励乘以1000(更一般地说,权重因子可以是游戏的最大长度)作为最终的融合奖励,以放大其原始目标的效果。我们在minigrid empty8中的实验结果表明,探索和利用的平衡(在这里是探索RL算法中的内在奖励的权重因子)对于在MiniGrid环境中实现良好性能至关重要。
2. 观测值归一化. 通过减去运行平均值然后除以运行标准差来对每个维度进行白化。 然后将归一化的观测值裁剪到-5和5之间。 在开始优化之前,通过在环境中随机代理进行少量步骤来初始化归一化参数。 对预测网络和目标网络使用相同的观测值归一化,但不包括策略网络。
3. 非片段式内在奖励和两个价值头。 非片段式设置(意味着回报不会在“游戏结束”状态时被截断)在没有外在奖励的情况下探索时,比片段式设置产生了更多的探索。 为了结合片段式和非片段式的奖励流,rnd作者推荐使用两个价值头。 当结合片段式和非片段式的回报时,对外在奖励使用较高的折扣因子会导致更好的性能, 而对于内在奖励则会损害探索。因此,rnd作者建议将外在奖励的折扣因子设置为0.999,内在奖励的折扣因子设置为0.99。
注意
在我们的实现中,为了简化,我们没有采用以下技巧:非情节性内在奖励、两个价值头和不同的折扣因子。
为了更清楚地理解这些技巧背后的原因,建议阅读原始的rnd paper。
伪代码¶

代码实现¶
RND奖励模型的接口定义如下:
- class ding.reward_model.rnd_reward_model.RndRewardModel(config: EasyDict, device: str = 'cpu', tb_logger: SummaryWriter = None)[source]
- Overview:
RND奖励模型类 (https://arxiv.org/abs/1810.12894v1)
- Interface:
estimate,train,collect_data,clear_data,__init__,_train,load_state_dict,state_dict- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
rnd
Reward model register name, referto registryREWARD_MODEL_REGISTRY2
intrinsic_reward_type字符串
添加
the intrinsic reward typeincluding add, new, or assign3
learning_rate浮点数
0.001
The step size of gradient descent4
batch_size整数
64
Training batch size5
hidden_size_list列表 (int)
[64, 64, 128]
the MLP layer shape6
update_per_collect整数
100
Number of updates per collect7
obs_norm布尔
真
Observation normalization8
obs_norm_clamp_min整数
0
min clip value for obs normalization9
obs_norm_clamp_max整数
1
max clip value for obs normalization10
intrinsic_reward_weight浮点数
0.01
the weight of intrinsic rewardr = w*r_i + r_e11
extrinsic_reward_norm布尔
真
Whether to normlize extrinsic reward12
extrinsic_reward_norm_max整数
1
the upper bound of the rewardnormalization
- estimate(data: list) List[Dict][source]
重写数据中每一行的奖励键。
on policy PPO 的接口定义如下:
- class ding.policy.ppo.PPOPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[源代码]
- Overview:
策略类中的on-policy版本PPO算法。论文链接:https://arxiv.org/abs/1707.06347。
注意:... 表示省略的代码片段。完整代码请参考我们在DI-engine中的
实现。
RndNetwork¶
首先,我们定义类 RndNetwork 包含两个神经网络:固定的和随机初始化的目标网络 self.target,
以及预测网络 self.predictor,该网络在代理收集的数据上进行训练。
class RndNetwork(nn.Module): def __init__(self, obs_shape: Union[int, SequenceType], hidden_size_list: SequenceType) -> None: super(RndNetwork, self).__init__() if isinstance(obs_shape, int) or len(obs_shape) == 1: self.target = FCEncoder(obs_shape, hidden_size_list) self.predictor = FCEncoder(obs_shape, hidden_size_list) elif len(obs_shape) == 3: self.target = ConvEncoder(obs_shape, hidden_size_list) self.predictor = ConvEncoder(obs_shape, hidden_size_list) else: raise KeyError( "not support obs_shape for pre-defined encoder: {}, please customize your own RND model". format(obs_shape) ) for param in self.target.parameters(): param.requires_grad = False def forward(self, obs: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]: predict_feature = self.predictor(obs) with torch.no_grad(): target_feature = self.target(obs) return predict_feature, target_feature
RndRewardModel¶
然后,我们在RndRewardModel类的_init_中初始化奖励模型、优化器和self._running_mean_std_rnd。
class RndRewardModel(BaseRewardModel): ... def __init__(self, config: EasyDict, device: str, tb_logger: 'SummaryWriter') -> None: # noqa ... self.reward_model = RndNetwork(config.obs_shape, config.hidden_size_list) ... self.opt = optim.Adam(self.reward_model.predictor.parameters(), config.learning_rate) ... self._running_mean_std_rnd = RunningMeanStd(epsilon=1e-4)
训练 RndRewardModel¶
之后,我们计算奖励模型损失并更新RND预测器网络:self.reward_model.predictor。请注意,根据原始论文,我们采用了观察归一化技巧,即将原始观察值转换为均值为0,标准差为1,并将归一化后的观察值裁剪到-5和5之间,这在经验上非常重要,尤其是在使用随机网络作为目标时,详细解释请参阅RND论文的第2.4章。
def _train(self) -> None: train_data: list = random.sample(self.train_data, self.cfg.batch_size) train_data: torch.Tensor = torch.stack(train_data).to(self.device) # observation normalization: transform to mean 0, std 1 self._running_mean_std_rnd_obs.update(train_data.cpu().numpy()) train_data = (train_data - to_tensor(self._running_mean_std_rnd_obs.mean)) / to_tensor(self._running_mean_std_rnd_obs.std) train_data = torch.clamp(train_data, min=-5, max=5) predict_feature, target_feature = self.reward_model(train_data) loss = F.mse_loss(predict_feature, target_feature.detach()) self.opt.zero_grad() loss.backward() self.opt.step()
计算RND奖励¶
最后,我们根据RND奖励模型计算MSE损失,并进行必要的后续处理,并在类RndRewardModel的estimate方法中重写数据中的奖励键。需要注意的是,我们采用了奖励归一化技巧,即将原始的RND奖励转换为(均值为0,标准差为1),经验表明,在某些稀疏奖励环境中,如minigrid,这种归一化方式比仅除以self._running_mean_std_rnd.std效果更好。
calculate the RND pseudo rewardobs = collect_states(data) obs = torch.stack(obs).to(self.device) # observation normalization: transform to mean 0, std 1 obs = (obs - to_tensor(self._running_mean_std_rnd_obs.mean)) / to_tensor(self._running_mean_std_rnd_obs.std) obs = torch.clamp(obs, min=-5, max=5) with torch.no_grad(): predict_feature, target_feature = self.reward_model(obs) reward = F.mse_loss(predict_feature, target_feature, reduction='none').mean(dim=1) self._running_mean_std_rnd.update(reward.cpu().numpy()) # reward normalization: transform to [0,1], empirically we found this normalization way works well # than only dividing the self._running_mean_std_rnd.std rnd_reward = (reward - reward.min()) / (reward.max() - reward.min() + 1e-11)2.
combine the RND pseudo reward with the original reward. 在这里,我们还应该使用一些权重因子来控制探索和利用的平衡。对于minigrid,我们让最后一个非零的原始奖励乘以1000,以放大原始目标的效果。我们还在minigrid empty8上进行了实验,以验证探索和利用之间权衡的重要性。在实验中,我们发现如果不使用权重因子1000,rnd代理根本无法学会达到目标,因为探索的比例太大。for item, rnd_rew in zip(data, reward): if self.intrinsic_reward_type == 'add': item['reward'] += rew if item['reward'] > 0 and item['reward'] <= 1: # for minigrid item['reward'] = 1000 * item['reward'] + rnd_rew else: item['reward'] += rnd_rew elif self.intrinsic_reward_type == 'new': item['intrinsic_reward'] = rnd_rew elif self.intrinsic_reward_type == 'assign': item['reward'] = rnd_rew
基准测试结果¶
因为在收集阶段,我们使用multinomial_sample来增加收集数据的多样性, 在评估阶段,我们使用argmax动作与环境交互,并且我们运行5个不同的种子并报告平均奖励。 在下面的实验结果中,x轴表示在训练过程中与环境交互的总环境步数。 在标记为“collector_step”的图中,y轴显示在收集阶段获得的奖励,表示为collect_reward; 在标记为“evaluator_step”的图中,y轴显示在评估阶段获得的奖励,表示为episode_return。 在稀疏奖励环境minigrid中,只有当代理达到目标时,代理才会获得正奖励,否则为零,并且其值将与达到目标所用的步数成反比。 在最简单的环境MiniGrid-Empty-8x8-v0中,不同的种子将具有相同的房间配置,最佳奖励约为0.96。 但在MiniGrid-FourRooms-v0中,不同的种子将具有不同的房间配置 并且相应的最佳奖励也不同,当episode_return的平均值大于0.6时,我们认为环境已被解决。
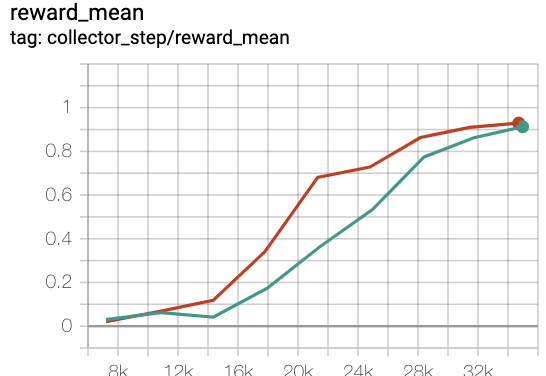
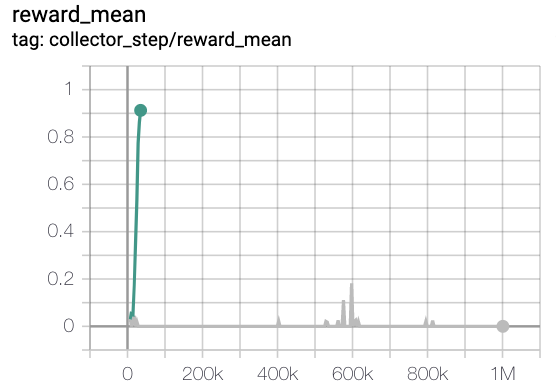
MiniGrid-Empty-8x8-v0(40k 环境步骤,每集回报均值>0.95)
绿线是 rnd-onppo-weight100
红线是onppo
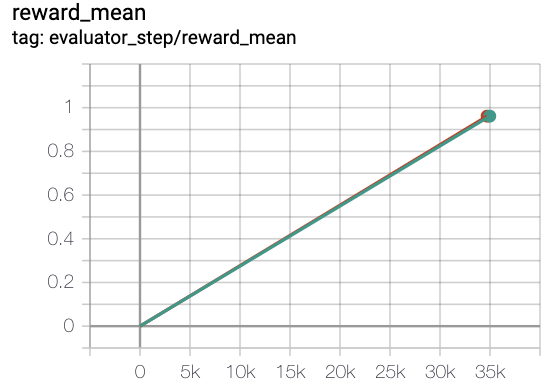
绿线是 rnd-onppo-weight100
灰色线是 rnd-onppo-noweight
MiniGrid-FourRooms-v0(20M环境步骤,每集回报均值>0.6)
红线是onppo
灰色线是 rnd-onppo-weight1000
绿线是 rnd-onppo-weight100
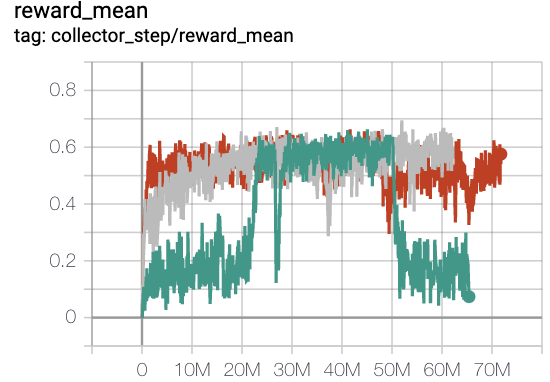

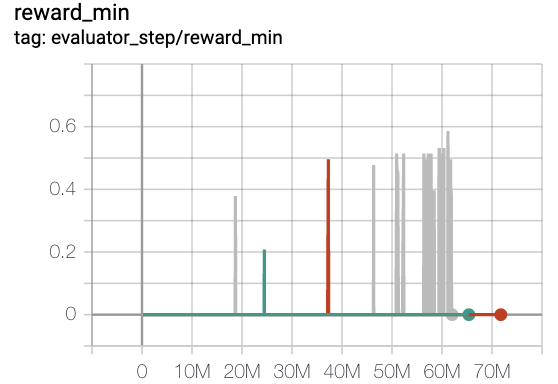
我们可以发现,在rnd中使用权重因子1000比使用100要好得多。我们假设这是因为在fourrooms中解决游戏所需的平均情节长度比在empty8中要大,因此fourrooms中的总累积折扣内在奖励比empty8中的要大。我们应该确保原始奖励与内在奖励相当,以便在利用和探索之间进行权衡。这提醒我们,原始奖励的权重因子应与解决游戏的总时间步长相关。
注意
如何确定内在奖励和原始外在奖励之间的相对权重可能是未来有价值的工作。
参考¶
Burda Y, Edwards H, Storkey A, 等. 通过随机网络蒸馏进行探索[J]. https://arxiv.org/abs/1810.12894v1. arXiv:1810.12894, 2018.
https://openai.com/blog/reinforcement-learning-with-prediction-based-rewards/