TD3BC¶
概述¶
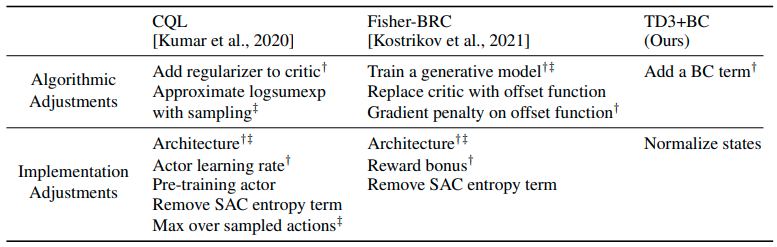
TD3BC,在2021年的论文《离线强化学习的极简方法》中提出,是一种简单的离线强化学习方法,其中仅对TD3进行了两项更改:在策略更新中添加了加权行为克隆损失,并对状态进行了归一化。与竞争方法不同,该方法没有对架构或基础超参数进行任何更改。由此产生的算法是一个简单的基线,易于实现和调整,同时通过去除先前方法的额外计算开销,将总体运行时间减少了一半以上。
快速事实¶
TD3BC 是一种离线强化学习算法。
TD3BC 基于 TD3 和 行为克隆。
关键方程或关键图表¶
TD3BC 简单来说就是在 TD3 中添加一个行为克隆项以规范策略:
\((\pi(s)-a)^2\) 是行为克隆项,作为正则化器,旨在推动策略倾向于数据集中包含的动作。超参数 \(\lambda\) 用于控制正则化器的强度。
假设动作范围为[−1, 1],BC项最多为4,然而Q的范围将是奖励规模的函数。因此,标量\(\lambda\)可以定义为:
这只是一个基于小批量中Q的平均绝对值的归一化项。这种公式化的另一个好处是,由于它依赖于Q的规模,因此可以跨任务归一化学习率。\(\alpha\)的默认值为2.5。
此外,每个小批量中的所有状态都被归一化,使得它们的均值为0,标准差为1。 这种归一化提高了学习策略的稳定性。
实现¶
默认配置定义如下:
- class ding.policy.td3_bc.TD3BCPolicy(cfg: EasyDict, model: Module | None = None, enable_field: List[str] | None = None)[source]¶
- Overview:
TD3_BC算法的策略类。
由于DDPG和TD3有许多共同点,我们可以通过更改
_actor_update_freq、_twin_critic和模型包装器中的噪声,轻松地从DDPG类派生出这个TD3_BC类。- Property:
学习模式, 收集模式, 评估模式
配置:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
td3_bc
RL policy register name, referto registryPOLICY_REGISTRYthis arg is optional,a placeholder2
cuda布尔
真
Whether to use cuda for network3
random_collect_size整数
25000
Number of randomly collectedtraining samples in replaybuffer when training starts.Default to 25000 forDDPG/TD3, 10000 forsac.4
model.twin_critic布尔
真
Whether to use two criticnetworks or only one.Default True for TD3,Clipped DoubleQ-learning method inTD3 paper.5
learn.learning_rate_actor浮点数
1e-3
Learning rate for actornetwork(aka. policy).6
learn.learning_rate_critic浮点数
1e-3
Learning rates for criticnetwork (aka. Q-network).7
learn.actor_update_freq整数
2
When critic network updatesonce, how many times will actornetwork update.Default 2 for TD3, 1for DDPG. DelayedPolicy Updates methodin TD3 paper.8
learn.noise布尔
真
Whether to add noise on targetnetwork’s action.Default True for TD3,False for DDPG.Target Policy Smoo-thing Regularizationin TD3 paper.9
learn.noise_range字典
dict(min=-0.5,max=0.5,)Limit for range of targetpolicy smoothing noise,aka. noise_clip.10
learn.-ignore_done布尔
假
Determine whether to ignoredone flag.Use ignore_done onlyin halfcheetah env.11
learn.-target_theta浮点数
0.005
Used for soft update of thetarget network.aka. Interpolationfactor in polyak averaging for targetnetworks.12
collect.-noise_sigma浮点数
0.1
Used for add noise during co-llection, through controllingthe sigma of distributionSample noise from distribution, Ornstein-Uhlenbeck process inDDPG paper, Guassianprocess in ours.
模型¶
这里我们提供了ContinuousQAC模型作为TD3BC的默认模型的示例。
- class ding.model.ContinuousQAC(obs_shape: int | SequenceType, action_shape: int | SequenceType | EasyDict, action_space: str, twin_critic: bool = False, actor_head_hidden_size: int = 64, actor_head_layer_num: int = 1, critic_head_hidden_size: int = 64, critic_head_layer_num: int = 1, activation: Module | None = ReLU(), norm_type: str | None = None, encoder_hidden_size_list: SequenceType | None = None, share_encoder: bool | None = False)[source]
- Overview:
与Q值演员-评论家(QAC)相关的算法的神经网络和计算图,例如DDPG/TD3/SAC。该模型现在支持连续和混合动作空间。ContinuousQAC由四部分组成:
actor_encoder、critic_encoder、actor_head和critic_head。编码器用于从各种观察中提取特征。头部用于预测相应的Q值或动作逻辑。在高维观察空间(如2D图像)中,我们通常为actor_encoder和critic_encoder使用共享编码器。在低维观察空间(如1D向量)中,我们通常使用不同的编码器。- Interfaces:
__init__,forward,compute_actor,compute_critic
- compute_actor(obs: Tensor) Dict[str, Tensor | Dict[str, Tensor]][source]
- Overview:
QAC 前向计算图用于演员部分,输入观察张量以预测动作或动作对数。
- Arguments:
x (
torch.Tensor): 输入的观测张量数据。
- Returns:
输出 (
Dict[str, Union[torch.Tensor, Dict[str, torch.Tensor]]]): 根据动作空间变化的Actor输出字典:regression,reparameterization,hybrid.
- ReturnsKeys (regression):
动作 (
torch.Tensor): 与action_shape大小相同的连续动作,通常在 DDPG/TD3 中使用。
- ReturnsKeys (reparameterization):
logit (
Dict[str, torch.Tensor]): 预测的重新参数化动作logit,通常在SAC中使用。它是一个包含两个张量的列表:mu和sigma。前者是高斯分布的均值,后者是高斯分布的标准差。
- ReturnsKeys (hybrid):
logit (
torch.Tensor): 预测的离散动作类型的logit,它将与action_type_shape具有相同的维度,即所有可能的离散动作类型。action_args (
torch.Tensor): 连续动作参数,大小与action_args_shape相同。
- Shapes:
obs (
torch.Tensor): \((B, N0)\), B 是批量大小,N0 对应于obs_shape。动作 (
torch.Tensor): \((B, N1)\), B 是批量大小,N1 对应于action_shape。logit.mu (
torch.Tensor): \((B, N1)\), B 是批量大小,N1 对应于action_shape。logit.sigma (
torch.Tensor): \((B, N1)\), B 是批量大小。logit (
torch.Tensor): \((B, N2)\), B 是批量大小,N2 对应于action_shape.action_type_shape。action_args (
torch.Tensor): \((B, N3)\), B 是批量大小,N3 对应于action_shape.action_args_shape。
- Examples:
>>> # Regression mode >>> model = ContinuousQAC(64, 6, 'regression') >>> obs = torch.randn(4, 64) >>> actor_outputs = model(obs,'compute_actor') >>> assert actor_outputs['action'].shape == torch.Size([4, 6]) >>> # Reparameterization Mode >>> model = ContinuousQAC(64, 6, 'reparameterization') >>> obs = torch.randn(4, 64) >>> actor_outputs = model(obs,'compute_actor') >>> assert actor_outputs['logit'][0].shape == torch.Size([4, 6]) # mu >>> actor_outputs['logit'][1].shape == torch.Size([4, 6]) # sigma
- compute_critic(inputs: Dict[str, Tensor]) Dict[str, Tensor][来源]
- Overview:
QAC前向计算图用于评论家部分,输入观察和动作张量以预测Q值。
- Arguments:
输入 (
Dict[str, torch.Tensor]): 输入数据的字典,包括obs和action张量,在混合动作空间中还包含logit和action_args张量。
- ArgumentsKeys:
obs: (
torch.Tensor): 观测张量数据,现在支持一批一维向量数据。动作 (
Union[torch.Tensor, Dict]): 与action_shape大小相同的连续动作。logit (
torch.Tensor): 离散动作的logit,仅在混合动作空间中存在。action_args (
torch.Tensor): 连续动作参数,仅在混合动作空间中存在。
- Returns:
输出 (
Dict[str, torch.Tensor]): QAC前向计算图的输出字典,包括q_value。
- ReturnKeys:
q_value (
torch.Tensor): Q值张量,大小与批量大小相同。
- Shapes:
obs (
torch.Tensor): \((B, N1)\), 其中 B 是批量大小,N1 是obs_shape。logit (
torch.Tensor): \((B, N2)\), B 是批量大小,N2 对应于action_shape.action_type_shape。action_args (
torch.Tensor): \((B, N3)\), B 是批量大小,N3 对应于action_shape.action_args_shape。动作 (
torch.Tensor): \((B, N4)\), 其中 B 是批量大小,N4 是action_shape。q_value (
torch.Tensor): \((B, )\), 其中 B 是批量大小。
- Examples:
>>> inputs = {'obs': torch.randn(4, 8), 'action': torch.randn(4, 1)} >>> model = ContinuousQAC(obs_shape=(8, ),action_shape=1, action_space='regression') >>> assert model(inputs, mode='compute_critic')['q_value'].shape == (4, ) # q value
- forward(inputs: Tensor | Dict[str, Tensor], mode: str) Dict[str, Tensor][来源]
- Overview:
QAC前向计算图,输入观测张量以预测Q值或动作逻辑值。不同的
mode将使用不同的网络模块进行前向传播,以获得不同的输出并节省计算。- Arguments:
输入 (
Union[torch.Tensor, Dict[str, torch.Tensor]]): 用于前向计算图的输入数据,对于compute_actor,它是观察张量,对于compute_critic,它是包含观察和动作张量的字典数据。模式 (
str): 前向模式,所有模式都在这个类的开头定义。
- Returns:
输出 (
Dict[str, torch.Tensor]): QAC前向计算图的输出字典,其键值在不同的前向模式中有所不同。
- Examples (Actor):
>>> # Regression mode >>> model = ContinuousQAC(64, 6, 'regression') >>> obs = torch.randn(4, 64) >>> actor_outputs = model(obs,'compute_actor') >>> assert actor_outputs['action'].shape == torch.Size([4, 6]) >>> # Reparameterization Mode >>> model = ContinuousQAC(64, 6, 'reparameterization') >>> obs = torch.randn(4, 64) >>> actor_outputs = model(obs,'compute_actor') >>> assert actor_outputs['logit'][0].shape == torch.Size([4, 6]) # mu >>> actor_outputs['logit'][1].shape == torch.Size([4, 6]) # sigma
- Examples (Critic):
>>> inputs = {'obs': torch.randn(4, 8), 'action': torch.randn(4, 1)} >>> model = ContinuousQAC(obs_shape=(8, ),action_shape=1, action_space='regression') >>> assert model(inputs, mode='compute_critic')['q_value'].shape == (4, ) # q value
基准测试¶
环境 |
最佳平均奖励 |
评估结果 |
配置链接 |
比较 |
|---|---|---|---|---|
猎豹 (中级专家) |
13037 |

|
d3rlpy(12124) |
|
Walker2d (中级专家) |
5066 |
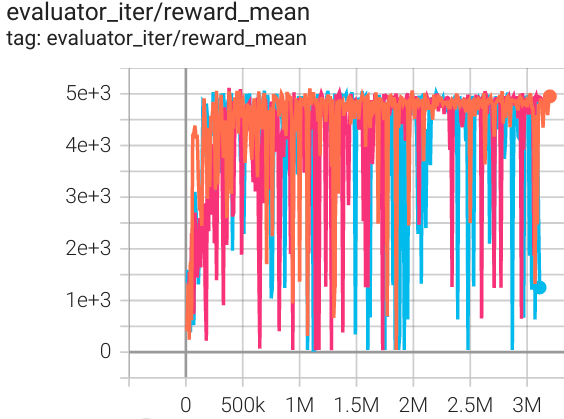
|
d3rlpy(5108) |
|
霍珀 (中级专家) |
3653 |
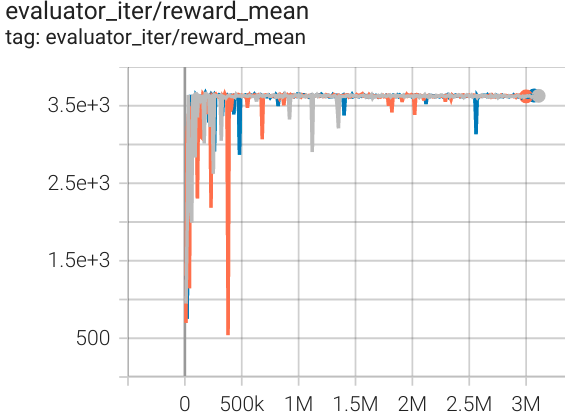
|
d3rlpy(3690) |
环境 |
随机 |
中等重放 |
中级专家 |
中等 |
专家 |
|---|---|---|---|---|---|
猎豹 |
1592 |
5192 |
13037 |
5257 |
13247 |
Walker2d |
345 |
1724 |
3653 |
3268 |
3664 |
霍珀 |
985 |
2317 |
5066 |
3826 |
5232 |
注意: 本基准测试中使用的D4RL环境可以在这里找到。
参考文献¶
Scott Fujimoto, Shixiang Shane Gu: “离线强化学习的极简方法”, 2021; [https://arxiv.org/abs/2106.06860 arXiv:2106.06860].
Scott Fujimoto, Herke van Hoof, David Meger: “解决Actor-Critic方法中的函数逼近误差问题”,2018年;[http://arxiv.org/abs/1802.09477 arXiv:1802.09477].