TREX¶
概述¶
TREX(轨迹排名奖励外推)首次在通过观察的逆强化学习外推次优演示中提出,它使用排名演示来推断奖励函数。 与之前的方法不同,TREX寻求一个能够解释演示排名的奖励函数,而不是为演示辩护。这种方法在实践中被证明具有从高度次优的演示中学习良好策略的潜力。此外,预测的奖励仅依赖于观察,而不依赖于动作。
快速事实¶
TREX 是一种逆向强化学习(IRL)算法,可以与任何 RL 算法结合使用。
TREX中使用的演示需要排名信息。
奖励函数优化可以看作是一个简单的二元分类问题。
TREX 能够在提供基于时间的噪声排名时推断出有意义的奖励函数。
伪代码¶
在伪代码中,theta 表示奖励函数的参数,ti 表示在示范中采样的轨迹。函数 L 是用于训练奖励函数的损失,下面将进行解释。
关键方程或关键图表¶
奖励函数的损失:
其中 ti, tj 是演示中的轨迹。实际上,这个损失函数只是一个二元分类损失函数。其目标是找出两个轨迹中更好的一个。 函数 P 定义如下:
最终的损失函数采用交叉熵形式:
扩展¶
TREX 可以与有噪声的排名演示一起工作,并且对高达约15%的成对错误噪声相对稳健。
TREX 可以与基于时间的排名一起工作。我们可以仅使用从训练某个RL代理生成的数据。排名可以通过生成轨迹的时间来估计。
实现¶
TREX 可以与以下方法结合使用:
给定由RL算法或人类知识生成的演示(仅需要观察和排名),TREX将推断环境的奖励函数。然后,该奖励函数可以应用于PPO或SAC等RL算法,以在训练时估计奖励。
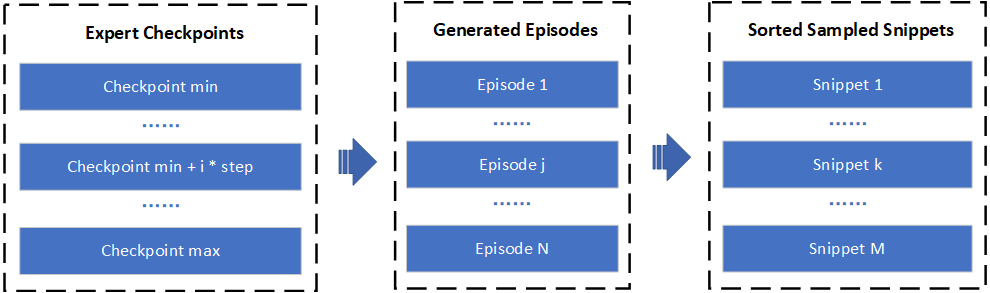
在实践中,演示是由我们实现中的预训练策略生成的。首先,我们需要训练一个RL代理,并每10000次迭代保存检查点。然后,我们使用不同的代理生成演示,并根据最终奖励对它们进行排名。 根据论文,我们还实现了多种数据增强技术。在默认设置中,我们随机采样部分轨迹并生成新的演示,其数量与原始演示相同。用于训练奖励函数的最终数据集包含原始演示和生成的演示。请注意,轨迹中的后期状态通常比开始状态更好,因此我们确保:
奖励模型的输入是观察值,其输出是预测的奖励值。默认的奖励模型定义如下:
- class ding.reward_model.TrexRewardModel(config: EasyDict, device: str, tb_logger: SummaryWriter)[来源]
- Overview:
Trex奖励模型类 (https://arxiv.org/pdf/1904.06387.pdf)
- Interface:
estimate,train,load_expert_data,collect_data,clear_date,__init__,_train,- Config:
ID
符号
类型
默认值
描述
其他(形状)
1
type字符串
trex
Reward model register name, referto registryREWARD_MODEL_REGISTRY3
learning_rate浮点数
0.00001
learning rate for optimizer4
update_per_collect整数
100
Number of updates per collect5
num_trajs整数
0
Number of downsampled full trajectories6
num_snippets整数
6000
Number of short subtrajectories to sample
实验 Benchmark¶
环境 |
最佳平均奖励 |
PPO |
TREX+PPO |
配置链接 |
|---|---|---|---|---|
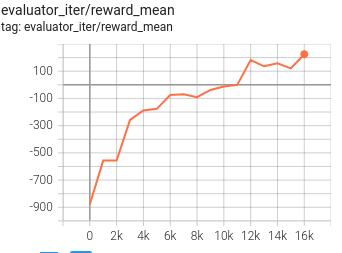
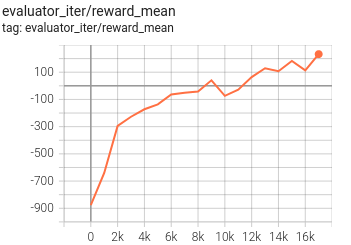
月球着陆器 |
2M 环境步骤, 奖励 200 |
|
|
我们在PPO训练过程中每1000次迭代(1000-9000)使用代理生成演示。尽管使用的最佳演示的奖励约为-50(次优),但通过trex训练的代理可以达到更好的分数(200)。
参考¶
Daniel S. Brown, Wonjoon Goo, Prabhat Nagarajan, Scott Niekum: “通过观察的逆向强化学习从次优演示中推断”,2019; arXiv:1904.06387. https://arxiv.org/abs/1904.06387