搜索 API
edit搜索 API
edit一个搜索由一个或多个查询组成,这些查询被组合并发送到Elasticsearch。 匹配搜索查询的文档会在响应的命中或搜索结果中返回。
搜索可能还包含用于更好地处理其查询的附加信息。例如,搜索可能被限制在特定索引中,或者只返回特定数量的结果。
您可以使用搜索 API来搜索和
聚合存储在 Elasticsearch 数据流或索引中的数据。
API 的 query 请求体参数接受使用
查询 DSL编写的查询。
运行搜索
edit以下请求使用match查询搜索my-index-000001。该查询匹配user.id值为kimchy的文档。
GET /my-index-000001/_search
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
API响应返回与查询匹配的前10个文档,位于hits.hits属性中。
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "my-index-000001",
"_id": "kxWFcnMByiguvud1Z8vC",
"_score": 1.3862942,
"_source": {
"@timestamp": "2099-11-15T14:12:12",
"http": {
"request": {
"method": "get"
},
"response": {
"bytes": 1070000,
"status_code": 200
},
"version": "1.1"
},
"message": "GET /search HTTP/1.1 200 1070000",
"source": {
"ip": "127.0.0.1"
},
"user": {
"id": "kimchy"
}
}
}
]
}
}
常用搜索选项
edit您可以使用以下选项来自定义您的搜索。
查询DSL
查询DSL 支持多种查询类型,您可以混合使用这些查询类型以获得所需的结果。查询类型包括:
聚合
您可以使用搜索聚合来获取搜索结果的统计信息和其他分析。聚合帮助您回答以下问题:
- 我的服务器的平均响应时间是多少?
- 我的网络上用户访问最多的IP地址是什么?
- 每个客户的总交易收入是多少?
搜索多个数据流和索引
您可以使用逗号分隔的值和类似grep的索引模式在同一请求中搜索多个数据流和索引。您甚至可以提升来自特定索引的搜索结果。请参阅搜索多个数据流和索引。
分页搜索结果
默认情况下,搜索仅返回前10个匹配的结果。要检索更多或更少的文档,请参阅分页搜索结果。
检索选定字段
搜索响应的 hits.hits 属性包括每个命中的完整文档
_source。要仅检索 _source 或其他字段的一个子集,请参阅 检索选定字段。
排序搜索结果
默认情况下,搜索结果按_score排序,这是一个相关性分数,用于衡量每个文档与查询的匹配程度。要自定义这些分数的计算,请使用script_score查询。要按其他字段值对搜索结果进行排序,请参阅排序搜索结果。
运行异步搜索
Elasticsearch 搜索旨在快速处理大量数据,通常在毫秒内返回结果。因此,搜索默认是同步的。搜索请求会等待完整结果后再返回响应。
然而,对于跨大数据集或多个集群的搜索,完整结果可能需要更长时间。
为了避免长时间等待,您可以运行一个异步,或async,搜索。一个异步搜索允许您现在检索长时间运行的搜索的部分结果,并在稍后获取完整结果。
定义仅在查询中存在的字段
edit与其对数据进行索引然后再进行搜索,您可以定义仅作为搜索查询一部分存在的运行时字段。您可以在搜索请求中指定一个runtime_mappings部分来定义运行时字段,该字段可以选择性地包含一个Painless脚本。
例如,以下查询定义了一个名为 day_of_week 的运行时字段。
所包含的脚本根据 @timestamp 字段的值计算星期几,并使用 emit 返回计算出的值。
查询还包括一个对day_of_week进行操作的terms aggregation。
GET /my-index-000001/_search
{
"runtime_mappings": {
"day_of_week": {
"type": "keyword",
"script": {
"source":
"""emit(doc['@timestamp'].value.dayOfWeekEnum
.getDisplayName(TextStyle.FULL, Locale.ENGLISH))"""
}
}
},
"aggs": {
"day_of_week": {
"terms": {
"field": "day_of_week"
}
}
}
}
响应包括基于day_of_week运行时字段的聚合。
在buckets下是一个值为Sunday的key。查询动态地
基于day_of_week运行时字段中定义的脚本计算此值,而无需索引该字段。
{
...
***
"aggregations" : {
"day_of_week" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Sunday",
"doc_count" : 5
}
]
}
}
}
搜索超时
edit默认情况下,搜索请求不会超时。请求会等待从每个分片获取完整结果后再返回响应。
虽然异步搜索是为长时间运行的搜索而设计的,但您也可以使用timeout参数来指定每个分片完成搜索的时间。每个分片在指定的时间段内收集命中结果。如果在时间段结束时收集未完成,Elasticsearch将仅使用到该点为止累积的命中结果。搜索请求的总体延迟取决于搜索所需的分片数量和并发分片请求的数量。
GET /my-index-000001/_search
{
"timeout": "2s",
"query": {
"match": {
"user.id": "kimchy"
}
}
}
要为所有搜索请求设置集群范围的默认超时,请使用集群设置 API配置search.default_search_timeout。如果在请求中没有传递timeout参数,则使用此全局超时持续时间。如果全局搜索超时在搜索请求完成之前到期,则使用任务取消取消请求。search.default_search_timeout设置默认为-1(无超时)。
搜索取消
edit您可以使用任务管理 API取消搜索请求。当客户端的 HTTP 连接关闭时,Elasticsearch 也会自动取消搜索请求。我们建议您设置客户端在搜索请求被中止或超时时关闭 HTTP 连接。
跟踪总点击量
edit通常,如果不访问所有匹配项,就无法准确计算总点击次数,这对于匹配大量文档的查询来说是代价高昂的。track_total_hits参数允许您控制应如何跟踪点击总数。
鉴于通常只需要一个点击次数的下限,例如“至少有10000次点击”,默认设置为10,000。这意味着请求将准确计算最多10,000次点击的总点击次数。如果您不需要在某个阈值之后准确的总点击次数,这是一个加快搜索速度的好方法。
当设置为true时,搜索响应将始终准确跟踪与查询匹配的点击次数(例如,当track_total_hits设置为true时,total.relation将始终等于"eq")。否则,搜索响应中"total"对象中的"total.relation"决定了应如何解释"total.value"。值为"gte"表示"total.value"是与查询匹配的总点击次数的下限,而值为"eq"表示"total.value"是准确的计数。
GET my-index-000001/_search
{
"track_total_hits": true,
"query": {
"match" : {
"user.id" : "elkbee"
}
}
}
... 返回:
{
"_shards": ...
"timed_out": false,
"took": 100,
"hits": {
"max_score": 1.0,
"total" : {
"value": 2048,
"relation": "eq"
},
"hits": ...
}
}
也可以将 track_total_hits 设置为一个整数。
例如,以下查询将准确跟踪与查询匹配的最多100个文档的总点击数:
GET my-index-000001/_search
{
"track_total_hits": 100,
"query": {
"match": {
"user.id": "elkbee"
}
}
}
响应中的 hits.total.relation 将指示 hits.total.value 返回的值是准确的("eq")还是总数的下限("gte")。
例如,以下响应:
{
"_shards": ...
"timed_out": false,
"took": 30,
"hits": {
"max_score": 1.0,
"total": {
"value": 42,
"relation": "eq"
},
"hits": ...
}
}
... 表示在 total 中返回的命中次数是准确的。
如果匹配查询的总命中数大于在track_total_hits中设置的值,响应中的总命中数将指示返回的值是一个下限:
{
"_shards": ...
"hits": {
"max_score": 1.0,
"total": {
"value": 100,
"relation": "gte"
},
"hits": ...
}
}
如果你不需要跟踪点击总数,你可以通过将此选项设置为false来提高查询时间:
GET my-index-000001/_search
{
"track_total_hits": false,
"query": {
"match": {
"user.id": "elkbee"
}
}
}
... 返回:
最后,您可以通过在请求中将"track_total_hits"设置为true来强制进行准确的计数。
track_total_hits 参数允许你在命中计数的准确性和性能之间进行权衡。
一般来说,track_total_hits 的值越低,查询速度越快,
而设置为 false 会返回最快的结果。
将 track_total_hits 设置为 true 将导致 Elasticsearch 返回精确的命中计数,这可能会
影响查询性能,因为它禁用了
Max WAND
优化。
快速检查匹配的文档
edit如果你只想知道是否有任何文档匹配特定查询,你可以将 size 设置为 0 以表示我们对搜索结果不感兴趣。你还可以将 terminate_after 设置为 1 以表示一旦在每个分片上找到第一个匹配的文档,查询执行就可以终止。
GET /_search?q=user.id:elkbee&size=0&terminate_after=1
terminate_after 总是在 post_filter 之后应用,并在分片上收集到足够多的命中结果时停止查询以及聚合执行。尽管聚合中的文档计数可能不会反映响应中的 hits.total,因为聚合是在后过滤之前应用的。
响应将不包含任何命中结果,因为size被设置为0。hits.total将等于0,表示没有匹配的文档,或者大于0,表示在查询被提前终止时至少有这么多文档匹配查询。此外,如果查询被提前终止,响应中的terminated_early标志将被设置为true。某些查询能够直接从索引统计信息中检索命中计数,这比执行查询要快得多。在这些情况下,不会收集任何文档,返回的total.hits将高于terminate_after,并且terminated_early将被设置为false。
{
"took": 3,
"timed_out": false,
"terminated_early": true,
"_shards": {
"total": 1,
"successful": 1,
"skipped" : 0,
"failed": 0
},
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
响应中的 took 时间包含了处理此请求所花费的毫秒数,从节点接收到查询后不久开始,直到所有与搜索相关的工作完成,并且在将上述 JSON 返回给客户端之前。这意味着它包括了在线程池中等待的时间、在整个集群中执行分布式搜索以及收集所有结果的时间。
排序搜索结果
edit允许您在一个或多个特定字段上添加排序。每个排序也可以反转。排序是按字段级别定义的,特殊字段名称_score用于按分数排序,_doc用于按索引顺序排序。
假设以下索引映射:
PUT /my-index-000001
{
"mappings": {
"properties": {
"post_date": { "type": "date" },
"user": {
"type": "keyword"
},
"name": {
"type": "keyword"
},
"age": { "type": "integer" }
}
}
}
GET /my-index-000001/_search
{
"sort" : [
{ "post_date" : {"order" : "asc", "format": "strict_date_optional_time_nanos"}},
"user",
{ "name" : "desc" },
{ "age" : "desc" },
"_score"
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
_doc 除了作为最高效的排序方式外,没有实际的用途。
所以如果你不关心文档返回的顺序,那么你应该按 _doc 排序。这在滚动搜索结果时尤其有帮助。
排序值
edit搜索响应包括每个文档的sort值。使用format参数为日期格式指定sort值,适用于date和date_nanos字段。以下搜索返回post_date字段的sort值,格式为strict_date_optional_time_nanos。
GET /my-index-000001/_search
{
"sort" : [
{ "post_date" : {"format": "strict_date_optional_time_nanos"}}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
排序顺序
edit选项 order 可以有以下值:
|
|
按升序排序 |
|
|
按降序排序 |
当按 _score 排序时,顺序默认为 desc,而当按其他内容排序时,顺序默认为 asc。
排序模式选项
editElasticsearch 支持通过数组或多值字段进行排序。mode 选项控制选择哪个数组值来对该文档进行排序。mode 选项可以具有以下值:
|
|
选择最低值。 |
|
|
选择最高值。 |
|
|
使用所有值的总和作为排序值。仅适用于基于数字的数组字段。 |
|
|
使用所有值的平均值作为排序值。仅适用于基于数字的数组字段。 |
|
|
使用所有值的中位数作为排序值。仅适用于基于数字的数组字段。 |
默认的升序排序模式是 min — 选择最低值。默认的降序排序模式是 max — 选择最高值。
排序模式示例用法
edit在下面的示例中,字段 price 每个文档有多个价格。在这种情况下,结果将根据每个文档的平均价格按升序排序。
PUT /my-index-000001/_doc/1?refresh
{
"product": "chocolate",
"price": [20, 4]
}
POST /_search
{
"query" : {
"term" : { "product" : "chocolate" }
},
"sort" : [
{"price" : {"order" : "asc", "mode" : "avg"}}
]
}
排序数值字段
edit对于数值字段,还可以使用 numeric_type 选项将值从一种类型转换为另一种类型。
此选项接受以下值:["double", "long", "date", "date_nanos"],
并且在跨多个数据流或索引进行搜索时,如果排序字段映射不同,这可能会很有用。
例如,考虑这两个指数:
PUT /index_double
{
"mappings": {
"properties": {
"field": { "type": "double" }
}
}
}
PUT /index_long
{
"mappings": {
"properties": {
"field": { "type": "long" }
}
}
}
由于field在第一个索引中被映射为double,而在第二个索引中被映射为long,因此默认情况下无法使用此字段对查询两个索引的请求进行排序。但是,您可以使用numeric_type选项强制将其类型设置为其中一个,以便为所有索引强制指定特定类型:
POST /index_long,index_double/_search
{
"sort" : [
{
"field" : {
"numeric_type" : "double"
}
}
]
}
在上面的示例中,index_long 索引的值被转换为双精度浮点数,以便与 index_double 索引生成的值兼容。
也可以将浮点字段转换为 long,但请注意,在这种情况下,浮点数会被替换为小于或等于(如果值为负,则为大于或等于)参数的最大值,并且等于一个数学整数。
此选项还可用于将使用毫秒分辨率的 date 字段转换为使用纳秒分辨率的 date_nanos 字段。
例如,考虑这两个索引:
PUT /index_double
{
"mappings": {
"properties": {
"field": { "type": "date" }
}
}
}
PUT /index_long
{
"mappings": {
"properties": {
"field": { "type": "date_nanos" }
}
}
}
这些索引中的值以不同的分辨率存储,因此在这些字段上排序时,date 总是会在 date_nanos 之前排序(升序)。通过 numeric_type 类型选项,可以为排序设置单一分辨率,设置为 date 会将 date_nanos 转换为毫秒分辨率,而 date_nanos 则会将 date 字段中的值转换为纳秒分辨率:
POST /index_long,index_double/_search
{
"sort" : [
{
"field" : {
"numeric_type" : "date_nanos"
}
}
]
}
为了避免溢出,转换为 date_nanos 不能应用于1970年之前和2262年之后的日期,因为纳秒是用长整型表示的。
嵌套对象内的排序。
editElasticsearch 还支持根据一个或多个嵌套对象内的字段进行排序。嵌套字段排序支持具有以下属性的 nested 排序选项:
-
path - 定义在哪个嵌套对象上进行排序。实际的排序字段必须是该嵌套对象内的直接字段。 当按嵌套字段排序时,此字段是必需的。
-
filter -
一个过滤器,嵌套路径内的内部对象应与之匹配,以便其字段值在排序时被考虑。常见的做法是在嵌套过滤器或查询中重复查询/过滤。默认情况下,没有
filter是激活的。 -
max_children - 选择排序值时每个根文档要考虑的最大子项数量。默认为无限制。
-
nested -
与顶层
nested相同,但适用于当前嵌套对象内的另一个嵌套路径。
如果在排序中定义了嵌套字段但没有嵌套上下文,Elasticsearch 将会抛出错误。
嵌套排序示例
edit在下面的示例中,offer 是一个类型为 nested 的字段。
需要指定嵌套的 path;否则,Elasticsearch 不知道需要在哪个嵌套级别捕获排序值。
POST /_search
{
"query" : {
"term" : { "product" : "chocolate" }
},
"sort" : [
{
"offer.price" : {
"mode" : "avg",
"order" : "asc",
"nested": {
"path": "offer",
"filter": {
"term" : { "offer.color" : "blue" }
}
}
}
}
]
}
在下面的示例中,parent 和 child 字段是 nested 类型的。
需要在每个级别指定 nested.path;否则,Elasticsearch 不知道需要在哪个嵌套级别捕获排序值。
POST /_search
{
"query": {
"nested": {
"path": "parent",
"query": {
"bool": {
"must": {"range": {"parent.age": {"gte": 21}}},
"filter": {
"nested": {
"path": "parent.child",
"query": {"match": {"parent.child.name": "matt"}}
}
}
}
}
}
},
"sort" : [
{
"parent.child.age" : {
"mode" : "min",
"order" : "asc",
"nested": {
"path": "parent",
"filter": {
"range": {"parent.age": {"gte": 21}}
},
"nested": {
"path": "parent.child",
"filter": {
"match": {"parent.child.name": "matt"}
}
}
}
}
}
]
}
嵌套排序在按脚本排序和按地理距离排序时也受支持。
缺失值
edit参数 missing 指定了在排序字段缺失的情况下,文档应如何处理:missing 的值可以设置为 _last、_first 或自定义值(该值将作为缺失文档的排序值使用)。默认值为 _last。
例如:
GET /_search
{
"sort" : [
{ "price" : {"missing" : "_last"} }
],
"query" : {
"term" : { "product" : "chocolate" }
}
}
如果嵌套的内部对象与nested.filter不匹配,则使用缺失值。
忽略未映射的字段
edit默认情况下,如果字段没有关联的映射,搜索请求将会失败。unmapped_type 选项允许你忽略没有映射的字段,并且不对它们进行排序。该参数的值用于确定要发出的排序值。以下是使用方法的示例:
GET /_search
{
"sort" : [
{ "price" : {"unmapped_type" : "long"} }
],
"query" : {
"term" : { "product" : "chocolate" }
}
}
如果查询的任何一个索引没有为price字段定义映射,那么Elasticsearch会将其处理为类型为long的映射,并且该索引中的所有文档在此字段上都没有值。
地理距离排序
edit允许按 _geo_distance 排序。以下是一个示例,假设 pin.location 是一个类型为 geo_point 的字段:
GET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : [-70, 40],
"order" : "asc",
"unit" : "km",
"mode" : "min",
"distance_type" : "arc",
"ignore_unmapped": true
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
-
distance_type -
如何计算距离。可以是
arc(默认),或者是plane(更快,但在长距离和靠近极点时不够准确)。 -
mode -
当一个字段有多个地理点时该怎么办。默认情况下,在升序排序时考虑最短距离,在降序排序时考虑最长距离。支持的值有
min、max、median和avg。 -
unit -
计算排序值时使用的单位。默认是
m(米)。 -
ignore_unmapped -
指示是否应将未映射的字段视为缺失值。将其设置为
true等同于在字段排序中指定unmapped_type。默认值为false(未映射的字段会导致搜索失败)。
地理距离排序不支持可配置的缺失值:当文档没有用于距离计算的字段值时,距离将始终被视为等于 Infinity。
以下格式支持在提供坐标时使用:
经纬度作为属性
editGET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : {
"lat" : 40,
"lon" : -70
},
"order" : "asc",
"unit" : "km"
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
经纬度作为WKT字符串
edit格式为 Well-Known Text。
GET /_search
{
"sort": [
{
"_geo_distance": {
"pin.location": "POINT (-70 40)",
"order": "asc",
"unit": "km"
}
}
],
"query": {
"term": { "user": "kimchy" }
}
}
Geohash
editGET /_search
{
"sort": [
{
"_geo_distance": {
"pin.location": "drm3btev3e86",
"order": "asc",
"unit": "km"
}
}
],
"query": {
"term": { "user": "kimchy" }
}
}
经纬度作为数组
edit格式为 [lon, lat],注意,这里的经纬度顺序是为了符合 GeoJSON 的规范。
GET /_search
{
"sort": [
{
"_geo_distance": {
"pin.location": [ -70, 40 ],
"order": "asc",
"unit": "km"
}
}
],
"query": {
"term": { "user": "kimchy" }
}
}
多个参考点
edit多个地理位置点可以作为包含任何 geo_point 格式的数组传递,例如
GET /_search
{
"sort": [
{
"_geo_distance": {
"pin.location": [ [ -70, 40 ], [ -71, 42 ] ],
"order": "asc",
"unit": "km"
}
}
],
"query": {
"term": { "user": "kimchy" }
}
}
等等。
文档的最终距离将是文档中所有点到排序请求中所有点的最小/最大/平均(通过模式定义)距离。
基于脚本的排序
edit允许基于自定义脚本进行排序,这里是一个示例:
GET /_search
{
"query": {
"term": { "user": "kimchy" }
},
"sort": {
"_script": {
"type": "number",
"script": {
"lang": "painless",
"source": "doc['field_name'].value * params.factor",
"params": {
"factor": 1.1
}
},
"order": "asc"
}
}
}
跟踪分数
edit当对字段进行排序时,不会计算分数。通过将track_scores设置为true,分数仍将被计算和跟踪。
GET /_search
{
"track_scores": true,
"sort" : [
{ "post_date" : {"order" : "desc"} },
{ "name" : "desc" },
{ "age" : "desc" }
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
内存考虑
edit在排序时,相关的排序字段值会被加载到内存中。这意味着每个分片应该有足够的内存来容纳它们。对于基于字符串的类型,排序的字段不应被分析/分词。对于数值类型,如果可能的话,建议显式地将类型设置为更窄的类型(如short、integer和float)。
分页搜索结果
edit默认情况下,搜索返回前10个匹配的结果。要翻阅更大的结果集,您可以使用搜索API的from和size参数。from参数定义要跳过的命中数量,默认为0。size参数是返回的最大命中数量。这两个参数共同定义了一页结果。
GET /_search
{
"from": 5,
"size": 20,
"query": {
"match": {
"user.id": "kimchy"
}
}
}
避免使用 from 和 size 来分页过深或一次性请求过多结果。搜索请求通常跨越多个分片。每个分片必须将其请求的命中结果以及任何前几页的命中结果加载到内存中。对于深分页或大量结果集,这些操作可能会显著增加内存和 CPU 使用率,导致性能下降或节点故障。
默认情况下,您不能使用 from 和 size 来分页浏览超过 10,000 条记录。此限制是由 index.max_result_window 索引设置设定的安全措施。如果您需要分页浏览超过 10,000 条记录,请使用 search_after 参数。
Elasticsearch 使用 Lucene 的内部文档 ID 作为决胜因素。这些内部文档 ID 在相同数据的副本之间可能完全不同。在分页搜索结果时,您可能会偶尔发现具有相同排序值的文档没有被一致地排序。
Search after
edit您可以使用 search_after 参数,通过从前一页的 排序值 获取下一页的命中结果。
使用 search_after 需要多次搜索请求,且这些请求的 query 和 sort 值相同。第一步是运行一个初始请求。以下示例按两个字段(date 和 tie_breaker_id)对结果进行排序:
GET twitter/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
},
"sort": [
{"date": "asc"},
{"tie_breaker_id": "asc"}
]
}
搜索响应包括每个命中的sort值数组:
{
"took" : 17,
"timed_out" : false,
"_shards" : ...,
"hits" : {
"total" : ...,
"max_score" : null,
"hits" : [
...
{
"_index" : "twitter",
"_id" : "654322",
"_score" : null,
"_source" : ...,
"sort" : [
1463538855,
"654322"
]
},
{
"_index" : "twitter",
"_id" : "654323",
"_score" : null,
"_source" : ...,
"sort" : [
1463538857,
"654323"
]
}
]
}
}
要检索下一页的结果,请重复请求,从最后一个命中结果中获取sort值,并将其插入到search_after数组中:
GET twitter/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
},
"search_after": [1463538857, "654323"],
"sort": [
{"date": "asc"},
{"tie_breaker_id": "asc"}
]
}
每次检索新一页的结果时,通过更新search_after数组来重复此过程。如果在这些请求之间发生刷新,结果的顺序可能会改变,导致页面之间的结果不一致。为了防止这种情况,您可以创建一个时间点 (PIT),以在搜索过程中保留当前索引状态。
POST /my-index-000001/_pit?keep_alive=1m
API返回一个PIT ID。
{
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"_shards": ...
}
要获取结果的第一页,请提交一个带有sort参数的搜索请求。如果使用PIT,请在pit.id参数中指定PIT ID,并从请求路径中省略目标数据流或索引。
所有PIT搜索请求都会添加一个隐式的排序决胜字段,称为_shard_doc,
该字段也可以显式提供。
如果您不能使用PIT,我们建议您在sort中包含一个决胜字段。
这个决胜字段应包含每个文档的唯一值。
如果您不包含决胜字段,您的分页结果可能会遗漏或重复命中。
搜索请求在排序顺序为_shard_doc且不跟踪总命中数时,具有优化功能,使其更快。如果你想按顺序遍历所有文档,这是最有效的选项。
如果 sort 字段在某些目标数据流或索引中是 date,而在其他目标中是 date_nanos 字段,请使用 numeric_type 参数将值转换为单一分辨率,并使用 format 参数为 sort 字段指定一个 日期格式。否则,Elasticsearch 将无法在每个请求中正确解释搜索后参数。
GET /_search
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{"@timestamp": {"order": "asc", "format": "strict_date_optional_time_nanos", "numeric_type" : "date_nanos" }}
]
}
搜索响应包括每个命中的sort值数组。如果你使用了PIT,则会在每个命中的最后一个sort值中包含一个平局决胜器。
这个称为_shard_doc的平局决胜器会自动添加到使用PIT的每个搜索请求中。
_shard_doc值是PIT中的分片索引和Lucene的内部文档ID的组合,
它在每个文档中是唯一的,并且在PIT中是恒定的。
你也可以在搜索请求中显式添加平局决胜器以自定义顺序:
GET /_search
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{"@timestamp": {"order": "asc", "format": "strict_date_optional_time_nanos"}},
{"_shard_doc": "desc"}
]
}
{
"pit_id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"took" : 17,
"timed_out" : false,
"_shards" : ...,
"hits" : {
"total" : ...,
"max_score" : null,
"hits" : [
...
{
"_index" : "my-index-000001",
"_id" : "FaslK3QBySSL_rrj9zM5",
"_score" : null,
"_source" : ...,
"sort" : [
"2021-05-20T05:30:04.832Z",
4294967298
]
}
]
}
}
要获取下一页的结果,请使用最后一个命中的排序值(包括平局打破器)作为search_after参数重新运行之前的搜索。如果使用PIT,请在pit.id参数中使用最新的PIT ID。搜索的query和sort参数必须保持不变。如果提供了from参数,则必须为0(默认)或-1。
GET /_search
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{"@timestamp": {"order": "asc", "format": "strict_date_optional_time_nanos"}}
],
"search_after": [
"2021-05-20T05:30:04.832Z",
4294967298
],
"track_total_hits": false
}
您可以重复此过程以获取其他页面的结果。如果使用PIT,您可以使用每个搜索请求的keep_alive参数来延长PIT的保留期。
完成后,您应该删除您的PIT。
DELETE /_pit
{
"id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA=="
}
滚动搜索结果
edit我们不再推荐使用滚动API进行深度分页。如果你需要在分页超过10,000条记录时保留索引状态,请使用search_after参数与时间点(PIT)。
虽然一个 search 请求返回一页结果,但 scroll API 可以用于从一个搜索请求中检索大量结果(甚至所有结果),其方式与在传统数据库中使用游标的方式非常相似。
滚动不适用于实时用户请求,而是用于处理大量数据,例如为了将一个数据流或索引的内容重新索引到一个具有不同配置的新数据流或索引中。
从滚动请求返回的结果反映了数据流或索引在最初搜索请求时的状态,就像一个时间快照。随后对文档的更改(索引、更新或删除)只会影响后续的搜索请求。
为了使用滚动功能,初始搜索请求应在查询字符串中指定scroll参数,该参数告诉Elasticsearch应该保持“搜索上下文”活动的时间(参见保持搜索上下文活动),例如?scroll=1m。
POST /my-index-000001/_search?scroll=1m
{
"size": 100,
"query": {
"match": {
"message": "foo"
}
}
}
上述请求的结果包括一个_scroll_id,它应该传递给scroll API,以便检索下一批结果。
POST /_search/scroll { "scroll" : "1m", "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==" }
|
|
|
|
参数 |
|
|
参数 |
参数size允许您配置每次返回结果批次中的最大命中数。每次调用scroll API都会返回下一批结果,直到没有更多结果返回为止,即hits数组为空。
初始搜索请求和每个后续的滚动请求都会返回一个_scroll_id。虽然_scroll_id在请求之间可能会发生变化,但它并不总是变化——无论如何,只应使用最近收到的_scroll_id。
如果请求指定了聚合,只有初始搜索响应会包含聚合结果。
滚动请求在排序顺序为_doc时具有优化,使其更快。如果你想按任意顺序遍历所有文档,这是最有效的选项:
GET /_search?scroll=1m
{
"sort": [
"_doc"
]
}
保持搜索上下文活跃
edit滚动返回在初始搜索请求时匹配搜索的所有文档。它忽略对这些文档的任何后续更改。
scroll_id 标识一个 搜索上下文,该上下文跟踪 Elasticsearch 需要返回正确文档的所有内容。搜索上下文由初始请求创建,并通过后续请求保持活动状态。
参数 scroll(传递给 search 请求和每个 scroll 请求)告诉 Elasticsearch 它应该保持搜索上下文活动的时间。
它的值(例如 1m,参见 时间单位)不需要足够长以处理所有数据 — 它只需要足够长以处理前一批结果。每个 scroll 请求(带有 scroll 参数)设置一个新的到期时间。如果 scroll 请求没有传递 scroll 参数,那么搜索上下文将作为 该 scroll 请求的一部分被释放。
通常,后台合并过程通过将较小的段合并在一起,以创建新的、更大的段来优化索引。一旦不再需要较小的段,它们就会被删除。这个过程在滚动期间继续进行,但打开的搜索上下文会阻止旧段被删除,因为它们仍在使用中。
保持旧段落存活意味着需要更多的磁盘空间和文件句柄。确保您已配置节点以拥有充足的可用文件句柄。请参阅文件描述符。
此外,如果一个分段包含已删除或更新的文档,那么搜索上下文必须跟踪该分段中的每个文档在初始搜索请求时是否处于活动状态。如果在一个受持续删除或更新影响的索引上有许多打开的滚动操作,请确保您的节点有足够的堆空间。
为了防止因打开过多滚动而引起的问题,用户不允许打开超过一定限制的滚动。默认情况下,最大打开的滚动数为500。此限制可以通过search.max_open_scroll_context集群设置进行更新。
您可以使用节点统计信息 API来检查有多少搜索上下文是打开的:
GET /_nodes/stats/indices/search
清除滚动
edit当超过scroll超时时间时,搜索上下文会自动被移除。然而,保持滚动打开是有代价的,如前一节所述,因此应在使用完滚动后立即使用clear-scroll API显式清除滚动:
DELETE /_search/scroll
{
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
可以传递多个滚动ID作为数组:
DELETE /_search/scroll
{
"scroll_id" : [
"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==",
"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAABFmtSWWRRWUJrU2o2ZExpSGJCVmQxYUEAAAAAAAAAAxZrUllkUVlCa1NqNmRMaUhiQlZkMWFBAAAAAAAAAAIWa1JZZFFZQmtTajZkTGlIYkJWZDFhQQAAAAAAAAAFFmtSWWRRWUJrU2o2ZExpSGJCVmQxYUEAAAAAAAAABBZrUllkUVlCa1NqNmRMaUhiQlZkMWFB"
]
}
所有搜索上下文都可以通过_all参数清除:
DELETE /_search/scroll/_all
The scroll_id 也可以作为查询字符串参数或在请求体中传递。
多个滚动ID可以作为逗号分隔的值传递:
DELETE /_search/scroll/DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==,DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAABFmtSWWRRWUJrU2o2ZExpSGJCVmQxYUEAAAAAAAAAAxZrUllkUVlCa1NqNmRMaUhiQlZkMWFBAAAAAAAAAAIWa1JZZFFZQmtTajZkTGlIYkJWZDFhQQAAAAAAAAAFFmtSWWRRWUJrU2o2ZExpSGJCVmQxYUEAAAAAAAAABBZrUllkUVlCa1NqNmRMaUhiQlZkMWFB
分片滚动
edit在分页浏览大量文档时,将搜索分成多个切片以便独立处理它们可能会很有帮助:
GET /my-index-000001/_search?scroll=1m
{
"slice": {
"id": 0,
"max": 2
},
"query": {
"match": {
"message": "foo"
}
}
}
GET /my-index-000001/_search?scroll=1m
{
"slice": {
"id": 1,
"max": 2
},
"query": {
"match": {
"message": "foo"
}
}
}
第一个请求返回的文档属于第一个切片(id: 0),第二个请求返回的文档属于第二个切片。由于最大切片数设置为2,因此这两个请求结果的并集等同于没有切片的滚动查询结果。默认情况下,首先在分片上进行分割,然后在每个分片上使用_id字段进行本地分割。本地分割遵循公式slice(doc) = floorMod(hashCode(doc._id), max))。
每个滚动是独立的,可以像任何滚动请求一样并行处理。
如果切片的数量大于分片的数量,切片过滤器在第一次调用时会非常慢,它的复杂度为O(N),并且每个切片的内存成本等于N位,其中N是分片中的文档总数。在几次调用后,过滤器应该会被缓存,后续的调用应该会更快,但你应该限制并行执行的切片查询的数量,以避免内存爆炸。
The 点时间 API 支持更高效的分区策略,并且不会遇到这个问题。如果可能,建议使用带切片的点时间搜索,而不是滚动搜索。
另一种避免这种高成本的方法是使用另一个字段的doc_values来进行切片。
该字段必须具有以下属性:
- 该字段是数值型的。
-
doc_values在该字段上已启用 - 每个文档应包含一个单一值。如果一个文档在指定字段上有多个值,则使用第一个值。
- 每个文档的值应在文档创建时设置一次,并且永不更新。这确保了每个切片都能获得确定性的结果。
- 该字段的基数应较高。这确保了每个切片获得大致相同数量的文档。
GET /my-index-000001/_search?scroll=1m
{
"slice": {
"field": "@timestamp",
"id": 0,
"max": 10
},
"query": {
"match": {
"message": "foo"
}
}
}
对于仅追加的时间序列索引,可以安全地使用timestamp字段。
从搜索中检索选定的字段
edit默认情况下,搜索响应中的每个命中项都包含文档的
_source,即索引文档时提供的整个JSON对象。有两种推荐的方法可以从搜索查询中检索选定的字段:
你可以使用这两种方法,尽管fields选项是首选的,因为它同时参考了文档数据和索引映射。在某些情况下,你可能希望使用其他方法来检索数据。
fields 选项
edit要在搜索响应中检索特定字段,请使用fields参数。由于它会参考索引映射,fields参数比直接引用_source提供了几个优势。具体来说,fields参数:
其他映射选项也同样被尊重,包括
ignore_above、ignore_malformed 和
null_value。
The fields 选项以与 Elasticsearch 索引它们的方式匹配的方式返回值。对于标准字段,这意味着 fields 选项会在 _source 中查找值,然后使用映射对其进行解析和格式化。在 _source 中找不到的选定字段将被跳过。
检索特定字段
edit以下搜索请求使用fields参数来检索user.id字段的值,所有以http.response.开头的字段,以及@timestamp字段的值。
使用对象表示法,您可以传递一个format参数来
自定义返回的日期或地理空间值的格式。
POST my-index-000001/_search
{
"query": {
"match": {
"user.id": "kimchy"
}
},
"fields": [
"user.id",
"http.response.*",
{
"field": "@timestamp",
"format": "epoch_millis"
}
],
"_source": false
}
默认情况下,文档元数据字段如 _id 或 _index 在请求的 fields 选项使用通配符模式如 * 时不会返回。然而,当使用字段名称显式请求时,_id、_routing、_ignored、_index 和 _version 元数据字段可以被检索。
响应始终返回一个数组
edit对于每个字段,fields 响应总是返回一个值数组,即使 _source 中只有一个值。这是因为 Elasticsearch 没有专门的数组类型,任何字段都可能包含多个值。fields 参数也不能保证数组值以特定顺序返回。有关更多背景信息,请参阅关于 数组 的映射文档。
响应包括每个命中项的fields部分中的值作为扁平列表。由于fields参数不获取整个对象,因此仅返回叶子字段。
{
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my-index-000001",
"_id" : "0",
"_score" : 1.0,
"fields" : {
"user.id" : [
"kimchy"
],
"@timestamp" : [
"4098435132000"
],
"http.response.bytes": [
1070000
],
"http.response.status_code": [
200
]
}
}
]
}
}
检索嵌套字段
edit详情
对于嵌套字段的字段响应与常规对象字段的响应略有不同。虽然常规对象字段中的叶子值以扁平列表的形式返回,但嵌套字段中的值被分组以保持原始嵌套数组中每个对象的独立性。
对于嵌套字段数组中的每个条目,值再次以扁平列表的形式返回,除非父嵌套对象中存在其他嵌套字段,在这种情况下,对更深的嵌套字段重复相同的处理过程。
给定以下映射,其中 user 是一个嵌套字段,在索引以下文档并检索 user 字段下的所有字段后:
PUT my-index-000001
{
"mappings": {
"properties": {
"group" : { "type" : "keyword" },
"user": {
"type": "nested",
"properties": {
"first" : { "type" : "keyword" },
"last" : { "type" : "keyword" }
}
}
}
}
}
PUT my-index-000001/_doc/1?refresh=true
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
POST my-index-000001/_search
{
"fields": ["*"],
"_source": false
}
响应将把first和last名字分组,而不是将它们作为一个扁平列表返回。
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [{
"_index": "my-index-000001",
"_id": "1",
"_score": 1.0,
"fields": {
"group" : ["fans"],
"user": [{
"first": ["John"],
"last": ["Smith"]
},
{
"first": ["Alice"],
"last": ["White"]
}
]
}
}]
}
}
嵌套字段将根据它们的嵌套路径进行分组,无论用于检索它们的模式如何。例如,如果您仅从前面的示例中查询 user.first 字段:
POST my-index-000001/_search
{
"fields": ["user.first"],
"_source": false
}
响应仅返回用户的名字,但仍然保持嵌套的 user 数组的结构:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [{
"_index": "my-index-000001",
"_id": "1",
"_score": 1.0,
"fields": {
"user": [{
"first": ["John"]
},
{
"first": ["Alice"]
}
]
}
}]
}
}
然而,当 fields 模式直接针对嵌套的 user 字段时,不会返回任何值,因为该模式不匹配任何叶子字段。
检索未映射的字段
edit详情
默认情况下,fields 参数仅返回映射字段的值。
然而,Elasticsearch 允许在 _source 中存储未映射的字段,例如
将 动态字段映射 设置为 false 或通过使用
带有 enabled: false 的对象字段。这些选项会禁用对象内容的解析和
索引。
要从 _source 中检索对象中的未映射字段,请在 fields 部分中使用 include_unmapped 选项:
PUT my-index-000001
{
"mappings": {
"enabled": false
}
}
PUT my-index-000001/_doc/1?refresh=true
{
"user_id": "kimchy",
"session_data": {
"object": {
"some_field": "some_value"
}
}
}
POST my-index-000001/_search
{
"fields": [
"user_id",
{
"field": "session_data.object.*",
"include_unmapped" : true
}
],
"_source": false
}
即使字段未映射,响应中也会包含在 session_data.object.* 路径下的字段结果。user_id 字段也是未映射的,但由于该字段模式的 include_unmapped 未设置为 true,因此它不会包含在响应中。
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my-index-000001",
"_id" : "1",
"_score" : 1.0,
"fields" : {
"session_data.object.some_field": [
"some_value"
]
}
}
]
}
}
忽略的字段值
edit详情
响应中的 fields 部分仅返回索引时有效的值。
如果您的搜索请求要求从某个字段获取值,但由于这些值格式错误或太大而被忽略,
这些值将在 ignored_field_values 部分中单独返回。
在这个例子中,我们索引了一个文档,该文档有一个被忽略的值,并且没有添加到索引中,因此在搜索结果中单独显示:
PUT my-index-000001
{
"mappings": {
"properties": {
"my-small" : { "type" : "keyword", "ignore_above": 2 },
"my-large" : { "type" : "keyword" }
}
}
}
PUT my-index-000001/_doc/1?refresh=true
{
"my-small": ["ok", "bad"],
"my-large": "ok content"
}
POST my-index-000001/_search
{
"fields": ["my-*"],
"_source": false
}
响应将在 ignored_field_values 路径下包含被忽略的字段值。
这些值是从文档的原始 JSON 源中检索的,并且是原始的,因此不会以任何方式格式化或处理,与成功索引的字段不同,后者在 fields 部分中返回。
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my-index-000001",
"_id" : "1",
"_score" : 1.0,
"_ignored" : [ "my-small"],
"fields" : {
"my-large": [
"ok content"
],
"my-small": [
"ok"
]
},
"ignored_field_values" : {
"my-small": [
"bad"
]
}
}
]
}
}
_source 选项
edit您可以使用 _source 参数来选择返回源文档的哪些字段。这被称为源过滤。
以下搜索API请求将_source请求体参数设置为false。文档源不会包含在响应中。
GET /_search
{
"_source": false,
"query": {
"match": {
"user.id": "kimchy"
}
}
}
要仅返回源字段的一个子集,请在 _source 参数中指定通配符 (*) 模式。以下搜索 API 请求仅返回 obj 字段及其属性的源。
GET /_search
{
"_source": "obj.*",
"query": {
"match": {
"user.id": "kimchy"
}
}
}
您还可以在 _source 字段中指定一个通配符模式数组。以下搜索 API 请求仅返回 obj1 和 obj2 字段及其属性的源。
GET /_search
{
"_source": [ "obj1.*", "obj2.*" ],
"query": {
"match": {
"user.id": "kimchy"
}
}
}
为了更精细的控制,您可以在_source参数中指定一个包含includes和excludes模式数组的对象。
如果指定了includes属性,则仅返回与其模式之一匹配的源字段。您可以使用excludes属性从此子集中排除字段。
如果未指定includes属性,则返回整个文档源,排除任何与excludes属性中的模式匹配的字段。
以下搜索API请求仅返回obj1和obj2字段及其属性的源,不包括任何子description字段。
GET /_search
{
"_source": {
"includes": [ "obj1.*", "obj2.*" ],
"excludes": [ "*.description" ]
},
"query": {
"term": {
"user.id": "kimchy"
}
}
}
其他检索数据的方法
edit文档的 _source 在 Lucene 中存储为单个字段。这种结构意味着即使你只请求其中的一部分,整个 _source 对象也必须被加载和解析。为了避免这种限制,你可以尝试其他加载字段的选项:
-
使用
docvalue_fields参数来获取所选字段的值。当返回支持doc值的字段(如关键字和日期)时,这是一个不错的选择。 -
使用
stored_fields参数来获取特定存储字段的值(使用store映射选项的字段)。
Elasticsearch 总是尝试从 _source 加载值。这种行为与源过滤具有相同的含义,即 Elasticsearch 需要加载并解析整个 _source 以仅检索一个字段。
文档值字段
edit您可以使用 docvalue_fields 参数在搜索响应中返回一个或多个字段的 doc values。
Doc values 存储与 _source 相同的值,但采用基于磁盘的列式结构,该结构针对排序和聚合进行了优化。由于每个字段是单独存储的,Elasticsearch 只读取请求的字段值,并可以避免加载整个文档 _source。
默认情况下,支持的字段会存储文档值。然而,文档值不支持text或
text_annotated字段。
以下搜索请求使用 docvalue_fields 参数来检索 user.id 字段的文档值,所有以 http.response. 开头的字段,以及 @timestamp 字段:
GET my-index-000001/_search
{
"query": {
"match": {
"user.id": "kimchy"
}
},
"docvalue_fields": [
"user.id",
"http.response.*",
{
"field": "date",
"format": "epoch_millis"
}
]
}
|
接受完整的字段名称和通配符模式。 |
|
|
使用对象表示法,您可以传递一个 |
您不能使用 docvalue_fields 参数来检索嵌套对象的文档值。如果您指定一个嵌套对象,搜索将返回该字段的空数组([ ])。要访问嵌套字段,请使用 inner_hits 参数的 docvalue_fields 属性。
存储字段
edit也可以通过使用store映射选项来存储单个字段的值。您可以使用stored_fields参数在搜索响应中包含这些存储的值。
参数 stored_fields 用于映射中明确标记为存储的字段,默认情况下是关闭的,通常不推荐使用。请改用 source filtering 来选择要返回的原始源文档的子集。
允许选择性地为每个由搜索命中表示的文档加载特定的存储字段。
GET /_search
{
"stored_fields" : ["user", "postDate"],
"query" : {
"term" : { "user" : "kimchy" }
}
}
* 可以用于加载文档中的所有存储字段。
一个空数组将导致仅返回每个命中的_id和_type,例如:
GET /_search
{
"stored_fields" : [],
"query" : {
"term" : { "user" : "kimchy" }
}
}
如果请求的字段未存储(store 映射设置为 false),它们将被忽略。
从文档本身获取的存储字段值始终作为数组返回。相反,像_routing这样的元数据字段永远不会作为数组返回。
同样,只有叶子字段可以通过 stored_fields 选项返回。如果指定了对象字段,它将被忽略。
单独使用时,stored_fields 无法用于加载嵌套对象中的字段——如果某个字段的路径中包含嵌套对象,则不会返回该存储字段的数据。要访问嵌套字段,stored_fields 必须在 inner_hits 块中使用。
禁用存储字段
edit要完全禁用存储的字段(以及元数据字段),请使用:_none_:
GET /_search
{
"stored_fields": "_none_",
"query" : {
"term" : { "user" : "kimchy" }
}
}
脚本字段
edit您可以使用 script_fields 参数来检索每个命中的 脚本评估(基于不同字段)。例如:
GET /_search
{
"query": {
"match_all": {}
},
"script_fields": {
"test1": {
"script": {
"lang": "painless",
"source": "doc['price'].value * 2"
}
},
"test2": {
"script": {
"lang": "painless",
"source": "doc['price'].value * params.factor",
"params": {
"factor": 2.0
}
}
}
}
}
脚本字段可以处理未存储的字段(如上例中的price),并允许返回自定义值(脚本的计算值)。
脚本字段也可以访问实际的 _source 文档,并通过使用 params['_source'] 从中提取特定元素以返回。
这里是一个示例:
GET /_search
{
"query": {
"match_all": {}
},
"script_fields": {
"test1": {
"script": "params['_source']['message']"
}
}
}
注意这里使用 _source 关键字来导航类似 json 的模型。
理解
doc['my_field'].value 和 params['_source']['my_field'] 之间的区别很重要。第一种,
使用 doc 关键字,会导致该字段的词条被加载到内存(缓存),这将导致更快的执行速度,但会消耗更多内存。此外,doc[...] 表示法仅允许简单值字段(您无法从中返回 json 对象),并且仅对非分析或基于单个词条的字段有意义。然而,如果可能的话,使用 doc 仍然是访问文档值的推荐方式,因为 _source 每次使用时都必须被加载和解析。使用 _source 非常慢。
搜索多个数据流和索引
edit要搜索多个数据流和索引,请将它们作为逗号分隔的值添加到搜索 API的请求路径中。
以下请求搜索 my-index-000001 和 my-index-000002 索引。
GET /my-index-000001,my-index-000002/_search
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
您还可以使用索引模式搜索多个数据流和索引。
以下请求针对 my-index-* 索引模式。该请求搜索集群中以 my-index- 开头的任何数据流或索引。
GET /my-index-*/_search
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
要在集群中搜索所有数据流和索引,请从请求路径中省略目标。或者,您可以使用 _all 或 *。
以下请求是等效的,并且搜索集群中的所有数据流和索引。
GET /_search
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
GET /_all/_search
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
GET /*/_search
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
索引提升
edit在搜索多个索引时,您可以使用 indices_boost 参数来提升来自一个或多个指定索引的结果。这在某些索引的命中比其他索引的命中更重要时非常有用。
您不能在数据流中使用indices_boost。
GET /_search
{
"indices_boost": [
{ "my-index-000001": 1.4 },
{ "my-index-000002": 1.3 }
]
}
别名和索引模式也可以使用:
GET /_search
{
"indices_boost": [
{ "my-alias": 1.4 },
{ "my-index*": 1.3 }
]
}
如果找到多个匹配项,将使用第一个匹配项。例如,如果一个索引包含在 alias1 中并且匹配 my-index* 模式,则会应用 1.4 的提升值。
折叠搜索结果
edit您可以使用 collapse 参数来根据字段值折叠搜索结果。折叠操作是通过为每个折叠键选择仅排序最高的文档来完成的。
例如,以下搜索按user.id折叠结果,并按http.response.bytes排序。
GET my-index-000001/_search
{
"query": {
"match": {
"message": "GET /search"
}
},
"collapse": {
"field": "user.id"
},
"sort": [
{
"http.response.bytes": {
"order": "desc"
}
}
],
"from": 0
}
响应中的总点击数表示未折叠时的匹配文档数量。 不同的组的总数是未知的。
用于折叠的字段必须是单值的 keyword 或 numeric 字段,并且启用了 doc_values。
折叠仅应用于顶部命中结果,不影响聚合。
展开折叠结果
edit也可以使用内部命中选项来展开每个折叠的顶部命中。
GET /my-index-000001/_search
{
"query": {
"match": {
"message": "GET /search"
}
},
"collapse": {
"field": "user.id",
"inner_hits": {
"name": "most_recent",
"size": 5,
"sort": [ { "@timestamp": "desc" } ]
},
"max_concurrent_group_searches": 4
},
"sort": [
{
"http.response.bytes": {
"order": "desc"
}
}
]
}
查看 内部命中 以获取支持的选项的完整列表以及响应的格式。
也可以为每个折叠的命中请求多个内部命中。当你想要获取折叠命中的多个表示时,这可能会很有用。
GET /my-index-000001/_search
{
"query": {
"match": {
"message": "GET /search"
}
},
"collapse": {
"field": "user.id",
"inner_hits": [
{
"name": "largest_responses",
"size": 3,
"sort": [
{
"http.response.bytes": {
"order": "desc"
}
}
]
},
{
"name": "most_recent",
"size": 3,
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}
]
},
"sort": [
"http.response.bytes"
]
}
群组的扩展是通过为响应中返回的每个折叠命中发送一个额外的查询来完成的,每个折叠命中对应一个inner_hit请求。如果你有太多的群组或inner_hit请求,这可能会显著减慢你的搜索速度。
请求参数 max_concurrent_group_searches 可以用于控制此阶段允许的最大并发搜索数量。默认值基于数据节点的数量和默认搜索线程池大小。
collapse 不能与 scroll 一起使用。
使用 search_after 进行折叠
edit字段折叠可以与search_after参数一起使用。使用search_after仅在排序和折叠同一字段时才受支持。也不允许使用次要排序。例如,我们可以在使用search_after分页浏览结果时,对user.id进行折叠和排序:
GET /my-index-000001/_search
{
"query": {
"match": {
"message": "GET /search"
}
},
"collapse": {
"field": "user.id"
},
"sort": [ "user.id" ],
"search_after": ["dd5ce1ad"]
}
重新评分折叠结果
edit您可以将字段折叠与rescore搜索参数一起使用。
重新评分器会在每个分片上为每个折叠字段运行排名最高的文档。
为了保持可靠的顺序,建议将共享相同折叠字段值的文档聚集在一个分片上。
这可以通过在索引期间将折叠字段值指定为路由键来实现:
POST /my-index-000001/_doc?routing=xyz { "@timestamp": "2099-11-15T13:12:00", "message": "You know for search!", "user.id": "xyz" }
通过这样做,您可以保证每个折叠键在全球范围内只重新评分一个顶级文档。
以下请求在 user.id 字段上使用字段折叠,然后使用 查询重打分器 对顶级组进行重打分:
GET /my-index-000001/_search
{
"query": {
"match": {
"message": "you know for search"
}
},
"collapse": {
"field": "user.id"
},
"rescore" : {
"window_size" : 50,
"query" : {
"rescore_query" : {
"match_phrase": {
"message": "you know for search"
}
},
"query_weight" : 0.3,
"rescore_query_weight" : 1.4
}
}
}
Rescorers 不会应用于 内部命中。
折叠的第二级
edit支持第二级折叠,并应用于inner_hits。
例如,以下搜索按geo.country_name折叠结果。
在每个geo.country_name中,内部点击按user.id折叠。
第二级折叠不允许 inner_hits。
GET /my-index-000001/_search
{
"query": {
"match": {
"message": "GET /search"
}
},
"collapse": {
"field": "geo.country_name",
"inner_hits": {
"name": "by_location",
"collapse": { "field": "user.id" },
"size": 3
}
}
}
{
"hits" : {
"hits" : [
{
"_index" : "my-index-000001",
"_id" : "oX9uXXoB0da05OCR3adK",
"_score" : 0.5753642,
"_source" : {
"@timestamp" : "2099-11-15T14:12:12",
"geo" : {
"country_name" : "Amsterdam"
},
"http" : {
"request" : {
"method" : "get"
},
"response" : {
"bytes" : 1070000,
"status_code" : 200
},
"version" : "1.1"
},
"message" : "GET /search HTTP/1.1 200 1070000",
"source" : {
"ip" : "127.0.0.1"
},
"user" : {
"id" : "kimchy"
}
},
"fields" : {
"geo.country_name" : [
"Amsterdam"
]
},
"inner_hits" : {
"by_location" : {
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "my-index-000001",
"_id" : "oX9uXXoB0da05OCR3adK",
"_score" : 0.5753642,
"_source" : {
"@timestamp" : "2099-11-15T14:12:12",
"geo" : {
"country_name" : "Amsterdam"
},
"http" : {
"request" : {
"method" : "get"
},
"response" : {
"bytes" : 1070000,
"status_code" : 200
},
"version" : "1.1"
},
"message" : "GET /search HTTP/1.1 200 1070000",
"source" : {
"ip" : "127.0.0.1"
},
"user" : {
"id" : "kimchy"
}
},
"fields" : {
"user.id" : [
"kimchy"
]
}
}
]
}
}
}
}
]
}
}
跟踪分数
edit当 collapse 与 sort 在字段上一起使用时,不会计算分数。
将 track_scores 设置为 true 会指示 Elasticsearch 计算并跟踪分数。
过滤搜索结果
edit您可以使用两种方法来过滤搜索结果:
后置过滤器
edit当您使用 post_filter 参数来过滤搜索结果时,搜索命中是在聚合计算之后进行过滤的。后置过滤器对聚合结果没有影响。
例如,您正在销售具有以下属性的衬衫:
PUT /shirts
{
"mappings": {
"properties": {
"brand": { "type": "keyword"},
"color": { "type": "keyword"},
"model": { "type": "keyword"}
}
}
}
PUT /shirts/_doc/1?refresh
{
"brand": "gucci",
"color": "red",
"model": "slim"
}
假设一个用户指定了两个过滤器:
color:red 和 brand:gucci。你只想在搜索结果中显示由Gucci制造的红色衬衫。通常你会使用一个bool 查询来实现这一点:
GET /shirts/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "color": "red" }},
{ "term": { "brand": "gucci" }}
]
}
}
}
然而,您还希望使用分面导航来显示用户可以点击的其他选项列表。也许您有一个model字段,允许用户将其搜索结果限制为红色Guccit恤或衬衫。
这可以通过一个
terms 聚合来完成:
GET /shirts/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "color": "red" }},
{ "term": { "brand": "gucci" }}
]
}
},
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
但也许您还想告诉用户在其他颜色中有多少件Gucci衬衫可供选择。如果您仅在color字段上添加一个terms聚合,您将只能得到颜色red,因为您的查询仅返回Gucci的红色衬衫。
相反,您希望在聚合期间包含所有颜色的衬衫,然后仅将colors过滤器应用于搜索结果。这就是post_filter的用途:
GET /shirts/_search
{
"query": {
"bool": {
"filter": {
"term": { "brand": "gucci" }
}
}
},
"aggs": {
"colors": {
"terms": { "field": "color" }
},
"color_red": {
"filter": {
"term": { "color": "red" }
},
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
},
"post_filter": {
"term": { "color": "red" }
}
}
|
主查询现在找到所有Gucci的衬衫,无论颜色如何。 |
|
|
The |
|
|
The |
|
|
最后, |
重新评分过滤后的搜索结果
edit重新评分可以通过使用次要(通常成本更高)的算法,仅对由query和post_filter阶段返回的前(例如100 - 500)个文档进行重新排序,从而帮助提高精度,而不是将昂贵的算法应用于索引中的所有文档。
在每个分片返回其结果以由处理整体搜索请求的节点进行排序之前,会执行一个 rescore 请求。
目前,rescore API 只有一个实现:查询重打分器,它使用查询来调整评分。未来可能会提供其他重打分器,例如,成对重打分器。
如果在使用rescore查询时提供了显式的sort(除了按降序排列的_score),将会抛出一个错误。
当向用户展示分页时,您不应在翻页时(通过传递不同的from值)更改window_size,因为这可能会改变顶部结果,导致用户在翻页时结果混乱地变化。
查询重打分器
edit查询重新评分器仅对由query和
post_filter阶段返回的Top-K结果执行第二次查询。
可以通过window_size参数控制每个分片上将检查的文档数量,该参数默认值为10。
默认情况下,原始查询和重新评分查询的分数会线性组合,以生成每个文档的最终 _score。可以通过 query_weight 和 rescore_query_weight 分别控制原始查询和重新评分查询的相对重要性。两者默认值均为 1。
例如:
POST /_search
{
"query" : {
"match" : {
"message" : {
"operator" : "or",
"query" : "the quick brown"
}
}
},
"rescore" : {
"window_size" : 50,
"query" : {
"rescore_query" : {
"match_phrase" : {
"message" : {
"query" : "the quick brown",
"slop" : 2
}
}
},
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
}
}
}
分数的组合方式可以通过score_mode来控制:
| Score Mode | Description |
|---|---|
|
添加原始分数和重新评分查询分数。默认。 |
|
将原始分数乘以重新评分查询的分数。适用于 |
|
将原始分数和重新评分查询分数取平均值。 |
|
取原始分数和重新评分查询分数的最大值。 |
|
取原始分数和重新评分查询分数的最小值。 |
多次重排序
edit也可以按顺序执行多个重新评分操作:
POST /_search
{
"query" : {
"match" : {
"message" : {
"operator" : "or",
"query" : "the quick brown"
}
}
},
"rescore" : [ {
"window_size" : 100,
"query" : {
"rescore_query" : {
"match_phrase" : {
"message" : {
"query" : "the quick brown",
"slop" : 2
}
}
},
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
}
}, {
"window_size" : 10,
"query" : {
"score_mode": "multiply",
"rescore_query" : {
"function_score" : {
"script_score": {
"script": {
"source": "Math.log10(doc.count.value + 2)"
}
}
}
}
}
} ]
}
第一个获取查询的结果,然后第二个获取第一个的结果,依此类推。第二个重新评分将“看到”第一个重新评分所做的排序,因此可以在第一个重新评分上使用较大的窗口,以便在第二个重新评分中将文档拉入较小的窗口。
高亮显示
edit高亮器使您能够从搜索结果中的一个或多个字段中获取高亮片段,以便向用户展示查询匹配的位置。当您请求高亮时,响应中会为每个搜索命中包含一个额外的highlight元素,其中包含高亮字段和高亮片段。
高亮器在提取要高亮的术语时,并不反映查询的布尔逻辑。因此,对于一些复杂的布尔查询(例如嵌套的布尔查询、使用minimum_should_match等的查询),文档的部分内容可能会被高亮,但这些部分并不对应于查询匹配。
高亮显示需要字段的实际内容。如果该字段未存储(映射未将 store 设置为 true),则会加载实际的 _source,并从中提取相关字段。
例如,要获取每个搜索命中中content字段的高亮显示,请在请求体中包含一个highlight对象,该对象指定content字段:
GET /_search
{
"query": {
"match": { "content": "kimchy" }
},
"highlight": {
"fields": {
"content": {}
}
}
}
Elasticsearch 支持三种高亮器:unified、plain 和 fvh(快速向量高亮器)。您可以为每个字段指定要使用的高亮器 type。
统一高亮器
editThe unified highlighter 使用 Lucene Unified Highlighter。这个高亮器将文本分成句子,并使用 BM25 算法对单个句子进行评分,就好像它们是语料库中的文档一样。它还支持精确的短语和多词(模糊、前缀、正则表达式)高亮显示。unified 高亮器可以将多个字段的匹配结果合并为一个结果(参见 matched_fields)。这是默认的高亮器。
普通高亮器
editThe plain highlighter 使用标准的 Lucene highlighter。它尝试在理解单词重要性和短语查询中的任何单词位置标准方面反映查询匹配逻辑。
对于在单个字段中突出显示简单查询匹配项,plain 高亮器效果最佳。为了准确反映查询逻辑,它创建了一个微小的内存中索引,并通过 Lucene 的查询执行计划器重新运行原始查询条件,以获取当前文档的低级匹配信息。此过程会针对需要高亮的每个字段和每个文档重复进行。如果您想在大量文档中高亮显示大量字段且查询复杂,我们建议在 postings 或 term_vector 字段上使用 unified 高亮器。
快速向量高亮器
editThe fvh highlighter 使用 Lucene Fast Vector highlighter。
这个 highlighter 可以在映射中将 term_vector 设置为
with_positions_offsets 的字段上使用。Fast Vector highlighter:
-
可以使用
boundary_scanner进行自定义。 -
需要将
term_vector设置为with_positions_offsets,这会增加索引的大小 -
可以将多个字段的匹配结果合并为一个结果。请参阅
matched_fields - 可以为不同位置的匹配分配不同的权重,从而允许在突出显示提升短语匹配的提升查询时,短语匹配的排序高于术语匹配
高亮器 fvh 不支持跨度查询。如果您需要支持跨度查询,请尝试其他高亮器,例如 unified 高亮器。
偏移策略
edit为了从查询的术语中创建有意义的搜索片段, 高亮器需要知道原始文本中每个单词的起始和结束字符偏移量。这些偏移量可以从以下位置获取:
-
帖子列表。如果在映射中将
index_options设置为offsets,unified高亮器使用此信息来高亮显示文档,而无需重新分析文本。它直接在帖子列表上重新运行原始查询, 并从索引中提取匹配的偏移量,将集合限制在高亮显示的文档上。如果你有大字段,这一点很重要,因为它不需要重新分析要高亮的文本。 与使用term_vectors相比,它还占用更少的磁盘空间。 -
词向量。如果在映射中通过将
term_vector设置为with_positions_offsets来提供term_vector信息,unified高亮器会自动使用term_vector来高亮显示字段。 对于大字段(>1MB)和多词查询(如prefix或wildcard)来说,它特别快, 因为它可以访问每个文档的词典。fvh高亮器总是使用词向量。 -
普通高亮。当没有其他选择时,
unified使用此模式。 它创建一个小的内存索引,并通过Lucene的查询执行计划器重新运行原始查询条件,以获取当前文档的低级匹配信息。 这对于每个需要高亮的字段和文档都会重复执行。plain高亮器总是使用普通高亮。
对于大文本的普通高亮可能需要大量的时间和内存。
为了防止这种情况,分析的文本字符的最大数量已被限制为1000000。这个默认限制可以通过索引设置index.highlight.max_analyzed_offset来为特定索引更改。
高亮设置
edit高亮设置可以在全局级别设置,并在字段级别覆盖。
- boundary_chars
-
包含每个边界字符的字符串。
默认为
.,!? \t\n。 - boundary_max_scan
-
扫描边界字符的距离。默认为
20。
- boundary_scanner
-
指定如何断开高亮片段:
字符、句子或单词。仅对统一和fvh高亮器有效。 默认为句子对于统一高亮器。默认为字符对于fvh高亮器。-
chars -
使用由
boundary_chars指定的字符作为高亮边界。boundary_max_scan设置控制扫描边界字符的距离。仅对fvh高亮器有效。 -
sentence -
在由Java的 BreakIterator 确定的下一个句子边界处分割高亮片段。您可以使用
boundary_scanner_locale指定要使用的区域设置。当与
unified高亮器一起使用时,sentence扫描器会在大于fragment_size的句子的第一个词边界处进行分割。您可以将fragment_size设置为0,以避免分割任何句子。 -
word -
在由Java的 BreakIterator 确定的下一个词边界处分割高亮片段。您可以使用
boundary_scanner_locale指定要使用的区域设置。
-
- boundary_scanner_locale
-
控制用于搜索句子和单词边界的区域设置。此参数采用语言标签的形式,例如
"en-US"、"fr-FR"、"ja-JP"。更多信息可以在语言标签文档中找到。默认值为 Locale.ROOT。 - encoder
-
指示是否应对代码片段进行HTML编码:
default(不编码)或html(对代码片段文本进行HTML转义,然后插入高亮标签) - fields
-
指定要检索高亮的字段。您可以使用通配符来指定字段。例如,您可以指定
comment_*来获取所有以comment_开头的 文本、仅匹配文本 和 关键词 字段的高亮。只有文本、match_only_text 和关键字字段在使用通配符时会被高亮显示。如果你使用自定义映射器并且仍然希望高亮显示某个字段,你必须显式指定该字段名称。
- fragmenter
-
指定文本在高亮片段中应如何断开:
simple或span。仅对plain高亮器有效。 默认为span。 - force_source
-
已弃用;此参数无效
-
simple - 将文本分解为相同大小的片段。
-
span - 将文本分解为相同大小的片段,但尽量避免在突出显示的术语之间分解文本。这在查询短语时很有帮助。默认。
-
- fragment_offset
-
控制你想要开始高亮的边距。仅在使用
fvh高亮器时有效。 - fragment_size
- 高亮片段的字符大小。默认为100。
- highlight_query
-
突出显示与搜索查询以外的查询匹配的内容。这在使用重新评分查询时特别有用,因为默认情况下高亮显示不会考虑这些内容。
Elasticsearch 不会验证
highlight_query是否以任何方式包含搜索查询,因此可以定义它,使得合法的查询结果不会被高亮显示。通常,您应该将搜索查询作为highlight_query的一部分包含在内。 - matched_fields
-
将多个字段的匹配结果合并以突出显示单个字段。
这对于以不同方式分析相同字符串的多字段最为直观。适用于
unified和fvh高亮器,但此选项的行为因高亮器而异。
对于unified高亮器:
-
matched_fields数组不应包含您想要高亮的原始字段。原始字段将自动添加到matched_fields中,并且在高亮时无法排除其匹配项。 -
matched_fields和原始字段可以使用不同的策略进行索引(使用或不使用offsets,使用或不使用term_vectors)。 -
只有与匹配项结合的原始字段会被加载,因此只有该字段会受益于将
store设置为yes。
对于 fvh 高亮器:
-
matched_fields数组可能包含也可能不包含原始字段,具体取决于您的需求。如果您希望在突出显示中包含原始字段的匹配项,请将其添加到matched_fields数组中。 -
所有
matched_fields必须将term_vector设置为with_positions_offsets -
只有匹配项组合的原始字段被加载,因此只有该字段从将
store设置为yes中受益。- no_match_size
- 如果没有任何匹配的片段需要突出显示,您希望从字段开头返回的文本量。默认为 0(不返回任何内容)。
- number_of_fragments
-
要返回的最大片段数。如果片段数设置为 0,则不返回任何片段。相反,整个字段内容将被突出显示并返回。这在需要突出显示短文本(如标题或地址)但不需要分段时非常方便。如果
number_of_fragments为 0,则忽略fragment_size。默认为 5。 - order
-
当设置为
score时,按分数对突出显示的片段进行排序。默认情况下,片段将按其在字段中出现的顺序输出(order:none)。将此选项设置为score将首先输出最相关的片段。每个高亮器应用自己的逻辑来计算相关性分数。有关不同高亮器如何找到最佳片段的更多详细信息,请参阅文档 How highlighters work internally。 - phrase_limit
-
控制文档中考虑的匹配短语数量。防止
fvh高亮器分析过多短语并消耗过多内存。当使用matched_fields时,每个匹配字段考虑phrase_limit个短语。提高限制会增加查询时间并消耗更多内存。仅由fvh高亮器支持。默认为 256。 - pre_tags
-
与
post_tags一起使用,定义用于突出显示文本的 HTML 标签。默认情况下,突出显示的文本包裹在和标签中。指定为字符串数组。 - post_tags
-
与
pre_tags一起使用,定义用于突出显示文本的 HTML 标签。默认情况下,突出显示的文本包裹在和标签中。指定为字符串数组。 - require_field_match
-
默认情况下,只有包含查询匹配的字段才会被突出显示。将
require_field_match设置为false以突出显示所有字段。默认为true。
- max_analyzed_offset
-
默认情况下,高亮请求分析的最大字符数受限于
index.highlight.max_analyzed_offset设置中定义的值, 当字符数超过此限制时会返回错误。如果 此设置被设置为非负值,高亮处理将在定义的最大限制处停止,其余文本将不会被处理,因此不会被高亮显示且不会返回错误。max_analyzed_offset查询设置 不会覆盖index.highlight.max_analyzed_offset, 当其设置值低于查询设置时,后者优先。 - tags_schema
-
设置为
styled以使用内置的标签模式。styled模式定义了以下pre_tags并将post_tags定义为。, , , , , , , , ,
高亮示例
edit覆盖全局设置
edit您可以全局指定高亮设置,并选择性地为个别字段覆盖它们。
GET /_search
{
"query" : {
"match": { "user.id": "kimchy" }
},
"highlight" : {
"number_of_fragments" : 3,
"fragment_size" : 150,
"fields" : {
"body" : { "pre_tags" : ["<em>"], "post_tags" : ["</em>"] },
"blog.title" : { "number_of_fragments" : 0 },
"blog.author" : { "number_of_fragments" : 0 },
"blog.comment" : { "number_of_fragments" : 5, "order" : "score" }
}
}
}
指定高亮查询
edit您可以指定一个highlight_query来考虑额外的信息进行高亮显示。例如,以下查询在highlight_query中同时包含了搜索查询和重新评分查询。如果没有highlight_query,高亮显示将仅考虑搜索查询。
GET /_search
{
"query": {
"match": {
"comment": {
"query": "foo bar"
}
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": {
"comment": {
"query": "foo bar",
"slop": 1
}
}
},
"rescore_query_weight": 10
}
},
"_source": false,
"highlight": {
"order": "score",
"fields": {
"comment": {
"fragment_size": 150,
"number_of_fragments": 3,
"highlight_query": {
"bool": {
"must": {
"match": {
"comment": {
"query": "foo bar"
}
}
},
"should": {
"match_phrase": {
"comment": {
"query": "foo bar",
"slop": 1,
"boost": 10.0
}
}
},
"minimum_should_match": 0
}
}
}
}
}
}
设置高亮类型
edit字段 type 允许强制使用特定的高亮类型。
允许的值有:unified、plain 和 fvh。
以下是一个强制使用普通高亮器的示例:
GET /_search
{
"query": {
"match": { "user.id": "kimchy" }
},
"highlight": {
"fields": {
"comment": { "type": "plain" }
}
}
}
配置高亮标签
edit默认情况下,高亮显示会将高亮文本包裹在和
中。这可以通过设置pre_tags和post_tags来控制,
例如:
GET /_search
{
"query" : {
"match": { "user.id": "kimchy" }
},
"highlight" : {
"pre_tags" : ["<tag1>"],
"post_tags" : ["</tag1>"],
"fields" : {
"body" : {}
}
}
}
当使用快速向量高亮器时,您可以指定额外的标签,并且“重要性”是有序的。
GET /_search
{
"query" : {
"match": { "user.id": "kimchy" }
},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"body" : {}
}
}
}
您也可以使用内置的 styled 标签模式:
GET /_search
{
"query" : {
"match": { "user.id": "kimchy" }
},
"highlight" : {
"tags_schema" : "styled",
"fields" : {
"comment" : {}
}
}
}
在所有字段中高亮显示
edit默认情况下,只有包含查询匹配的字段会被高亮显示。将require_field_match设置为false以高亮显示所有字段。
GET /_search
{
"query" : {
"match": { "user.id": "kimchy" }
},
"highlight" : {
"require_field_match": false,
"fields": {
"body" : { "pre_tags" : ["<em>"], "post_tags" : ["</em>"] }
}
}
}
在多个字段上组合匹配
edit由unified和fvh高亮器支持。
统一和快速向量高亮器可以将多个字段的匹配结果合并,以高亮显示单个字段。这对于以不同方式分析相同字符串的多字段最为直观。
在以下示例中,comment 由 standard 分析器分析,而 comment.english 由 english 分析器分析。
PUT index1
{
"mappings": {
"properties": {
"comment": {
"type": "text",
"analyzer": "standard",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
PUT index1/_bulk?refresh=true
{"index": {"_id": "doc1" }}
{"comment": "run with scissors"}
{ "index" : {"_id": "doc2"} }
{"comment": "running with scissors"}
GET index1/_search
{
"query": {
"query_string": {
"query": "running with scissors",
"fields": ["comment", "comment.english"]
}
},
"highlight": {
"order": "score",
"fields": {
"comment": {}
}
}
}
上述请求同时匹配了“run with scissors”和“running with scissors”,并且会高亮显示“running”和“scissors”,但不会高亮显示“run”。如果这两个短语都出现在一个大文档中,那么“running with scissors”会在片段列表中排在“run with scissors”之前,因为该片段中有更多的匹配项。
{
...
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score": 1.0577903,
"hits" : [
{
"_index" : "index1",
"_id" : "doc2",
"_score" : 1.0577903,
"_source" : {
"comment" : "running with scissors"
},
"highlight" : {
"comment" : [
"<em>running</em> <em>with</em> <em>scissors</em>"
]
}
},
{
"_index" : "index1",
"_id" : "doc1",
"_score" : 0.36464313,
"_source" : {
"comment" : "run with scissors"
},
"highlight" : {
"comment" : [
"run <em>with</em> <em>scissors</em>"
]
}
}
]
}
}
下面的请求将“run”、“running”和“scissors”高亮显示,因为matched_fields参数指示我们需要将来自comment.english字段的匹配与来自原始comment字段的匹配结合起来进行高亮显示。
GET index1/_search
{
"query": {
"query_string": {
"query": "running with scissors",
"fields": ["comment", "comment.english"]
}
},
"highlight": {
"order": "score",
"fields": {
"comment": {
"matched_fields": ["comment.english"]
}
}
}
}
{
...
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score": 1.0577903,
"hits" : [
{
"_index" : "index1",
"_id" : "doc2",
"_score" : 1.0577903,
"_source" : {
"comment" : "running with scissors"
},
"highlight" : {
"comment" : [
"<em>running</em> <em>with</em> <em>scissors</em>"
]
}
},
{
"_index" : "index1",
"_id" : "doc1",
"_score" : 0.36464313,
"_source" : {
"comment" : "run with scissors"
},
"highlight" : {
"comment" : [
"<em>run</em> <em>with</em> <em>scissors</em>"
]
}
}
]
}
}
在以下示例中,comment 由 standard 分析器分析,而 comment.english 由 english 分析器分析。
PUT index2
{
"mappings": {
"properties": {
"comment": {
"type": "text",
"analyzer": "standard",
"term_vector": "with_positions_offsets",
"fields": {
"english": {
"type": "text",
"analyzer": "english",
"term_vector": "with_positions_offsets"
}
}
}
}
}
}
PUT index2/_bulk?refresh=true
{"index": {"_id": "doc1" }}
{"comment": "run with scissors"}
{ "index" : {"_id": "doc2"} }
{"comment": "running with scissors"}
GET index2/_search
{
"query": {
"query_string": {
"query": "running with scissors",
"fields": ["comment", "comment.english"]
}
},
"highlight": {
"order": "score",
"fields": {
"comment": {
"type" : "fvh"
}
}
}
}
上述请求同时匹配了“run with scissors”和“running with scissors”,并且会高亮显示“running”和“scissors”,但不会高亮显示“run”。如果这两个短语都出现在一个大文档中,那么“running with scissors”会在片段列表中排在“run with scissors”之前,因为该片段中有更多的匹配项。
{
...
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score": 1.0577903,
"hits" : [
{
"_index" : "index2",
"_id" : "doc2",
"_score" : 1.0577903,
"_source" : {
"comment" : "running with scissors"
},
"highlight" : {
"comment" : [
"<em>running</em> <em>with</em> <em>scissors</em>"
]
}
},
{
"_index" : "index2",
"_id" : "doc1",
"_score" : 0.36464313,
"_source" : {
"comment" : "run with scissors"
},
"highlight" : {
"comment" : [
"run <em>with</em> <em>scissors</em>"
]
}
}
]
}
}
下面的请求将“run”、“running”和“scissors”高亮显示,因为matched_fields参数指示我们需要结合来自comment和comment.english字段的匹配进行高亮显示。
GET index2/_search
{
"query": {
"query_string": {
"query": "running with scissors",
"fields": ["comment", "comment.english"]
}
},
"highlight": {
"order": "score",
"fields": {
"comment": {
"type" : "fvh",
"matched_fields": ["comment", "comment.english"]
}
}
}
}
{
...
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score": 1.0577903,
"hits" : [
{
"_index" : "index2",
"_id" : "doc2",
"_score" : 1.0577903,
"_source" : {
"comment" : "running with scissors"
},
"highlight" : {
"comment" : [
"<em>running</em> <em>with</em> <em>scissors</em>"
]
}
},
{
"_index" : "index2",
"_id" : "doc1",
"_score" : 0.36464313,
"_source" : {
"comment" : "run with scissors"
},
"highlight" : {
"comment" : [
"<em>run</em> <em>with</em> <em>scissors</em>"
]
}
}
]
}
}
下面的请求不会高亮显示“run”或“scissor”,但表明不列出匹配字段中组合匹配的字段(comment.english)也是可以的。
GET index2/_search
{
"query": {
"query_string": {
"query": "running with scissors",
"fields": ["comment", "comment.english"]
}
},
"highlight": {
"order": "score",
"fields": {
"comment.english": {
"type" : "fvh",
"matched_fields": ["comment"]
}
}
}
}
{
...
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score": 1.0577903,
"hits" : [
{
"_index" : "index2",
"_id" : "doc2",
"_score" : 1.0577903,
"_source" : {
"comment" : "running with scissors"
},
"highlight" : {
"comment.english" : [
"<em>running</em> <em>with</em> <em>scissors</em>"
]
}
},
{
"_index" : "index2",
"_id" : "doc1",
"_score" : 0.36464313,
"_source" : {
"comment" : "run with scissors"
},
"highlight" : {
"comment.english" : [
"run <em>with</em> <em>scissors</em>"
]
}
}
]
}
}
设置matched_fields为非空数组会涉及少量开销,因此总是优先选择
"highlight": {
"fields": {
"comment": {}
}
}
到
"highlight": {
"fields": {
"comment": {
"matched_fields": ["comment"],
"type" : "fvh"
}
}
}
从技术上讲,也可以将不与匹配结果组合的字段所共享的相同基础字符串添加到 matched_fields 中。结果可能没有太大意义,如果其中一个匹配项超出了文本的末尾,则整个查询将失败。
显式排序高亮字段
editElasticsearch 按照字段发送的顺序高亮显示字段,但根据 JSON 规范,对象是无序的。如果您需要明确指定字段高亮的顺序,请将 fields 指定为数组:
GET /_search
{
"highlight": {
"fields": [
{ "title": {} },
{ "text": {} }
]
}
}
Elasticsearch内置的高亮器都不关心字段高亮的顺序,但插件可能会关心。
控制高亮片段
edit每个高亮显示的字段都可以控制高亮片段的字符大小(默认为100),以及返回的最大片段数量(默认为5)。
例如:
GET /_search
{
"query" : {
"match": { "user.id": "kimchy" }
},
"highlight" : {
"fields" : {
"comment" : {"fragment_size" : 150, "number_of_fragments" : 3}
}
}
}
除此之外,还可以指定需要按分数排序的高亮片段:
GET /_search
{
"query" : {
"match": { "user.id": "kimchy" }
},
"highlight" : {
"order" : "score",
"fields" : {
"comment" : {"fragment_size" : 150, "number_of_fragments" : 3}
}
}
}
如果将 number_of_fragments 值设置为 0,则不会生成片段,而是返回字段的全部内容,并且当然会高亮显示。如果需要高亮显示短文本(如文档标题或地址)但不需要分段,这会非常方便。请注意,在这种情况下,fragment_size 将被忽略。
GET /_search
{
"query" : {
"match": { "user.id": "kimchy" }
},
"highlight" : {
"fields" : {
"body" : {},
"blog.title" : {"number_of_fragments" : 0}
}
}
}
使用 fvh 时,可以使用 fragment_offset 参数来控制从何处开始高亮的边距。
在没有匹配的片段需要高亮显示的情况下,默认是不返回任何内容。相反,我们可以通过设置no_match_size(默认值为0)来返回字段开头的一段文本,该值表示你希望返回的文本长度。实际长度可能会比指定的短或长,因为它会尝试在单词边界处断开。
GET /_search
{
"query": {
"match": { "user.id": "kimchy" }
},
"highlight": {
"fields": {
"comment": {
"fragment_size": 150,
"number_of_fragments": 3,
"no_match_size": 150
}
}
}
}
使用 postings list 进行高亮显示
edit这是一个在索引映射中设置comment字段的示例,以允许使用postings进行高亮显示:
PUT /example
{
"mappings": {
"properties": {
"comment" : {
"type": "text",
"index_options" : "offsets"
}
}
}
}
这是一个将 comment 字段设置为允许使用 term_vectors 进行高亮的示例(这将导致索引变大):
PUT /example
{
"mappings": {
"properties": {
"comment" : {
"type": "text",
"term_vector" : "with_positions_offsets"
}
}
}
}
为普通高亮器指定一个片段生成器
edit当使用 plain 高亮器时,你可以选择 simple 和 span 片段器:
GET my-index-000001/_search
{
"query": {
"match_phrase": { "message": "number 1" }
},
"highlight": {
"fields": {
"message": {
"type": "plain",
"fragment_size": 15,
"number_of_fragments": 3,
"fragmenter": "simple"
}
}
}
}
响应:
{
...
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.6011951,
"hits": [
{
"_index": "my-index-000001",
"_id": "1",
"_score": 1.6011951,
"_source": {
"message": "some message with the number 1",
"context": "bar"
},
"highlight": {
"message": [
" with the <em>number</em>",
" <em>1</em>"
]
}
}
]
}
}
GET my-index-000001/_search
{
"query": {
"match_phrase": { "message": "number 1" }
},
"highlight": {
"fields": {
"message": {
"type": "plain",
"fragment_size": 15,
"number_of_fragments": 3,
"fragmenter": "span"
}
}
}
}
响应:
{
...
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.6011951,
"hits": [
{
"_index": "my-index-000001",
"_id": "1",
"_score": 1.6011951,
"_source": {
"message": "some message with the number 1",
"context": "bar"
},
"highlight": {
"message": [
" with the <em>number</em> <em>1</em>"
]
}
}
]
}
}
如果number_of_fragments选项设置为0,
则使用NullFragmenter,它不会对文本进行任何分段。
这对于突出显示文档或字段的全部内容非常有用。
高亮器如何内部工作
edit给定一个查询和一个文本(文档字段的内容),高亮器的目标是找到最适合查询的文本片段,并在找到的片段中高亮显示查询词。为此,高亮器需要解决几个问题:
- 如何将文本分解成片段?
- 如何从所有片段中找到最佳片段?
- 如何在片段中突出显示查询词?
如何将文本分割成片段?
edit相关设置:fragment_size、fragmenter、type 的高亮器、
boundary_chars、boundary_max_scan、boundary_scanner、boundary_scanner_locale。
普通高亮器开始时使用给定的分析器分析文本,并从中创建一个标记流。普通高亮器使用一个非常简单的算法将标记流分解为片段。它遍历标记流中的术语,每当当前术语的end_offset超过fragment_size乘以已创建片段的数量时,就会创建一个新的片段。使用span片段器进行一些额外的计算,以避免在突出显示的术语之间打断文本。但总体而言,由于仅通过fragment_size进行分割,某些片段可能会非常奇怪,例如以标点符号开头。
统一或FVH高亮器通过利用Java的BreakIterator更好地将文本分解为片段。这确保了只要fragment_size允许,片段就是一个有效的句子。
如何找到最佳片段?
edit相关设置:number_of_fragments。
为了找到最佳、最相关的内容片段,高亮器需要根据给定的查询对每个片段进行评分。目标是仅对那些参与生成文档命中的术语进行评分。对于一些复杂的查询,这仍然是正在进行的工作。
普通的高亮器从当前的标记流创建一个内存中的索引,并重新通过Lucene的查询执行计划器运行原始查询条件,以获取当前文本的低级匹配信息。对于更复杂的查询,原始查询可以转换为跨度查询,因为跨度查询可以更准确地处理短语。然后,使用获得的低级匹配信息来为每个单独的片段打分。普通的打分方法非常简单。每个片段的得分由在该片段中找到的唯一查询词的数量决定。单个词的得分等于其提升值,默认情况下为1。因此,默认情况下,包含一个唯一查询词的片段将得到1分;包含两个唯一查询词的片段将得到2分,依此类推。然后根据得分对片段进行排序,得分最高的片段将首先输出。
FVH不需要分析文本并构建内存中的索引,因为它使用预先索引的文档术语向量,并在其中找到与查询对应的术语。FVH根据在该片段中找到的查询术语的数量对每个片段进行评分。与普通高亮器类似,单个术语的分数等于其提升值。与普通高亮器不同,所有查询术语都被计数,不仅仅是唯一术语。
统一高亮器可以使用预先索引的词向量或预先索引的词偏移量,如果它们可用的话。否则,类似于普通高亮器,它必须从文本创建一个内存中的索引。统一高亮器使用BM25评分模型来对片段进行评分。
如何在片段中高亮显示查询词?
edit相关设置: pre-tags, post-tags。
目标是仅突出显示那些参与生成文档中命中的术语。 对于一些复杂的布尔查询,这仍然是进行中的工作,因为高亮器不反映查询的布尔逻辑,只提取叶(术语、短语、前缀等)查询。
给定标记流和原始文本的普通高亮器,重新组合原始文本,仅高亮来自标记流中的术语,这些术语包含在前一步骤中的低级匹配信息结构中。
FVH 和统一高亮器使用中间数据结构以某种原始形式表示片段,然后使用实际文本填充它们。
高亮器使用 pre-tags、post-tags 来编码高亮术语。
统一高亮器工作的一个示例
edit让我们更详细地了解统一高亮器的工作原理。
首先,我们创建一个包含文本字段 content 的索引,该字段将使用 english 分析器进行索引,并且将不带偏移量或词向量进行索引。
PUT test_index
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "english"
}
}
}
}
我们将以下文档放入索引中:
PUT test_index/_doc/doc1
{
"content" : "For you I'm only a fox like a hundred thousand other foxes. But if you tame me, we'll need each other. You'll be the only boy in the world for me. I'll be the only fox in the world for you."
}
并且我们使用高亮请求运行了以下查询:
GET test_index/_search
{
"query": {
"match_phrase" : {"content" : "only fox"}
},
"highlight": {
"type" : "unified",
"number_of_fragments" : 3,
"fields": {
"content": {}
}
}
}
在找到 doc1 作为此查询的命中后,此命中将被传递给统一高亮器以高亮显示文档的 content 字段。
由于 content 字段既未使用偏移量也未使用词向量进行索引,
因此将分析其原始字段值,并从与查询匹配的词项构建内存中的索引:
{"token":"onli","start_offset":12,"end_offset":16,"position":3},
{"token":"fox","start_offset":19,"end_offset":22,"position":5},
{"token":"fox","start_offset":53,"end_offset":58,"position":11},
{"token":"onli","start_offset":117,"end_offset":121,"position":24},
{"token":"onli","start_offset":159,"end_offset":163,"position":34},
{"token":"fox","start_offset":164,"end_offset":167,"position":35}
我们的复杂短语查询将被转换为跨度查询:
spanNear([text:onli, text:fox], 0, true),这意味着我们在寻找
术语“onli”和“fox”在彼此距离为0的位置,并且按照给定的顺序。跨度查询将在之前创建的内存索引上运行,
以找到以下匹配项:
{"term":"onli", "start_offset":159, "end_offset":163},
{"term":"fox", "start_offset":164, "end_offset":167}
在我们的示例中,我们得到了一个匹配项,但可能会有多个匹配项。
给定这些匹配项,统一高亮器将字段的文本分解为所谓的“段落”。每个段落必须包含至少一个匹配项。
统一高亮器使用Java的BreakIterator确保每个段落代表一个完整的句子,只要它不超过fragment_size。
在我们的示例中,我们得到了一个具有以下属性的段落(这里仅显示属性的一个子集):
Passage:
startOffset: 147
endOffset: 189
score: 3.7158387
matchStarts: [159, 164]
matchEnds: [163, 167]
numMatches: 2
注意一个段落是如何有一个分数的,这个分数是使用BM25评分公式计算的,该公式适用于段落。分数允许我们在可用段落多于用户请求的number_of_fragments时选择得分最高的段落。如果用户请求,分数还允许我们按order: "score"对段落进行排序。
作为最后一步,统一的高亮器将从字段的文本中提取与每个段落相对应的字符串:
"I'll be the only fox in the world for you."
并将使用标签 和 格式化此字符串中的所有匹配项,使用段落的 matchStarts 和 matchEnds 信息:
I'll be the <em>only</em> <em>fox</em> in the world for you.
这种格式化的字符串是高亮器返回给用户的最终结果。
长时间运行的搜索
editElasticsearch 通常允许您快速搜索大量数据。在某些情况下,搜索会在许多分片上执行,可能针对大型数据集或多个 远程集群,这些情况下结果不会在毫秒内返回。当您需要执行长时间运行的搜索时,同步等待其结果返回并不理想。相反,异步搜索允许您提交一个异步执行的搜索请求,监控请求的进度,并在稍后阶段检索结果。您还可以在搜索完成之前检索部分结果。
您可以使用提交异步搜索 API 提交异步搜索请求。获取异步搜索 API 允许您监控异步搜索请求的进度并检索其结果。可以通过删除异步搜索 API 删除正在进行的异步搜索。
近实时搜索
edit当一个文档存储在Elasticsearch中时,它会被索引并在近实时内完全可搜索——在1秒内。什么是近实时搜索?
Lucene,Elasticsearch 所基于的 Java 库,引入了按段搜索的概念。一个 段 类似于倒排索引,但在 Lucene 中,索引 这个词意味着“一个段集合加上一个提交点”。在提交之后,一个新的段被添加到提交点,并且缓冲区被清空。
位于 Elasticsearch 和磁盘之间的是文件系统缓存。内存中的索引缓冲区中的文档(图 6)被写入到一个新的段(图 7)。新的段首先被写入文件系统缓存(这是廉价的),之后才会被刷新到磁盘(这是昂贵的)。然而,一旦文件在缓存中,它就可以像其他文件一样被打开和读取。
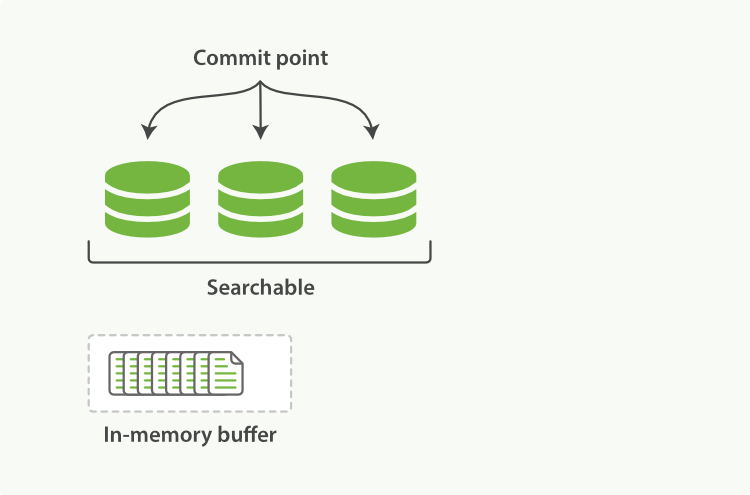
Lucene 允许写入和打开新的段,使得它们包含的文档对搜索可见,而无需执行完整的提交。这是一个比提交到磁盘轻量得多的过程,并且可以频繁执行而不会降低性能。
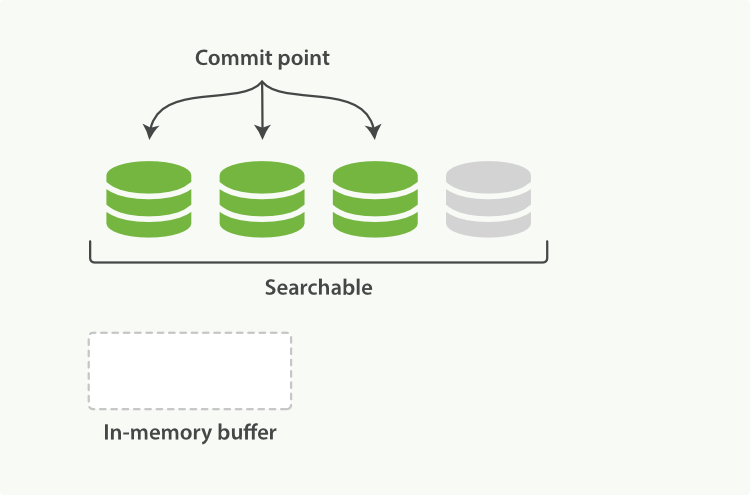
在Elasticsearch中,这个写入和打开新段的过程称为刷新。刷新使得自上次刷新以来对索引执行的所有操作都可用于搜索。您可以通过以下方式控制刷新:
- 等待刷新间隔
- 设置?refresh选项
-
使用Refresh API显式完成刷新(
POST _refresh)
默认情况下,Elasticsearch 每隔一秒定期刷新索引,但仅在最近 30 秒内收到一次或多次搜索请求的索引上进行。这就是为什么我们说 Elasticsearch 具有近实时搜索:文档的更改不会立即对搜索可见,但会在此时间范围内变得可见。
检索内部命中
editThe parent-join 和 nested 功能允许返回在不同范围内有匹配的文档。在父子关系的情况下,基于子文档中的匹配返回父文档,或基于父文档中的匹配返回子文档。在嵌套情况下,基于嵌套内部对象中的匹配返回文档。
在这两种情况下,导致文档被返回的不同作用域中的实际匹配项都是隐藏的。在许多情况下,了解哪些内部嵌套对象(在嵌套情况下)或子文档/父文档(在父子情况下)导致了某些信息的返回是非常有用的。内部匹配功能可以用于此目的。此功能在搜索响应中为每个搜索命中返回额外的嵌套命中,这些嵌套命中导致在不同作用域中的搜索命中匹配。
内部命中可以通过在 nested、has_child 或 has_parent 查询和过滤器上定义一个 inner_hits 定义来使用。结构如下所示:
"<query>" : {
"inner_hits" : {
<inner_hits_options>
}
}
如果在一个支持它的查询上定义了inner_hits,那么每个搜索命中将包含一个inner_hits JSON对象,其结构如下:
"hits": [
{
"_index": ...,
"_type": ...,
"_id": ...,
"inner_hits": {
"<inner_hits_name>": {
"hits": {
"total": ...,
"hits": [
{
"_id": ...,
...
},
...
]
}
}
},
...
},
...
]
选项
edit内部命中支持以下选项:
|
|
从返回的常规搜索命中中,每个 |
|
|
每次 |
|
|
内部点击应如何按 |
|
|
在响应中用于特定内部命中定义的名称。当在单个搜索请求中定义了多个内部命中时,这很有用。默认值取决于在哪个查询中定义了内部命中。对于 |
内部命中还支持以下每个文档的功能:
嵌套内部命中
edit嵌套的 inner_hits 可以用于将嵌套的内部对象作为内部命中包含在搜索命中中。
PUT test
{
"mappings": {
"properties": {
"comments": {
"type": "nested"
}
}
}
}
PUT test/_doc/1?refresh
{
"title": "Test title",
"comments": [
{
"author": "kimchy",
"number": 1
},
{
"author": "nik9000",
"number": 2
}
]
}
POST test/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"match": {"comments.number" : 2}
},
"inner_hits": {}
}
}
}
从上述搜索请求生成的响应片段示例:
{
...,
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_id": "1",
"_score": 1.0,
"_source": ...,
"inner_hits": {
"comments": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_id": "1",
"_nested": {
"field": "comments",
"offset": 1
},
"_score": 1.0,
"_source": {
"author": "nik9000",
"number": 2
}
}
]
}
}
}
}
]
}
}
在上面的示例中,_nested 元数据至关重要,因为它定义了此内部命中来自哪个内部嵌套对象。field 定义了嵌套命中来自的对象数组字段,而 offset 相对于其在 _source 中的位置。由于排序和评分,inner_hits 中命中对象的实际位置通常与定义嵌套内部对象的位置不同。
默认情况下,_source 也会在 inner_hits 的命中对象中返回,但可以更改此设置。可以通过 _source 过滤功能返回部分源数据或禁用它。如果在嵌套级别定义了存储字段,也可以通过 fields 功能返回这些字段。
一个重要的默认设置是,在 inner_hits 中返回的 _source 是相对于 _nested 元数据的。
所以在上面的例子中,每个嵌套命中只返回评论部分,而不是包含评论的顶级文档的整个源。
嵌套内部命中和_source
edit嵌套文档没有 _source 字段,因为整个文档的源代码存储在根文档的 _source 字段下。要仅包含嵌套文档的源代码,将解析根文档的源代码,并仅将嵌套文档的相关部分作为源代码包含在内嵌命中。对每个匹配的嵌套文档执行此操作会对执行整个搜索请求所需的时间产生影响,尤其是在 size 和内嵌命中的 size 设置高于默认值时。为了避免嵌套内嵌命中相对昂贵的源代码提取,可以禁用包含源代码,仅依赖文档值字段。像这样:
PUT test
{
"mappings": {
"properties": {
"comments": {
"type": "nested"
}
}
}
}
PUT test/_doc/1?refresh
{
"title": "Test title",
"comments": [
{
"author": "kimchy",
"text": "comment text"
},
{
"author": "nik9000",
"text": "words words words"
}
]
}
POST test/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"match": {"comments.text" : "words"}
},
"inner_hits": {
"_source" : false,
"docvalue_fields" : [
"comments.text.keyword"
]
}
}
}
}
嵌套对象字段和内部命中的层次级别。
edit如果一个映射具有多层次的嵌套对象字段,每个层次可以通过点符号路径来访问。
例如,如果存在一个名为 comments 的嵌套字段,其中包含一个名为 votes 的嵌套字段,并且 votes 应该直接与根 hits 一起返回,那么可以定义以下路径:
PUT test
{
"mappings": {
"properties": {
"comments": {
"type": "nested",
"properties": {
"votes": {
"type": "nested"
}
}
}
}
}
}
PUT test/_doc/1?refresh
{
"title": "Test title",
"comments": [
{
"author": "kimchy",
"text": "comment text",
"votes": []
},
{
"author": "nik9000",
"text": "words words words",
"votes": [
{"value": 1 , "voter": "kimchy"},
{"value": -1, "voter": "other"}
]
}
]
}
POST test/_search
{
"query": {
"nested": {
"path": "comments.votes",
"query": {
"match": {
"comments.votes.voter": "kimchy"
}
},
"inner_hits" : {}
}
}
}
看起来像这样:
{
...,
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "test",
"_id": "1",
"_score": 0.6931471,
"_source": ...,
"inner_hits": {
"comments.votes": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "test",
"_id": "1",
"_nested": {
"field": "comments",
"offset": 1,
"_nested": {
"field": "votes",
"offset": 0
}
},
"_score": 0.6931471,
"_source": {
"value": 1,
"voter": "kimchy"
}
}
]
}
}
}
}
]
}
}
这种间接引用仅支持嵌套的内部命中。
父子内部命中
edit父/子 inner_hits 可以用于包含父或子:
PUT test
{
"mappings": {
"properties": {
"my_join_field": {
"type": "join",
"relations": {
"my_parent": "my_child"
}
}
}
}
}
PUT test/_doc/1?refresh
{
"number": 1,
"my_join_field": "my_parent"
}
PUT test/_doc/2?routing=1&refresh
{
"number": 1,
"my_join_field": {
"name": "my_child",
"parent": "1"
}
}
POST test/_search
{
"query": {
"has_child": {
"type": "my_child",
"query": {
"match": {
"number": 1
}
},
"inner_hits": {}
}
}
}
从上述搜索请求生成的响应片段示例:
{
...,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_id": "1",
"_score": 1.0,
"_source": {
"number": 1,
"my_join_field": "my_parent"
},
"inner_hits": {
"my_child": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_id": "2",
"_score": 1.0,
"_routing": "1",
"_source": {
"number": 1,
"my_join_field": {
"name": "my_child",
"parent": "1"
}
}
}
]
}
}
}
}
]
}
}
搜索分片路由
edit为了防止硬件故障并增加搜索容量,Elasticsearch 可以在多个节点上的多个分片中存储索引数据的副本。当执行搜索请求时,Elasticsearch 会选择包含索引数据副本的节点,并将搜索请求转发到该节点的分片。这个过程被称为搜索分片路由或路由。
自适应副本选择
edit默认情况下,Elasticsearch 使用 自适应副本选择 来路由搜索请求。 这种方法使用 分片 分配感知 和以下标准来选择一个符合条件的节点:
- 协调节点与符合条件的节点之间的先前请求的响应时间
- 符合条件的节点运行先前搜索所花费的时间
-
符合条件的节点的
search线程池的队列大小
自适应副本选择旨在减少搜索延迟。然而,您可以通过使用集群设置 API将cluster.routing.use_adaptive_replica_selection设置为false来禁用自适应副本选择。如果禁用,Elasticsearch 将使用轮询方法路由搜索请求,这可能会导致搜索速度变慢。
设置偏好
edit默认情况下,自适应副本选择会从所有符合条件的节点和分片中进行选择。然而,您可能只希望从本地节点获取数据,或者根据节点的硬件将搜索路由到特定节点。或者,您可能希望将重复的搜索发送到同一个分片,以利用缓存的优势。
要限制符合搜索请求的节点和分片集,请使用搜索 API 的 preference 查询参数。
例如,以下请求使用_local的preference搜索my-index-000001。这将搜索限制在本地节点上的分片。如果本地节点不包含索引数据的任何分片副本,请求将使用自适应副本选择作为回退,选择另一个符合条件的节点。
GET /my-index-000001/_search?preference=_local
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
您还可以使用preference参数根据提供的字符串将搜索路由到特定的分片。如果集群状态和选定的分片没有变化,使用相同preference字符串的搜索将按照相同的顺序路由到相同的分片。
我们建议使用一个唯一的preference字符串,例如用户名或网络会话ID。此字符串不能以_开头。
您可以使用此选项为频繁使用且资源密集型的搜索提供缓存结果。如果分片的数据没有变化,使用相同的preference字符串重复搜索将从相同的分片请求缓存中检索结果。对于时间序列用例,例如日志记录,旧索引中的数据很少更新,可以直接从该缓存中提供。
以下请求使用my-custom-shard-string的preference字符串搜索my-index-000001。
GET /my-index-000001/_search?preference=my-custom-shard-string
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
如果集群状态或选定的分片发生变化,相同的 preference 字符串可能不会按照相同的顺序将搜索路由到相同的分片。这可能由于多种原因发生,包括分片重新定位和分片故障。节点也可能拒绝搜索请求,Elasticsearch 会将请求重新路由到另一个节点。
使用路由值
edit当您索引一个文档时,您可以指定一个可选的 路由值,该值将文档路由到特定的分片。
例如,以下索引请求使用my-routing-value路由文档。
POST /my-index-000001/_doc?routing=my-routing-value
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
您可以在搜索 API 的 routing 查询参数中使用相同的路由值。这确保了搜索在用于索引文档的同一分片上运行。
GET /my-index-000001/_search?routing=my-routing-value
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
您还可以提供多个以逗号分隔的路由值:
GET /my-index-000001/_search?routing=my-routing-value,my-routing-value-2
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
搜索并发性和并行性
edit默认情况下,Elasticsearch 不会根据搜索请求所命中的分片数量来拒绝请求。然而,命中大量分片可能会显著增加 CPU 和内存的使用。
有关防止索引具有大量分片的提示,请参阅 调整分片大小。
您可以使用 max_concurrent_shard_requests 查询参数来控制每个节点上搜索请求可以命中的最大并发分片数。这可以防止单个请求使集群过载。该参数默认最大值为 5。
GET /my-index-000001/_search?max_concurrent_shard_requests=3
{
"query": {
"match": {
"user.id": "kimchy"
}
}
}
您还可以使用 action.search.shard_count.limit 集群设置来设置搜索分片限制,并拒绝命中过多分片的请求。您可以使用 集群设置 API 来配置 action.search.shard_count.limit。
使用查询规则进行搜索
edit查询规则允许根据指定的标准元数据自定义搜索结果。 这使得可以更好地控制结果,例如确保符合定义标准的推广文档在结果列表的顶部返回。 元数据在查询规则中定义,并与查询标准进行匹配。 查询规则使用元数据来匹配查询。 元数据作为规则查询的一部分提供,作为一个对象,可以是任何有助于区分查询的内容,例如:
- 用户输入的查询字符串
- 关于用户的个性化元数据(例如国家、语言等)
- 特定主题
- 引用站点
- 等等。
查询规则定义了一个元数据键,该键将用于匹配在规则查询中提供的元数据与规则中指定的标准。
当查询规则根据其定义的标准匹配规则查询元数据时,查询规则操作将应用于底层organic查询。
例如,可以定义一个查询规则,以匹配用户输入的查询字符串 pugs 和国家 us,并在规则查询满足这两个条件时推广可领养的收容所狗狗。
规则定义
edit在定义规则时,请考虑以下几点:
规则类型
edit我们想要应用的规则类型。 我们支持以下规则类型:
-
pinned会将查询重写为 固定查询,将符合查询规则的指定结果固定在返回结果集的顶部。 -
exclude将从返回的结果集中排除指定的结果。
规则标准
edit此规则将匹配的条件。
条件定义为 类型、元数据 和 值。
允许的条件类型包括:
| Type | Match Requirements |
|---|---|
|
规则元数据与指定值完全匹配。 |
|
规则元数据与允许的莱文斯坦编辑距离内的指定值匹配。 |
|
规则元数据以指定值开始。 |
|
规则元数据以指定值结尾。 |
|
规则元数据包含指定的值。 |
|
规则元数据小于指定值。 |
|
规则元数据小于或等于指定值。 |
|
规则元数据大于指定值。 |
|
规则元数据大于或等于指定值。 |
|
始终匹配所有规则查询。 |
规则操作
edit规则匹配查询时要采取的操作:
-
ids将选择指定的_id。 -
docs将选择指定索引中的指定文档。
在搜索单个索引时使用ids,在搜索多个索引时使用docs。
ids 和 docs 不能在同一个查询中组合使用。
添加查询规则
edit您可以使用创建或更新查询规则集调用来添加查询规则。 这将添加一个包含一个或多个查询规则的规则集,这些规则将应用于符合其指定条件的查询。
以下命令将创建一个名为 my-ruleset 的查询规则集,其中包含两个查询规则:
PUT /_query_rules/my-ruleset
{
"rules": [
{
"rule_id": "rule1",
"type": "pinned",
"criteria": [
{
"type": "fuzzy",
"metadata": "query_string",
"values": [ "puggles", "pugs" ]
},
{
"type": "exact",
"metadata": "user_country",
"values": [ "us" ]
}
],
"actions": {
"ids": [
"id1",
"id2"
]
}
},
{
"rule_id": "rule2",
"type": "exclude",
"criteria": [
{
"type": "contains",
"metadata": "query_string",
"values": [ "beagles" ]
}
],
"actions": {
"docs": [
{
"_index": "my-index-000001",
"_id": "id3"
},
{
"_index": "my-index-000002",
"_id": "id4"
}
]
}
}
]
}
API响应返回的结果为created或updated,取决于这是新建的还是编辑的规则集。
每个规则集的规则数量限制为100条。
可以通过设置xpack.applications.rules.max_rules_per_ruleset集群参数将其增加到最多1000条。
{
"result": "created"
}
您可以使用获取查询规则集调用来检索您刚刚创建的规则集,使用列出查询规则集调用来检索所有查询规则集的摘要,以及使用删除查询规则集调用来删除一个查询规则集。
执行规则查询
edit一旦你定义了一个或多个查询规则集,你可以使用规则查询来搜索这些规则集。 规则集是按顺序评估的,因此你指定的第一个规则集中的规则将在任何后续规则集之前应用。
上面定义的my-ruleset的一个示例查询是:
GET /my-index-000001/_search
{
"query": {
"rule": {
"organic": {
"query_string": {
"query": "puggles"
}
},
"match_criteria": {
"query_string": "puggles",
"user_country": "us"
},
"ruleset_ids": ["my-ruleset"]
}
}
}
此规则查询将匹配定义的查询规则集中的rule1,并将有机查询转换为固定查询,其中id1和id2作为顶部命中固定。
有机查询中的任何其他匹配项将返回在固定结果之下。
在一个规则集中,多个规则可能匹配单个规则查询。在这种情况下,规则按以下顺序应用:
- 匹配规则在规则集中的位置
- 如果在一个规则中指定了多个文档,按指定的顺序
-
如果一个文档同时匹配了
pinned规则和exclude规则,exclude规则将优先
搜索模板
edit搜索模板是一个可以与不同变量一起运行的存储搜索。
如果您使用 Elasticsearch 作为搜索后端,您可以将搜索栏中的用户输入作为搜索模板的参数传递。这使您可以在不向用户公开 Elasticsearch 的查询语法的情况下运行搜索。
如果您为自定义应用程序使用Elasticsearch,搜索模板可以让您在不修改应用程序代码的情况下更改搜索。
创建搜索模板
edit要创建或更新搜索模板,请使用创建存储脚本 API。
请求的 source 支持与 搜索 API 请求体相同的参数。source 还接受来自开源项目 mustache.java 的 Mustache 变量。
通常,Mustache 变量被包含在双大括号中:{{my-var}}。当你运行一个模板搜索时,Elasticsearch 会将这些变量替换为来自 params 的值。要了解更多关于 mustache 语法的信息 - 请参阅 Mustache.js 手册。搜索模板必须使用 lang 为 mustache。
以下请求创建一个带有id为my-search-template的搜索模板。
PUT _scripts/my-search-template
{
"script": {
"lang": "mustache",
"source": {
"query": {
"match": {
"message": "{{query_string}}"
}
},
"from": "{{from}}",
"size": "{{size}}"
}
}
}
Elasticsearch 将搜索模板存储为 Mustache 脚本 在集群状态中。Elasticsearch 在 template 脚本上下文中编译搜索模板。限制或禁用脚本的设置也会影响搜索模板。
验证搜索模板
edit要使用不同的参数测试模板,请使用渲染搜索模板API。
POST _render/template
{
"id": "my-search-template",
"params": {
"query_string": "hello world",
"from": 20,
"size": 10
}
}
当渲染时,模板输出一个搜索请求体。
{
"template_output": {
"query": {
"match": {
"message": "hello world"
}
},
"from": "20",
"size": "10"
}
}
您还可以使用API来测试内联模板。
POST _render/template
{
"source": {
"query": {
"match": {
"message": "{{query_string}}"
}
},
"from": "{{from}}",
"size": "{{size}}"
},
"params": {
"query_string": "hello world",
"from": 20,
"size": 10
}
}
运行模板化搜索
edit要使用搜索模板进行搜索,请使用搜索模板 API。您可以在每次请求中指定不同的参数。
GET my-index/_search/template
{
"id": "my-search-template",
"params": {
"query_string": "hello world",
"from": 0,
"size": 10
}
}
响应使用与search API响应相同的属性。
{
"took": 36,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.5753642,
"hits": [
{
"_index": "my-index",
"_id": "1",
"_score": 0.5753642,
"_source": {
"message": "hello world"
}
}
]
}
}
运行多个模板化搜索
edit要通过单个请求运行多个模板化搜索,请使用多搜索模板API。这些请求通常比多个单独搜索具有更少的开销和更快的速度。
GET my-index/_msearch/template
{ }
{ "id": "my-search-template", "params": { "query_string": "hello world", "from": 0, "size": 10 }}
{ }
{ "id": "my-other-search-template", "params": { "query_type": "match_all" }}
获取搜索模板
edit要检索搜索模板,请使用获取存储脚本API。
GET _scripts/my-search-template
要获取所有搜索模板和其他存储脚本的列表,请使用集群状态 API。
GET _cluster/state/metadata?pretty&filter_path=metadata.stored_scripts
删除搜索模板
edit要删除搜索模板,请使用删除存储脚本 API。
DELETE _scripts/my-search-template
设置默认值
edit要为变量设置默认值,请使用以下语法:
{{my-var}}{{^my-var}}default value{{/my-var}}
如果模板化搜索在其 params 中未指定值,搜索将使用默认值。例如,以下模板为 from 和 size 设置了默认值。
POST _render/template
{
"source": {
"query": {
"match": {
"message": "{{query_string}}"
}
},
"from": "{{from}}{{^from}}0{{/from}}",
"size": "{{size}}{{^size}}10{{/size}}"
},
"params": {
"query_string": "hello world"
}
}
URL 编码字符串
edit使用 {{#url}} 函数对字符串进行 URL 编码。
POST _render/template
{
"source": {
"query": {
"term": {
"url.full": "{{#url}}{{host}}/{{page}}{{/url}}"
}
}
},
"params": {
"host": "http://example.com",
"page": "hello-world"
}
}
模板渲染为:
{
"template_output": {
"query": {
"term": {
"url.full": "http%3A%2F%2Fexample.com%2Fhello-world"
}
}
}
}
连接值
edit使用 {{#join}} 函数将数组值连接为逗号分隔的字符串。例如,以下模板将连接两个电子邮件地址。
POST _render/template
{
"source": {
"query": {
"match": {
"user.group.emails": "{{#join}}emails{{/join}}"
}
}
},
"params": {
"emails": [ "user1@example.com", "user_one@example.com" ]
}
}
模板渲染为:
{
"template_output": {
"query": {
"match": {
"user.group.emails": "user1@example.com,user_one@example.com"
}
}
}
}
您还可以指定自定义分隔符。
POST _render/template
{
"source": {
"query": {
"range": {
"user.effective.date": {
"gte": "{{date.min}}",
"lte": "{{date.max}}",
"format": "{{#join delimiter='||'}}date.formats{{/join delimiter='||'}}"
}
}
}
},
"params": {
"date": {
"min": "2098",
"max": "06/05/2099",
"formats": ["dd/MM/yyyy", "yyyy"]
}
}
}
模板渲染为:
{
"template_output": {
"query": {
"range": {
"user.effective.date": {
"gte": "2098",
"lte": "06/05/2099",
"format": "dd/MM/yyyy||yyyy"
}
}
}
}
}
转换为JSON
edit使用 {{#toJson}} 函数将变量值转换为其 JSON 表示形式。
例如,以下模板使用 {{#toJson}} 来传递一个数组。为了确保请求体是有效的 JSON,source 以字符串格式编写。
POST _render/template
{
"source": "{ \"query\": { \"terms\": { \"tags\": {{#toJson}}tags{{/toJson}} }}}",
"params": {
"tags": [
"prod",
"es01"
]
}
}
模板渲染为:
{
"template_output": {
"query": {
"terms": {
"tags": [
"prod",
"es01"
]
}
}
}
}
您也可以使用 {{#toJson}} 来传递对象。
POST _render/template
{
"source": "{ \"query\": {{#toJson}}my_query{{/toJson}} }",
"params": {
"my_query": {
"match_all": { }
}
}
}
模板渲染为:
{
"template_output" : {
"query" : {
"match_all" : { }
}
}
}
您也可以传递一个对象数组。
POST _render/template
{
"source": "{ \"query\": { \"bool\": { \"must\": {{#toJson}}clauses{{/toJson}} }}}",
"params": {
"clauses": [
{
"term": {
"user.id": "kimchy"
}
},
{
"term": {
"url.domain": "example.com"
}
}
]
}
}
模板渲染为:
{
"template_output": {
"query": {
"bool": {
"must": [
{
"term": {
"user.id": "kimchy"
}
},
{
"term": {
"url.domain": "example.com"
}
}
]
}
}
}
}
使用条件
edit要创建条件语句,请使用以下语法:
{{#condition}}content{{/condition}}
如果条件变量为true,Elasticsearch 会显示其内容。例如,以下模板会在year_scope为true时搜索过去一年的数据。
POST _render/template
{
"source": "{ \"query\": { \"bool\": { \"filter\": [ {{#year_scope}} { \"range\": { \"@timestamp\": { \"gte\": \"now-1y/d\", \"lt\": \"now/d\" } } }, {{/year_scope}} { \"term\": { \"user.id\": \"{{user_id}}\" }}]}}}",
"params": {
"year_scope": true,
"user_id": "kimchy"
}
}
模板渲染为:
{
"template_output" : {
"query" : {
"bool" : {
"filter" : [
{
"range" : {
"@timestamp" : {
"gte" : "now-1y/d",
"lt" : "now/d"
}
}
},
{
"term" : {
"user.id" : "kimchy"
}
}
]
}
}
}
}
如果 year_scope 是 false,模板会从任意时间段搜索数据。
POST _render/template
{
"source": "{ \"query\": { \"bool\": { \"filter\": [ {{#year_scope}} { \"range\": { \"@timestamp\": { \"gte\": \"now-1y/d\", \"lt\": \"now/d\" } } }, {{/year_scope}} { \"term\": { \"user.id\": \"{{user_id}}\" }}]}}}",
"params": {
"year_scope": false,
"user_id": "kimchy"
}
}
模板渲染为:
{
"template_output" : {
"query" : {
"bool" : {
"filter" : [
{
"term" : {
"user.id" : "kimchy"
}
}
]
}
}
}
}
要创建if-else条件,请使用以下语法:
{{#condition}}if content{{/condition}} {{^condition}}else content{{/condition}}
例如,如果year_scope为true,以下模板将搜索过去一年的数据。否则,它将搜索过去一天的数据。
POST _render/template
{
"source": "{ \"query\": { \"bool\": { \"filter\": [ { \"range\": { \"@timestamp\": { \"gte\": {{#year_scope}} \"now-1y/d\" {{/year_scope}} {{^year_scope}} \"now-1d/d\" {{/year_scope}} , \"lt\": \"now/d\" }}}, { \"term\": { \"user.id\": \"{{user_id}}\" }}]}}}",
"params": {
"year_scope": true,
"user_id": "kimchy"
}
}
使用 Mustache 的搜索模板示例
editMustache 模板语言定义了各种标签类型,您可以在模板中使用这些标签。以下部分描述了其中一些标签类型,并提供了在 Elasticsearch 搜索模板中使用它们的示例。
Mustache 变量
editMustache标签通常用双大括号括起来。一个Mustache变量:{{my-variable}} 是一种Mustache标签。当你运行一个模板搜索时,Elasticsearch会将这些变量替换为来自params的值。
例如,考虑以下搜索模板:
PUT _scripts/my-search-template
{
"script": {
"lang": "mustache",
"source": {
"query": {
"match": {
"message": "{{query_string}}"
}
},
"from": "{{from}}",
"size": "{{size}}"
}
}
}
测试上述搜索模板与params:
POST _render/template
{
"id": "my-search-template",
"params": {
"query_string": "hello world",
"from": 20,
"size": 10
}
}
当渲染时,message 中的 {{query_string}} 被 params 中传递的 hello world 替换。
{
"template_output": {
"query": {
"match": {
"message": "hello world"
}
},
"from": "20",
"size": "10"
}
}
如果您的搜索模板没有向 query_string 传递值,消息将被替换为一个空字符串。
例如:
POST _render/template
{
"id": "my-search-template",
"params": {
"from": 20,
"size": 10
}
}
渲染后,模板输出为:
{
"template_output": {
"query": {
"match": {
"message": ""
}
},
"from": "20",
"size": "10"
}
}
部分
edit部分也是Mustache标签的一种类型。您可以在搜索模板中使用部分与嵌套或非嵌套对象。一个部分以{{#my-section-variable}}开始,并以{{/my-section-variable}}结束。
以下搜索模板展示了一个使用带有嵌套对象的部分的示例:
POST _render/template
{
"source":
"""
{
"query": {
"match": {
{{#query_message}}
{{#query_string}}
"message": "Hello {{#first_name_section}}{{first_name}}{{/first_name_section}} {{#last_name_section}}{{last_name}}{{/last_name_section}}"
{{/query_string}}
{{/query_message}}
}
}
}
""",
"params": {
"query_message": {
"query_string": {
"first_name_section": {"first_name": "John"},
"last_name_section": {"last_name": "kimchy"}
}
}
}
}
模板渲染为:
{
"template_output": {
"query": {
"match": {
"message": "Hello John kimchy"
}
}
}
}
列表
edit您可以传递一个对象列表并在搜索模板中循环遍历每个项目。
例如,以下搜索模板结合了sections并匹配所有用户名:
PUT _scripts/my-search-template
{
"script": {
"lang": "mustache",
"source": {
"query":{
"multi_match":{
"query": "{{query_string}}",
"fields": """[{{#text_fields}}{{user_name}},{{/text_fields}}]"""
}
}
}
}
}
测试模板:
POST _render/template
{
"id": "my-search-template",
"params": {
"query_string": "My string",
"text_fields": [
{
"user_name": "John"
},
{
"user_name": "kimchy"
}
]
}
}
渲染时,模板输出:
{
"template_output": {
"query": {
"multi_match": {
"query": "My string",
"fields": "[John,kimchy,]"
}
}
}
}
上述内容会导致尾随逗号问题,从而导致无效的JSON。一个解决方法是在数组中包含一个反向部分,并添加一个变量以确保它是数组中的最后一项。
例如:
PUT _scripts/my-search-template
{
"script": {
"lang": "mustache",
"source": {
"query":{
"multi_match":{
"query": "{{query_string}}",
"fields": """[{{#text_fields}}{{user_name}}{{^last}},{{/last}}{{/text_fields}}]"""
}
}
}
}
}
再次测试 my-search-template 模板,使用变量:last 来确定它是数组中的最后一项:
POST _render/template
{
"id": "my-search-template",
"params": {
"query_string": "My string",
"text_fields": [
{
"user_name": "John",
"last": false
},
{
"user_name": "kimchy",
"last": true
}
]
}
}
当渲染模板时,输出如下:
{
"template_output": {
"query": {
"multi_match": {
"query": "My string",
"fields": "[John,kimchy]"
}
}
}
}
Lambdas
editElasticsearch 提供了预先构建的自定义函数,用于支持将文本转换为特定格式。
要了解更多关于 mustache lambdas 的使用方法,请查看 Url encode strings、Concatenate values 和 Convert to json 中的示例。
反向部分
edit反向部分在您希望一次性设置值时非常有用。
要使用反转部分,请使用以下语法:
{{^my-variable}} content {{/my-variable}}
例如,在以下搜索模板中,如果 name_exists 为 false,则 message 被设置为 Hello World,否则它被设置为空字符串。
POST _render/template
{
"source": {
"query": {
"match": {
"message": "{{^name_exists}}Hello World{{/name_exists}}"
}
}
},
"params": {
"name_exists": false
}
}
例如,在以下搜索模板中,如果 name_exists 是 true,则 {{query_string}} 的值将被替换。如果 name_exists 是 false,则它将被设置为默认值 World。
POST _render/template
{
"source": {
"query": {
"match": {
"message": "Hello {{#name_exists}}{{query_string}}{{/name_exists}}{{^name_exists}}World{{/name_exists}}"
}
}
},
"params": {
"query_string": "Kimchy",
"name_exists": true
}
}
渲染时,模板输出:
{
"template_output": {
"query": {
"match": {
"message": "Hello Kimchy"
}
}
}
}
设置分隔符
edit您可以将默认的分隔符:双大括号 {{my-variable}} 更改为搜索模板中的任何自定义分隔符。
例如,以下搜索模板将默认分隔符更改为单个圆括号 (query_string)。
PUT _scripts/my-search-template
{
"script": {
"lang": "mustache",
"source":
"""
{
"query": {
"match": {
{{=( )=}}
"message": "(query_string)"
(={{ }}=)
}
}
}
"""
}
}
使用新分隔符测试模板:
POST _render/template
{
"id": "my-search-template",
"params": {
"query_string": "hello world"
}
}
渲染时,模板输出:
{
"template_output": {
"query": {
"match": {
"message": "hello world"
}
}
}
}
不支持的功能
edit以下 Mustache 特性在 Elasticsearch 搜索模板中不受支持:
- 部分
检索器
edit检索器是在8.14.0版本中添加到Search API中的一个抽象概念,并在8.16.0版本中正式发布。
这个抽象概念使得在单个_search调用中可以配置多阶段检索管道。
这简化了您的搜索应用程序逻辑,因为您不再需要通过多个Elasticsearch调用来配置复杂搜索,也不需要实现额外的客户端逻辑来组合来自不同查询的结果。
本文档提供了检索器抽象的总体概述。
有关实现细节,包括显著的限制,请查看_search API 文档中的参考文档。
检索器类型
edit检索器有多种类型,每种都针对不同的搜索操作进行了定制。 以下是目前可用的检索器:
-
标准检索器。从传统的查询中返回顶级文档。
模仿传统的查询,但在检索器框架的上下文中。这确保了向后兼容性,因为现有的
_search请求仍然受支持。 这样您可以在不混合语法的情况下,按照自己的节奏过渡到新的抽象。 - kNN检索器。从kNN搜索中返回顶级文档, 在检索器框架的上下文中。
-
RRF检索器。使用倒数排名融合(RRF)算法组合和排序多个第一阶段检索器。允许您将具有不同相关性指示符的多个结果集组合成一个结果集。
RRF检索器是一个复合检索器,其中其
filter元素会传播到其子检索器。 -
文本相似度重排序检索器。用于语义重排序。
需要首先使用Elasticsearch推理API创建一个
rerank任务。
是什么让检索器变得有用?
edit以下是关于检索器的有用之处以及它们与常规查询的区别的概述。
- 简化的用户体验. 检索器通过允许在单个 API 调用中配置整个检索管道来简化用户体验。 这通过自动将它们转换为适当的检索器来保持与传统查询元素的向后兼容性。
- 结构化检索. 检索器提供了一种更结构化的方式来定义搜索操作。 它们允许使用“检索树”来描述搜索,这是一种分层结构,阐明了操作的顺序和逻辑,使复杂的搜索更易于理解和操作。
- 可组合性和灵活性. 检索器支持灵活的可组合性,允许您构建管道并将不同的检索策略无缝集成到这些管道中。 检索器使得测试不同的检索策略组合变得容易。
- 复合操作. 一个检索器可以有子检索器。 这允许复杂的嵌套搜索,其中一个检索器的结果可以输入到另一个检索器中,支持可能涉及多个阶段或标准的复杂查询策略。
- 检索作为第一类概念. 与传统查询不同,传统查询是更大搜索 API 调用的一部分,检索器被设计为可以组合或单独使用的独立实体。 这使得构建搜索的方法更加模块化和灵活。
-
增强对文档评分和排序的控制.
检索器允许对文档的评分和过滤进行更明确的控制。
例如,您可以指定最低分数阈值,应用不影响评分的复杂过滤器,并使用
terminate_after等参数进行性能优化。 -
与现有 Elasticsearch 功能的集成.
尽管检索器可以替代现有的
_searchAPI 语法(如query和knn),但它们被设计为与分页(search_after)和排序等功能无缝集成。 它们还通过将所有叶检索器的组合视为布尔查询中的should子句来保持与聚合操作的兼容性。 - 更清晰的职责分离. 在使用复合检索器时,只允许查询元素,这强制执行了更清晰的职责分离,并防止了可能由过度嵌套或相互依赖的配置引起的复杂性。
示例
edit以下示例展示了我们现在可以编写的强大查询,以及检索器如何简化这一过程。我们可以使用我们想要的任何检索器组合,将嵌套检索器的结果传递给其父检索器。在这个场景中,我们将使用所有4个(目前)可用的检索器,即standard、knn、text_similarity_reranker和rrf。
我们将首先结合使用standard检索器进行的semantic查询的结果,以及在密集向量字段上使用knn搜索的结果,使用rrf获取前100个结果。
最后,我们将使用text_similarity_reranker对rrf的前50个结果进行重新排序。
GET example-index/_search
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"semantic": {
"field": "inference_field",
"query": "state of the art vector database"
}
}
}
},
{
"knn": {
"query_vector": [
0.54,
...,
0.245
],
"field": "embedding",
"k": 10,
"num_candidates": 15
}
}
],
"rank_window_size": 100,
"rank_constant": 10
}
},
"rank_window_size": 50,
"field": "description",
"inference_text": "what's the best way to create complex pipelines and retrieve documents?",
"inference_id": "my-awesome-rerank-model"
}
}
}
术语表
edit以下是一些重要术语:
- 检索管道。定义了整个检索和排序逻辑,以生成顶部结果。
- 检索器树。定义检索器如何交互的分层结构。
- 第一阶段检索器。返回初始的候选文档集。
- 复合检索器。基于一个或多个检索器构建,增强文档检索和排序逻辑。
- 组合器。合并多个子检索器顶部结果的复合检索器。
- 重排器。特殊复合检索器,用于重新排序结果并可能调整结果数量,区分第一阶段和第二阶段重排器。
检索器在行动
edit搜索操场使用检索器抽象构建Elasticsearch查询。 它会自动检测索引中的字段和类型,并根据您的选择构建检索器树。
您可以使用Playground来试验不同的检索器配置,并查看它们如何影响搜索结果。
有关更多信息,请参阅Playground 文档。
API 参考
edit有关实现细节,包括显著的限制,请查看搜索API文档中的参考文档。