欢迎来到Fugue教程!
目录
欢迎来到Fugue教程!#
有问题吗?在Github或Slack上与我们聊天:
![]()
Fugue 提供了一个更简单的界面来有效使用分布式计算,并加速大数据项目。它通过最小化您需要编写的代码量来实现这一点,同时处理各种技巧和优化,从而在分布式计算上实现更高效的执行。Fugue 将 Python、Pandas 和 SQL 代码移植到 Spark、Dask 和 Ray。
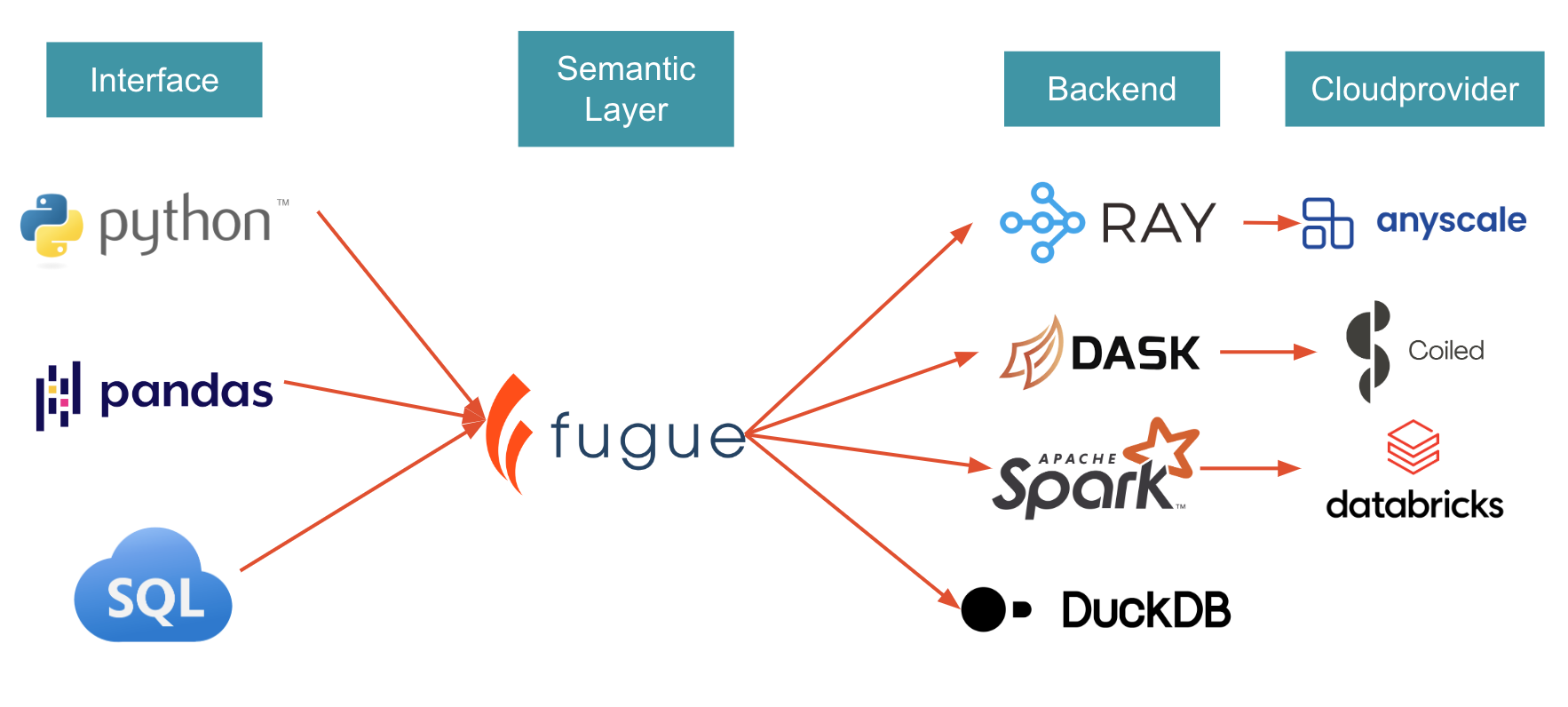
快速链接:
将Pandas代码扩展到Spark、Dask或Ray?从Fugue in 10 minutes开始。
需要在Pandas、Spark和Dask之上使用SQL接口?查看FugueSQL in 10 minutes。
关于之前的会议演讲和博客文章,请查看内容页面。
Fugue 与其它工具相比如何?#
Spark, Dask, Ray#
Fugue 简化了这些后端的使用。它不重复造轮子。Fugue 始终会下推到这些底层引擎。Fugue 的目标是尽量减少用户需要学习的框架特定代码量,以便利用这些引擎。Fugue 还充当本地测试和大规模执行之间的桥梁。
PySpark Pandas, Modin#
与Fugue类似,PySpark Pandas和Modin旨在简化使用大数据框架的体验。不同之处在于Fugue并不旨在成为Pandas的直接替代品,因为它是一个次优接口用于分布式计算。有许多操作(特别是围绕索引的操作)在分布式环境中无法很好地转换。Fugue主张工具分离,并利用每个工具的优势。支持并鼓励使用Pandas代码来描述业务逻辑,但Fugue将使用Spark、Dask或Ray来分发这些多个Pandas作业。
dbt#
dbt 是一个编程接口,可将代码下推到后端(Snowflake、Spark)。Fugue 也有 FugueSQL,这是一个类似 SQL 的接口,用于下推到后端(DuckDB、Spark、Dask)。FugueSQL 也正在通过 BigQuery 和 Trino 等集成扩展到数据仓库端。dbt 和 Fugue 的主要区别在于 Fugue 不限制用户使用 SQL。它还支持 Python(并鼓励混合使用 SQL 和 Python)。dbt 支持 Python,但它不是一等公民,也不具备可扩展性。
DuckDB#
DuckDB 是 Fugue 的后端,允许用户在本地环境中进行代码原型设计,然后通过切换后端进行扩展。更多信息,请参阅 DuckDB 文档
Ibis#
Fugue 有一个 Ibis 集成,主要用于访问各种数据存储中的数据。例如,我们在底层也使用它来实现我们的 BigQuery 集成。
差异:
Fugue 保证后端之间的一致性。NULL 处理可能因后端不同而有所差异。例如,Pandas 会将 NULL 与 NULL 连接,而 Spark 则不会。因此,如果用户在本地使用 Pandas 进行原型设计,然后扩展到 Spark,Fugue 能保证结果一致。Fugue 经过 100% 单元测试,所有后端都通过相同的测试套件。
Ibis 是面向 SQL 后端的 Python 化工具。我们拥抱 SQL,但也理解其局限性。FugueSQL 是一种增强型 SQL 方言,可以调用 Python 代码。FugueSQL 可以作为一等语法,而不必被 Python 代码夹在中间。Fugue 的 Python API 和 SQL API 在功能上是 1:1 对应的。
Fugue不希望用户学习任何新语言。Ibis是一种表达事物的新方式;我们只想扩展人们已经掌握的能力(SQL、原生Python和Pandas)。Fugue也可以逐步采用,意味着它可以仅用于您工作流程的一部分。
从路线图来看,Fugue认为最优解决方案将是不同工具的混合使用。一个明显的例子是使用DuckDB预聚合数据,然后使用Pandas进行进一步处理。同样地,我们能否在Snowflake中进行预处理,然后在Spark中进行机器学习?Fugue正在努力连接这些不同的系统,以实现跨平台工作负载。
Polars#
Polars 是一个类似于 Pandas 的本地引擎。Fugue 有一个 Polars 集成,允许用户在 Spark、Dask 或 Ray 集群上运行 Polars 代码。
安装#
为了设置您自己的环境,您可以通过pip(或conda)安装该包。Fugue随后可以
pip install fugue
后端引擎通过 pip extras 单独安装。例如,要安装 Spark:
pip install "fugue[spark]"
如果您的机器上已安装Spark、Dask或Ray,Fugue将能够检测到它们。Spark需要单独安装Java。
运行代码#
以交互方式运行本教程的最简单方法是使用 mybinder。Binder 使用容器启动环境。
某些代码片段在binder上运行缓慢,因为binder上的机器对于像Spark这样的分布式框架来说性能不够强大。
并行执行可能会变成串行,因此某些性能对比示例无法提供准确的数值。
另外,如果您在自己的机器上运行Docker镜像,应该能获得不错的性能:
docker run -p 8888:8888 fugueproject/tutorials:latest