教程
本页面是igraph的Python功能的详细教程。要快速了解igraph的功能,请查看快速入门。如果您尚未安装igraph,请按照安装igraph部分的说明进行操作。
注意
对于不耐烦的读者,请参阅示例画廊页面,查看简短、自包含的示例。
开始使用 igraph
使用igraph最常见的方式是在Python环境中作为命名导入(例如,一个简单的Python shell,一个IPython shell,一个Jupyter笔记本或JupyterLab实例,Google Colab,或一个IDE):
$ python
Python 3.9.6 (default, Jun 29 2021, 05:25:02)
[Clang 12.0.5 (clang-1205.0.22.9)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import igraph as ig
要调用函数,您需要在它们前面加上 ig(或您选择的任何名称):
>>> import igraph as ig
>>> print(ig.__version__)
0.9.8
启动igraph的第二种方法是从终端调用脚本igraph:
$ igraph
No configuration file, using defaults
igraph 0.9.6 running inside Python 3.9.6 (default, Jun 29 2021, 05:25:02)
Type "copyright", "credits" or "license" for more information.
>>>
注意
Windows用户将在Python的scripts子目录中找到该脚本,并且可能需要手动将其添加到他们的路径中。
此脚本启动一个合适的 shell(如果找到 IPython 或 IDLE,否则启动一个纯 Python shell)并使用星号导入(见上文)。这对于尝试 igraph 的函数有时很方便。
注意
你可以通过igraph的Configuration文件指定此脚本应使用的shell。
本教程假设您已经使用命名空间 ig 导入了 igraph。
创建图表
创建图形的最简单方法是使用Graph构造函数。要创建一个空图:
>>> g = ig.Graph()
创建一个包含10个节点(编号从0到9)的图,并连接节点0-1和0-5的两条边:
>>> g = ig.Graph(n=10, edges=[[0, 1], [0, 5]])
我们可以打印图表以获取其节点和边的摘要:
>>> print(g)
IGRAPH U--- 10 2 --
+ edges:
0--1 0--5
这意味着:具有10个顶点和2条边的U无向图,并列出确切的边。如果图具有name属性,它也会被打印出来。
注意
igraph 还有一个 igraph.summary() 函数,它与 print() 类似,但不会列出边。这对于具有数百万条边的大型图非常方便:
>>> ig.summary(g)
IGRAPH U--- 10 2 --
添加/删除顶点和边
让我们再次从空图开始。要向现有图添加顶点,请使用 Graph.add_vertices():
>>> g = ig.Graph()
>>> g.add_vertices(3)
在igraph中,顶点总是从零开始编号。顶点的编号称为顶点ID。一个顶点可能有也可能没有名称。
同样地,要添加边,请使用 Graph.add_edges():
>>> g.add_edges([(0, 1), (1, 2)])
通过指定每条边的源顶点和目标顶点来添加边。此调用添加了两条边,一条连接顶点 0 和 1,另一条连接顶点 1 和 2。边也从零开始编号(边ID),并且可以有一个可选的名称。
警告
创建一个空图并添加顶点和边,如这里所示,可能比之前演示的创建带有顶点和边的图要慢得多。如果速度是一个问题,你应该特别避免一次一个地添加顶点和边。如果你仍然需要这样做,你可以使用Graph.add_vertex()和Graph.add_edge()。
如果你尝试向无效ID的顶点添加边(例如,当图中只有三个顶点时,你尝试向顶点5添加边),你会得到一个igraph.InternalError异常:
>>> g.add_edges([(5, 4)])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.10/site-packages/igraph/__init__.py", line 376, in add_edges
res = GraphBase.add_edges(self, es)
igraph._igraph.InternalError: Error at src/graph/type_indexededgelist.c:270: cannot add edges. -- Invalid vertex id
该消息试图解释出错的原因(cannot add edges. -- Invalid
vertex id)以及错误发生的源代码中的相应行。
注意
完整的回溯信息,包括源代码信息,在报告错误时非常有用,特别是在我们的 GitHub 问题页面上。如果您创建了一个新问题,请包含这些信息!
让我们向图中添加更多的顶点和边:
>>> g.add_edges([(2, 0)])
>>> g.add_vertices(3)
>>> g.add_edges([(2, 3), (3, 4), (4, 5), (5, 3)])
>>> print(g)
IGRAPH U---- 6 7 --
+ edges:
0--1 1--2 0--2 2--3 3--4 4--5 3--5
我们现在有一个包含6个顶点和7条边的无向图。顶点和边的ID始终是连续的,因此如果你删除一个顶点,所有后续的顶点将被重新编号。当一个顶点被重新编号时,边不会被重新编号,但它们的源和目标顶点会。使用Graph.delete_vertices()和Graph.delete_edges()来执行这些操作。例如,要删除连接顶点2-3的边,获取其ID然后删除它:
>>> g.get_eid(2, 3)
3
>>> g.delete_edges(3)
生成图表
igraph 包含确定性和随机性图生成器(参见 图生成)。 确定性 生成器每次调用函数时都会生成相同的图,例如:
>>> g = ig.Graph.Tree(127, 2)
>>> summary(g)
IGRAPH U--- 127 126 --
使用 Graph.Tree() 生成一个具有127个顶点的规则树图,每个顶点有两个子节点(当然还有一个父节点)。无论你调用多少次 Graph.Tree(),只要你使用相同的参数,生成的图将始终相同:
>>> g2 = ig.Graph.Tree(127, 2)
>>> g2.get_edgelist() == g.get_edgelist()
True
上面的代码片段还向你展示了get_edgelist()方法,
它返回所有边的源顶点和目标顶点的列表,按边ID排序。
如果你打印前10个元素,你会得到:
>>> g2.get_edgelist()[:10]
[(0, 1), (0, 2), (1, 3), (1, 4), (2, 5), (2, 6), (3, 7), (3, 8), (4, 9), (4, 10)]
随机生成器每次都会生成不同的图,例如 Graph.GRG():
>>> g = ig.Graph.GRG(100, 0.2)
>>> summary(g)
IGRAPH U---- 100 516 --
+ attr: x (v), y (v)
注意
+ attr 显示顶点(v)和边(e)的属性,在这种情况下有两个顶点属性,没有边属性。
这将生成一个几何随机图:在单位正方形内随机且均匀地选择n个点,并且如果点对之间的距离小于预定义的距离d,则通过边连接。如果你用相同的参数生成GRG,它们将会不同:
>>> g2 = ig.Graph.GRG(100, 0.2)
>>> g.get_edgelist() == g2.get_edgelist()
False
一种稍微宽松的方式来检查图形是否等价是通过 isomorphic():
>>> g.isomorphic(g2)
False
检查大图的同构性可能需要一些时间(在这种情况下,可以通过检查两个图的度分布来快速给出答案)。
设置和检索属性
如上所述,igraph 中的图的顶点和边具有从 0 开始的数字ID。因此,删除顶点或边可能会导致顶点和/或边ID的重新分配。除了ID之外,顶点和边还可以具有属性,例如名称、绘图的坐标、元数据和权重。图本身也可以具有这些属性(例如名称,它将在 print 或 Graph.summary() 中显示)。从某种意义上说,每个 Graph、顶点和边都可以用作Python字典来存储和检索这些属性。
为了演示属性的使用,让我们创建一个简单的社交网络:
>>> g = ig.Graph([(0,1), (0,2), (2,3), (3,4), (4,2), (2,5), (5,0), (6,3), (5,6)])
每个顶点代表一个人,因此我们想要存储姓名、年龄和性别:
>>> g.vs["name"] = ["Alice", "Bob", "Claire", "Dennis", "Esther", "Frank", "George"]
>>> g.vs["age"] = [25, 31, 18, 47, 22, 23, 50]
>>> g.vs["gender"] = ["f", "m", "f", "m", "f", "m", "m"]
>>> g.es["is_formal"] = [False, False, True, True, True, False, True, False, False]
Graph.vs 和 Graph.es 是分别获取所有顶点和边的标准方法。就像 Python 字典一样,我们可以使用方括号设置每个属性。值必须是一个与顶点(对于 Graph.vs)或边(对于 Graph.es)长度相同的列表。这将一次性为所有顶点/边分配一个属性。
要为单个顶点/边分配或修改属性,可以使用索引:
>>> g.es[0]["is_formal"] = True
实际上,单个顶点通过类 Vertex 表示,单个边通过 Edge 表示。它们两者加上 Graph 都可以像字典一样设置属性,例如为图添加日期:
>>> g["date"] = "2009-01-10"
>>> print(g["date"])
2009-01-10
要检索属性字典,您可以使用 Graph.attributes(), Vertex.attributes(), 和 Edge.attributes().
此外,每个Vertex都有一个特殊属性Vertex.index,用于查找顶点的ID。每个Edge都有Edge.index以及两个额外的属性Edge.source和Edge.target,用于查找由该边连接的顶点的ID。要一次性获取两者作为元组,可以使用Edge.tuple。
要为顶点或边的子集分配属性,可以使用切片:
>>> g.es[:1]["is_formal"] = True
g.es[:1] 的输出是 EdgeSeq 的一个实例,而 VertexSeq 是表示顶点子集的等效类。
要删除属性,请使用Python关键字 del,例如:
>>> g.vs[3]["foo"] = "bar"
>>> g.vs["foo"]
[None, None, None, 'bar', None, None, None]
>>> del g.vs["foo"]
>>> g.vs["foo"]
Traceback (most recent call last):
File "<stdin>", line 25, in <module>
KeyError: 'Attribute does not exist'
警告
属性可以是任意的Python对象,但如果你将图保存到文件中,只有字符串和数字属性会被保留。如果你正在寻找保存其他属性类型的方法,请参阅标准Python库中的pickle模块。你可以单独pickle你的属性,将它们存储为字符串并保存,或者如果你知道你只想将图加载回Python,你可以pickle整个Graph。
图的结构属性
除了上述简单的图形和属性操作例程外, igraph 提供了大量方法来计算图形的各种结构属性。 本教程的范围无法涵盖所有这些方法,因此 本节仅介绍其中一些以作说明。 我们将使用上一节中构建的小型社交网络。
可能想到的最简单的属性是顶点度。顶点的度等于与其相邻的边的数量。在有向网络的情况下,我们还可以定义入度(指向顶点的边的数量)和出度(从顶点出发的边的数量)。igraph能够使用简单的语法计算所有这些:
>>> g.degree()
[3, 1, 4, 3, 2, 3, 2]
如果图是有向的,我们将能够分别使用g.degree(mode="in")和g.degree(mode="out")计算入度和出度。你也可以传递一个单一的顶点ID或顶点ID列表到degree(),如果你只想计算一部分顶点的度数:
>>> g.degree(6)
2
>>> g.degree([2,3,4])
[4, 3, 2]
此调用约定适用于igraph可以计算的大多数结构属性。对于顶点属性,方法接受一个顶点ID或顶点ID列表(如果省略,则默认为所有顶点的集合)。对于边属性,方法接受单个边ID或边ID列表。除了ID列表外,您还可以提供VertexSeq或EdgeSeq实例。在下一章中,您将学习如何将它们限制为您想要的顶点或边。
注意
对于某些度量,仅对少数顶点或边而不是整个图进行计算是没有意义的,因为无论如何都需要相同的时间。在这种情况下,方法不会接受顶点或边的ID,但你仍然可以使用标准的列表索引和切片操作符来限制结果列表。一个这样的例子是特征向量中心性(Graph.evcent())。
除了度之外,igraph 还包括内置的例程来计算许多其他中心性属性,包括顶点和边的中介中心性
(Graph.betweenness,
Graph.edge_betweenness) 或谷歌的PageRank
(Graph.pagerank()) 仅举几例。这里我们仅展示边的中介中心性:
>>> g.edge_betweenness()
[6.0, 6.0, 4.0, 2.0, 4.0, 3.0, 4.0, 3.0. 4.0]
现在我们也可以用一些Python魔法找出哪些连接具有最高的中介中心性:
>>> ebs = g.edge_betweenness()
>>> max_eb = max(ebs)
>>> [g.es[idx].tuple for idx, eb in enumerate(ebs) if eb == max_eb]
[(0, 1), (0, 2)]
大多数结构属性也可以通过调用VertexSeq、EdgeSeq、Vertex或Edge对象上的适当方法来检索顶点或边的子集或单个顶点或边的信息:
>>> g.vs.degree()
[3, 1, 4, 3, 2, 3, 2]
>>> g.es.edge_betweenness()
[6.0, 6.0, 4.0, 2.0, 4.0, 3.0, 4.0, 3.0. 4.0]
>>> g.vs[2].degree()
4
基于属性查询顶点和边
选择顶点和边
想象一下,在一个给定的社交网络中,你可能想要找出谁拥有最大的度数或中介中心性。你可以使用到目前为止介绍的工具和一些基本的Python知识来完成这个任务,但由于基于属性或结构特性选择顶点和边是一个常见的任务,igraph为你提供了一种更简单的方法来实现这一点:
>>> g.vs.select(_degree=g.maxdegree())["name"]
['Claire']
语法初看可能有点别扭,所以让我们一步步来解释。select() 是 VertexSeq 的一个方法,其唯一目的是根据单个顶点的属性来过滤 VertexSeq。它过滤顶点的方式取决于其位置参数和关键字参数。位置参数(如上面的 _degree 这样没有明确名称的参数)总是先于关键字参数处理,具体如下:
如果第一个位置参数是
None,则返回一个空序列(不包含任何顶点):>>> seq = g.vs.select(None) >>> len(seq) 0
如果第一个位置参数是一个可调用对象(即函数、绑定方法或任何行为类似于函数的东西),该对象将为当前序列中的每个顶点调用。如果函数返回
True,则该顶点将被包含,否则将被排除:>>> graph = ig.Graph.Full(10) >>> only_odd_vertices = graph.vs.select(lambda vertex: vertex.index % 2 == 1) >>> len(only_odd_vertices) 5
如果第一个位置参数是一个可迭代对象(即列表、生成器或任何可以迭代的对象),它必须返回整数,这些整数将被视为当前顶点集的索引(这不一定是整个图)。只有那些与给定索引匹配的顶点才会包含在过滤后的顶点集中。浮点数、字符串、无效的顶点ID将被静默忽略:
>>> seq = graph.vs.select([2, 3, 7]) >>> len(seq) 3 >>> [v.index for v in seq] [2, 3, 7] >>> seq = seq.select([0, 2]) # filtering an existing vertex set >>> [v.index for v in seq] [2, 7] >>> seq = graph.vs.select([2, 3, 7, "foo", 3.5]) >>> len(seq) 3
如果第一个位置参数是整数,则所有剩余参数也应为整数,并且它们被解释为当前顶点集的索引。这仅仅是语法糖,你可以通过将列表作为第一个位置参数传递来实现相同的效果,但这种方式你可以省略方括号:
>>> seq = graph.vs.select(2, 3, 7) >>> len(seq) 3
关键字参数可用于根据顶点的属性或其结构特性进行过滤。每个关键字参数的名称应最多由两部分组成:属性或结构特性的名称以及过滤操作符。操作符可以省略;在这种情况下,我们自动假设为相等操作符。可能性如下(其中name表示属性或特性的名称):
关键字参数 |
含义 |
|---|---|
|
属性/属性值必须等于关键字参数的值 |
|
属性/属性值必须不等于关键字参数的值 |
|
属性/属性值必须小于关键字参数的值 |
|
属性/属性值必须小于或等于关键字参数的值 |
|
属性/属性值必须大于关键字参数的值 |
|
属性/属性值必须大于或等于关键字参数的值 |
|
属性/属性值必须包含在关键字参数的值中,此时关键字参数必须是一个序列 |
|
属性/属性值必须不包含在关键字参数的值中,在这种情况下,关键字参数必须是一个序列 |
例如,以下命令在我们的虚构社交网络中给出年龄小于30岁的人:
>>> g.vs.select(age_lt=30)
注意
由于Python的语法限制,你不能使用g.vs.select(age < 30)这种显然更简单的语法,因为在Python的参数列表中只允许出现相等运算符。
为了节省您的输入时间,如果您愿意,甚至可以省略select()方法:
>>> g.vs(age_lt=30)
理论上,可能会出现一个属性和一个结构属性同名的情况(例如,你可能有一个名为degree的顶点属性)。在这种情况下,我们将无法确定用户是指degree作为结构属性还是顶点属性。为了解决这种歧义,结构属性名称在用于过滤时必须始终在前面加上下划线(_)。例如,要找到度数大于2的顶点:
>>> g.vs(_degree_gt=2)
还有一些用于选择边的特殊结构属性:
在
EdgeSeq.select()的关键字参数列表中使用_source或_from可以根据边的源顶点进行过滤。例如,选择所有源自Claire(顶点索引为2)的边:>>> g.es.select(_source=2)
使用
_target或_to过滤器基于目标顶点。这与_source和_from不同,如果图是有向的。_within接受一个VertexSeq对象或一个顶点索引的列表或集合,并选择所有在给定顶点集合中开始和结束的边。例如,以下表达式选择了 Claire(顶点索引 2)、Dennis(顶点索引 3)和 Esther(顶点索引 4)之间的所有边:>>> g.es.select(_within=[2,3,4])
我们也可以使用一个
VertexSeq对象:>>> g.es.select(_within=g.vs[2:5])
_between接受一个由两个VertexSeq对象或包含顶点索引或Vertex对象的列表组成的元组,并选择所有从一个集合出发并在另一个集合终止的边。例如,选择所有连接男性和女性的边:>>> men = g.vs.select(gender="m") >>> women = g.vs.select(gender="f") >>> g.es.select(_between=(men, women))
查找具有某些属性的单个顶点或边
在许多情况下,我们正在寻找具有某些属性的图的单个顶点或边,并且如果有多个匹配项,我们不在乎返回哪一个匹配项,或者我们事先知道只会有一个匹配项。一个典型的例子是通过name属性中的名称查找顶点。VertexSeq和EdgeSeq对象为这种情况提供了find()方法。find()的工作方式类似于select(),但如果有多个匹配项,它只返回第一个匹配项,如果没有找到匹配项,则抛出异常。例如,要查找对应于Claire的顶点,可以这样做:
>>> claire = g.vs.find(name="Claire")
>>> type(claire)
igraph.Vertex
>>> claire.index
2
查找一个未知的名称将会产生一个异常:
>>> g.vs.find(name="Joe")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: no such vertex
通过名称查找顶点
通过名称查找顶点是一个非常常见的操作,通常记住图中顶点的名称比记住它们的ID要容易得多。为此,igraph特别处理顶点的name属性;它们被索引,以便可以在分摊的常数时间内通过名称查找顶点。为了使事情更加简单,igraph在需要顶点ID的地方几乎都接受顶点名称,并且在需要顶点ID列表或VertexSeq实例的地方也接受顶点名称的集合(列表、元组等)。例如,你可以简单地查找Dennis的度数(连接数)如下:
>>> g.degree("Dennis")
3
或者,另一种选择:
>>> g.vs.find("Dennis").degree()
3
顶点名称和ID之间的映射由igraph在后台透明地维护;每当图发生变化时,igraph也会更新内部映射。然而,顶点名称的唯一性不被强制执行;你可以轻松创建一个图,其中两个顶点具有相同的名称,但当你通过名称查找它们时,igraph只会返回其中一个,另一个只能通过其索引访问。
将图视为邻接矩阵
邻接矩阵是形成图的另一种方式。在邻接矩阵中,行和列由图的顶点标记:矩阵的元素表示顶点i和j是否有一条共同的边(i, j)。 示例图的邻接矩阵为
>>> g.get_adjacency()
Matrix([
[0, 1, 1, 0, 0, 1, 0],
[1, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 1, 1, 1, 0],
[0, 0, 1, 0, 1, 0, 1],
[0, 0, 1, 1, 0, 0, 0],
[1, 0, 1, 0, 0, 0, 1],
[0, 0, 0, 1, 0, 1, 0]
])
例如,Claire ([1, 0, 0, 1, 1, 1, 0]) 直接连接到 Alice(顶点索引为 0)、Dennis(索引为 3)、Esther(索引为 4)和 Frank(索引为 5),但不连接到 Bob(索引为 1)或 George(索引为 6)。
布局和绘图
图是一种抽象的数学对象,没有在2D或3D空间中的特定表示。这意味着每当我们想要可视化一个图时,我们首先必须找到从顶点到二维或三维空间坐标的映射,最好是以一种视觉上令人愉悦的方式。图论的一个独立分支,即图绘制,试图通过几种图布局算法来解决这个问题。igraph实现了相当多的布局算法,并且还能够使用Cairo库将它们绘制到屏幕上或保存为PDF、PNG或SVG文件。
重要
要跟随本小节的示例,您需要Cairo库的Python绑定或matplotlib(取决于选择的后端)。前一章(安装igraph)详细介绍了如何安装Cairo的Python绑定。
布局算法
igraph 中的布局方法可以在 Graph 对象中找到,它们总是以 layout_ 开头。下表总结了这些方法:
方法名称 |
简称 |
算法描述 |
|---|---|---|
|
|
确定性布局,将顶点放置在圆上 |
|
|
Davidson-Harel 模拟退火算法 |
|
|
用于大型图的分布式递归布局算法 |
|
|
Fruchterman-Reingold 力导向算法 |
|
|
Fruchterman-Reingold 力导向算法 在三维空间中 |
|
|
用于大型图的GraphOpt算法 |
|
|
常规网格布局 |
|
|
Kamada-Kawai 力导向算法 |
|
|
Kamada-Kawai力导向算法 在三维空间中 |
|
|
用于大型图的大型图布局算法 |
|
|
多维缩放布局 |
|
|
将顶点完全随机放置 |
|
|
将顶点完全随机地放置在3D空间中 |
|
|
Reingold-Tilford 树布局,适用于 (几乎)树状图 |
|
|
Reingold-Tilford 树布局,带有极坐标后变换,适用于(几乎)树状图 |
|
|
确定性布局,将顶点均匀地放置在球体表面 |
布局算法可以直接调用,也可以使用称为layout()的通用布局方法:
>>> layout = g.layout_kamada_kawai()
>>> layout = g.layout("kamada_kawai")
layout() 方法的第一个参数必须是布局算法的简称(参见上表)。所有剩余的位置参数和关键字参数都会原封不动地传递给所选的布局方法。例如,以下两个调用是完全等价的:
>>> layout = g.layout_reingold_tilford(root=[2])
>>> layout = g.layout("rt", root=[2])
布局方法返回一个Layout对象,其行为大多类似于列表的列表。
Layout对象中的每个列表条目对应于原始图中的一个顶点,
并包含该顶点在2D或3D空间中的坐标。Layout对象还
包含一些有用的方法,可以批量平移、缩放或旋转坐标。
然而,Layout对象的主要用途是你可以将它们传递给
plot()函数,与图一起使用,以获得2D绘图。
使用布局绘制图形
例如,我们可以使用Kamada-Kawai布局算法绘制我们的虚构社交网络,如下所示:
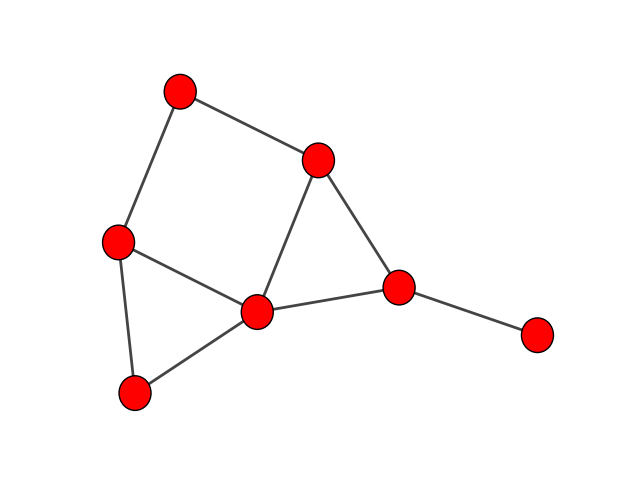
>>> layout = g.layout("kk")
>>> ig.plot(g, layout=layout)
这应该会打开一个外部图像查看器,显示网络的视觉表示, 类似于下图中的那个(尽管节点的确切位置可能因布局不是确定性的而在您的机器上有所不同):

使用Kamada-Kawai布局算法的我们的社交网络
如果您更喜欢使用 matplotlib 作为绘图引擎,请创建一个轴并使用
target 参数:
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots()
>>> ig.plot(g, layout=layout, target=ax)
注意
在绘制有根树时,Cairo 自动将根放在图像的顶部,叶子放在底部。对于 matplotlib,根通常位于底部。你可以通过调用 ax.invert_yaxis() 轻松将根放在顶部。
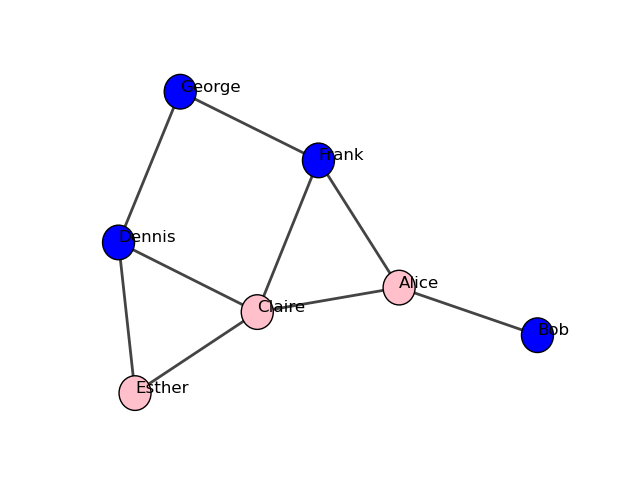
嗯,到目前为止这看起来不太美观。一个简单的改进是使用名称作为顶点标签,并根据性别为顶点着色。默认情况下,顶点标签取自 label 属性,顶点颜色由 color 属性决定,因此我们可以简单地创建这些属性并重新绘制图形:
>>> g.vs["label"] = g.vs["name"]
>>> color_dict = {"m": "blue", "f": "pink"}
>>> g.vs["color"] = [color_dict[gender] for gender in g.vs["gender"]]
>>> ig.plot(g, layout=layout, bbox=(300, 300), margin=20) # Cairo backend
>>> ig.plot(g, layout=layout, target=ax) # matplotlib backend
请注意,我们在这里只是重复使用了之前的布局对象,但对于Cairo后端,我们还指定了需要一个更小的绘图(300 x 300像素)以及更大的边距以适应标签(20像素)。这些设置对于Matplotlib后端将被忽略。结果是:

我们的社交网络 - 以名字为标签,性别为颜色
对于matplotlib:
我们的社交网络 - 以名字为标签,性别为颜色
除了将视觉属性指定为顶点和边属性外,您还可以将它们作为关键字参数传递给 plot():
>>> color_dict = {"m": "blue", "f": "pink"}
>>> ig.plot(g, layout=layout, vertex_color=[color_dict[gender] for gender in g.vs["gender"]])
如果您希望将图形的视觉表示属性与图形本身分开,则推荐使用后一种方法。您可以简单地设置一个包含您将传递给plot()的关键字参数的Python字典,然后使用双星号(**)运算符将您的特定样式属性传递给plot():
>>> visual_style = {}
>>> visual_style["vertex_size"] = 20
>>> visual_style["vertex_color"] = [color_dict[gender] for gender in g.vs["gender"]]
>>> visual_style["vertex_label"] = g.vs["name"]
>>> visual_style["edge_width"] = [1 + 2 * int(is_formal) for is_formal in g.es["is_formal"]]
>>> visual_style["layout"] = layout
>>> visual_style["bbox"] = (300, 300)
>>> visual_style["margin"] = 20
>>> ig.plot(g, **visual_style)
最终的图表用粗线显示正式关系,用细线显示非正式关系:
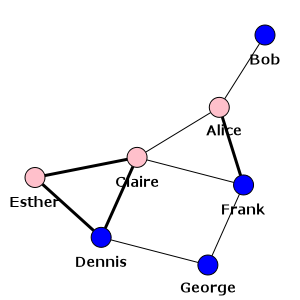
我们的社交网络 - 同时展示哪些关系是正式的
总结一下:有一些特殊的顶点和边属性对应于图的可视化表示。这些属性会覆盖igraph的默认设置(参见配置以覆盖系统范围的默认设置)。此外,提供给plot()的适当关键字参数会覆盖由顶点和边属性提供的视觉属性。以下两个表格分别总结了最常用的顶点和边的视觉属性:
控制图形绘制的顶点属性
属性名称 |
关键字参数 |
用途 |
|---|---|---|
|
|
顶点的颜色 |
|
|
顶点的字体家族 |
|
|
顶点的标签 |
|
|
顶点标签在顶点周围圆圈上的位置。这是一个以弧度表示的角度,零度属于顶点的右侧。 |
|
|
顶点标签的颜色 |
|
|
顶点标签与顶点本身的距离,相对于顶点大小 |
|
|
顶点标签的字体大小 |
|
|
顶点的绘制顺序。具有较小顺序参数的顶点将首先绘制。 |
|
|
顶点的形状。已知的形状有:
|
|
|
顶点的大小(以像素为单位) |
控制图形绘制的边属性
属性名称 |
关键字参数 |
用途 |
|---|---|---|
|
|
边的颜色 |
|
|
边的曲率。正值对应于逆时针方向弯曲的边,负值对应于顺时针方向弯曲的边。零表示直线边。 |
|
|
边的字体家族 |
|
|
如果图是有向的,边缘上箭头的尺寸(长度)相对于15像素。 |
|
|
如果图是有向的,边缘上箭头的宽度相对于10像素。 |
|
|
自环的大小。它可以设置为一个负数,在这种情况下,它会随着相应顶点的大小缩放(例如,-1.0 表示环的大小与顶点相同)。此属性对于非环的边将被忽略。此属性仅在 matplotlib 后端中可用。 |
|
|
边缘的宽度,以像素为单位。 |
|
|
如果指定,它将为边添加一个标签。 |
|
|
如果指定,它会在边缘标签周围添加一个矩形框,颜色为指定颜色(仅限matplotlib)。 |
|
|
如果为True,旋转边缘标签使其与边缘方向对齐。将会翻转的标签(仅限matplotlib)。 |
plot()的通用关键字参数
这些设置可以作为关键字参数指定给 plot() 函数,以控制图表的整体外观。
关键字参数 |
用途 |
|---|---|
|
是否在具有多条边的图中自动确定边的曲率。默认情况下,对于边数少于10,000的图,该值为 |
|
绘图的边界框。这必须是一个包含绘图所需宽度和高度的元组。默认绘图宽度为600像素,高度为600像素。对于Matplotlib后端忽略。 |
|
要使用的布局。它可以是一个
|
|
图表的上、右、下和左边距,以像素为单位。 此参数必须是一个列表或元组,如果你指定的列表或元组少于四个元素, 其元素将被重复使用。对于Matplotlib后端,此参数将被忽略。 |
在图表中指定颜色
igraph 在需要颜色时(例如,在相应的属性中设置边、顶点或标签颜色)可以理解以下颜色规范:
- X11 color names
请参阅X11颜色名称列表在维基百科上的完整列表。或者,您可以查看
igraph.drawing.colors.known_colors字典的键。在igraph中,颜色名称不区分大小写,因此"DarkBlue"也可以写成"darkblue"。- Color specification in CSS syntax
这是一个字符串,符合以下格式之一(其中R、G和B分别表示红色、绿色和蓝色分量):
#RRGGBB,组件以十六进制格式从0到255。 示例:"#0088ff"。#RGB,组件以十六进制格式从0到15。示例:"#08f"。rgb(R, G, B),组件的范围从0到255或从0%到100%。示例:"rgb(0, 127, 255)"或"rgb(0%, 50%, 100%)"。
- Lists or tuples of RGB values in the range 0-1
示例:
(1.0, 0.5, 0)或[1.0, 0.5, 0]。
请注意,当为所有顶点或边指定相同的颜色时,可以直接使用字符串,但不能使用元组或列表语法,因为元组或列表会被解释为元组中的项是针对单个顶点或边的。因此,以下代码是有效的:
>>> ig.plot(g, vertex_color="green")
但这不会,因为它会将元组中的项目视为第一个、第二个和第三个顶点的调色板索引:
>>> ig.plot(g, vertex_color=(1, 0, 0))
在后一种情况下,您需要为每个顶点显式扩展颜色规范:
>>> ig.plot(g, vertex_color=[(1, 0, 0)] * g.vcount())
保存图表
igraph 可以通过调用 plot() 函数将图形保存到文件中而不是显示在屏幕上,从而用于创建出版质量的图形。这可以通过在图形本身之后传递目标文件名作为附加参数来简单地完成。首选格式是从文件扩展名推断出来的。igraph 可以保存为 Cairo 支持的任何格式,包括 SVG、PDF 和 PNG 文件。如果你更喜欢,SVG 或 PDF 文件可以稍后转换为 PostScript (.ps) 或 Encapsulated PostScript (.eps) 格式,而 PNG 文件可以转换为 TIF (.tif):
>>> ig.plot(g, "social_network.pdf", **visual_style)
如果您正在使用matplotlib后端,您可以像往常一样保存您的图表:
>>> fig, ax = plt.subplots()
>>> ig.plot(g, **visual_style)
>>> fig.savefig("social_network.pdf")
matplotlib支持多种文件格式。
igraph 与外部世界
没有某种导入/导出功能的图模块是不完整的,这使得包能够与外部程序和工具包进行通信。igraph也不例外:它提供了读取最常见图格式并将Graph对象保存为符合这些格式规范的文件的功能。下表总结了igraph可以读取或写入的格式:
格式 |
简称 |
读取方法 |
写入方法 |
|---|---|---|---|
邻接表 |
|
|
|
(又名 LGL) |
|||
邻接矩阵 |
|
||
DIMACS |
|
||
DL |
|
|
尚未支持 |
边列表 |
|
|
|
|
尚未支持 |
|
|
GML |
|
|
|
GraphML |
|
|
|
Gzipped GraphML |
|
||
LEDA |
|
尚未支持 |
|
带标签的边列表 |
|
|
|
(也称为 NCOL) |
|||
Pajek 格式 |
|
|
|
腌制的图形 |
|
作为练习,请从此文件下载著名的Zachary空手道俱乐部研究的图表示,解压并尝试将其加载到igraph中。由于它是一个GraphML文件,你必须使用上表中的GraphML读取器方法(确保使用下载文件的正确路径):
>>> karate = ig.Graph.Read_GraphML("zachary.graphml")
>>> ig.summary(karate)
IGRAPH UNW- 34 78 -- Zachary's karate club network
如果你想将同一个图转换为Pajek格式,你可以使用上表中的Pajek写入方法:
>>> karate.write_pajek("zachary.net")
注意
大多数格式都有其自身的限制;例如,并非所有格式都能存储属性。如果您想以可以从外部包读取的格式保存igraph图,并且希望保留数字和字符串属性,那么GraphML或GML可能是您的最佳选择。如果您没有属性(尽管NCOL支持顶点名称和边权重),边列表和NCOL也可以。如果您不想在igraph之外使用您的图,但希望为以后的会话存储它们,pickled图格式确保您可以完全恢复相同的图。pickled图格式使用Python的pickle模块来存储和读取图。
还有两个辅助方法:read() 是一个通用的读取方法入口点,它尝试从文件扩展名推断出适当的格式。
Graph.write() 是 read() 的相反操作:它允许你保存一个图,其中首选格式再次从扩展名推断。
read() 和 Graph.write() 的格式检测可以通过 format 关键字参数覆盖,该参数接受上表中格式的短名称:
>>> karate = ig.load("zachary.graphml")
>>> karate.write("zachary.net")
>>> karate.write("zachary.my_extension", format="gml")
下一步去哪里
本教程仅触及了igraph功能的表面。我的长期计划是在接下来的章节中将本教程扩展为igraph的正式手册式文档。同时,请查看API参考,它应该提供关于几乎所有igraph类、函数或方法的信息。一个好的起点是Graph类的文档。如果你遇到困难,首先尝试在我们的Discourse群组中提问——也许有人能立即帮助你。