为什么使用Instructor?¶
这是来自作者Jason Liu的一封信。我是Pydantic的忠实粉丝,我认为它是处理Python数据验证的最佳方式。我已经使用它多年了,我很高兴将它引入OpenAI API。
Why use Pydantic?
很难回答为什么使用Instructor的问题,而不先回答为什么使用Pydantic。:
-
由类型提示驱动 — 使用Pydantic,模式验证和序列化由类型注释控制;需要学习的内容更少,编写的代码更少,并且与您的IDE和静态分析工具集成。
-
速度 — Pydantic的核心验证逻辑是用Rust编写的。因此,Pydantic是Python中最快的数据验证库之一。
-
JSON Schema — Pydantic 模型可以生成 JSON Schema,便于与其他工具集成。[了解更多…]
-
自定义 — Pydantic 允许自定义验证器和序列化器,以多种强大的方式改变数据的处理方式。
-
生态系统 — 在PyPI上大约有8,000个包使用Pydantic,包括非常流行的库如FastAPI、huggingface、Django Ninja、SQLModel和LangChain。
-
经过实战检验 — Pydantic 每月下载量超过 7000 万次,所有 FAANG 公司以及 NASDAQ 25 家最大公司中的 20 家都在使用。如果你正在尝试用 Pydantic 做某事,很可能已经有人做过了。
没有新标准¶
Instructor 构建在 Pydantic 和 OpenAI 之上,这对许多开发者来说已经很熟悉了。但是,由于许多 LLM 提供商支持 OpenAI API 规范,您可以使用许多闭源和开源提供商,如 Anyscale、Together、Groq、Ollama 和 Llama-cpp-python。
我们所做的只是增强create,以便
查看我们如何与开源连接
Pydantic 优于原始模式¶
我发现许多提示构建工具过于复杂且难以使用,它们可能在处理简单示例时容易上手,但一旦你需要更多控制,你就会希望它们能更简单。Instructor 以最少的工作量完成任务。
Pydantic 更具可读性,定义和参考值会自动处理。这对 Instructor 来说是一个巨大的优势,因为它使我们能够专注于数据提取而不是模式。
from typing import List, Literal
from pydantic import BaseModel, Field
class Property(BaseModel):
name: str = Field(description="name of property in snake case")
value: str
class Character(BaseModel):
"""
Any character in a fictional story
"""
name: str
age: int
properties: List[Property]
role: Literal['protagonist', 'antagonist', 'supporting']
class AllCharacters(BaseModel):
characters: List[Character] = Field(description="A list of all characters in the story")
你会更喜欢进行代码审查吗?在这里,所有内容都是字符串,容易出现拼写错误和引用错误?我知道我不会。
var = {
"$defs": {
"Character": {
"description": "Any character in a fictional story",
"properties": {
"name": {"title": "Name", "type": "string"},
"age": {"title": "Age", "type": "integer"},
"properties": {
"type": "array",
"items": {"$ref": "#/$defs/Property"},
"title": "Properties",
},
"role": {
"enum": ["protagonist", "antagonist", "supporting"],
"title": "Role",
"type": "string",
},
},
"required": ["name", "age", "properties", "role"],
"title": "Character",
"type": "object",
},
"Property": {
"properties": {
"name": {
"description": "name of property in snake case",
"title": "Name",
"type": "string",
},
"value": {"title": "Value", "type": "string"},
},
"required": ["name", "value"],
"title": "Property",
"type": "object",
},
},
"properties": {
"characters": {
"description": "A list of all characters in the story",
"items": {"$ref": "#/$defs/Character"},
"title": "Characters",
"type": "array",
}
},
"required": ["characters"],
"title": "AllCharacters",
"type": "object",
}
易于尝试和安装¶
最小可行的API只需向客户端添加response_model,如果你认为不需要模型,很容易将其移除并继续构建你的应用程序。
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Patch the OpenAI client with Instructor
client = instructor.from_openai(OpenAI())
class UserDetail(BaseModel):
name: str
age: int
# Function to extract user details
def extract_user() -> UserDetail:
user = client.chat.completions.create(
model="gpt-4-turbo-preview",
response_model=UserDetail,
messages=[
{"role": "user", "content": "Extract Jason is 25 years old"},
]
)
return user
import openai
import json
def extract_user() -> dict:
completion = client.chat.completions.create(
model="gpt-4-turbo-preview",
tools=[
{
"type": "function",
"function": {
"name": "ExtractUser",
"description": "Correctly extracted `ExtractUser` with all the required parameters with correct types",
"parameters": {
"properties": {
"name": {"title": "Name", "type": "string"},
"age": {"title": "Age", "type": "integer"},
},
"required": ["age", "name"],
"type": "object",
},
},
}
],
tool_choice={"type": "function", "function": {"name": "ExtractUser"}},
messages=[
{"role": "user", "content": "Extract Jason is 25 years old"},
],
) # type: ignore
user = json_loads(completion.choices[0].message.tool_calls[0].function.arguments)
assert "name" in user, "Name is not in the response"
assert "age" in user, "Age is not in the response"
user["age"] = int(user["age"])
return user
部分提取¶
我们还支持部分提取,这对于流式传输不完整的数据非常有用。
import instructor
from instructor import Partial
from openai import OpenAI
from pydantic import BaseModel
from typing import List
from rich.console import Console
client = instructor.from_openai(OpenAI())
text_block = "..."
class User(BaseModel):
name: str
email: str
twitter: str
class MeetingInfo(BaseModel):
users: List[User]
date: str
location: str
budget: int
deadline: str
extraction_stream = client.chat.completions.create(
model="gpt-4",
response_model=Partial[MeetingInfo],
messages=[
{
"role": "user",
"content": f"Get the information about the meeting and the users {text_block}",
},
],
stream=True,
)
console = Console()
for extraction in extraction_stream:
obj = extraction.model_dump()
console.clear()
console.print(obj)
这将输出以下内容:
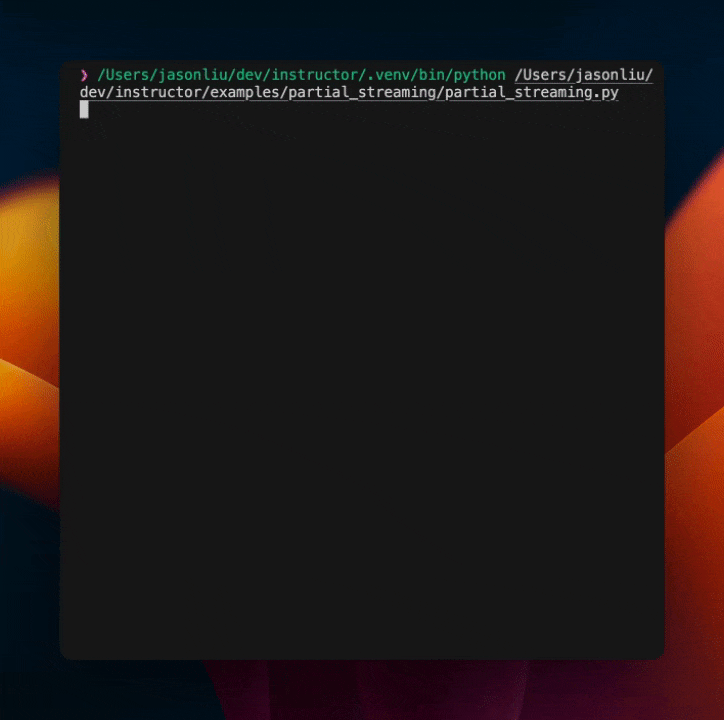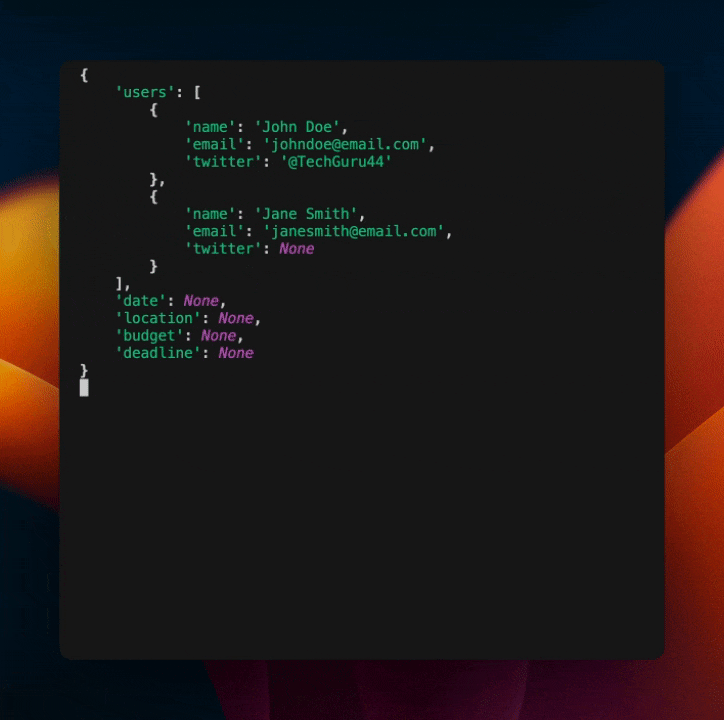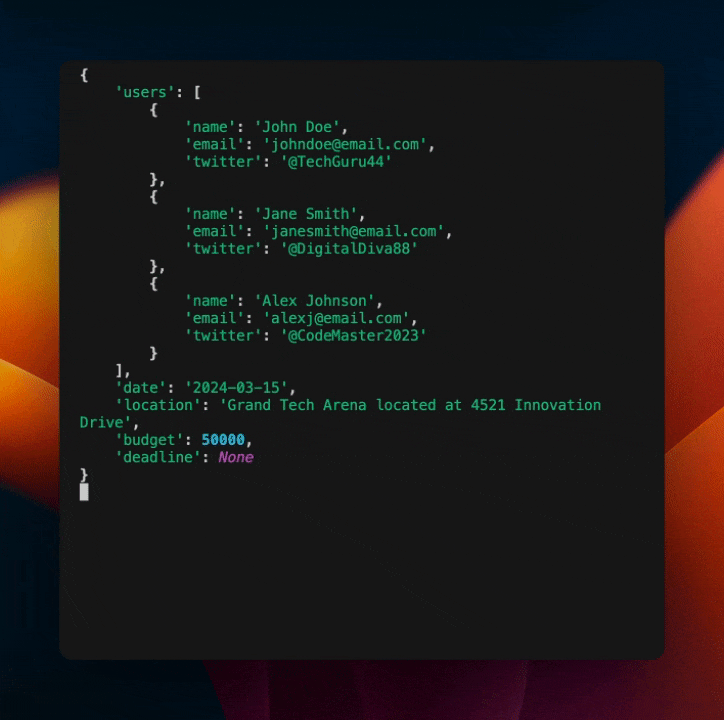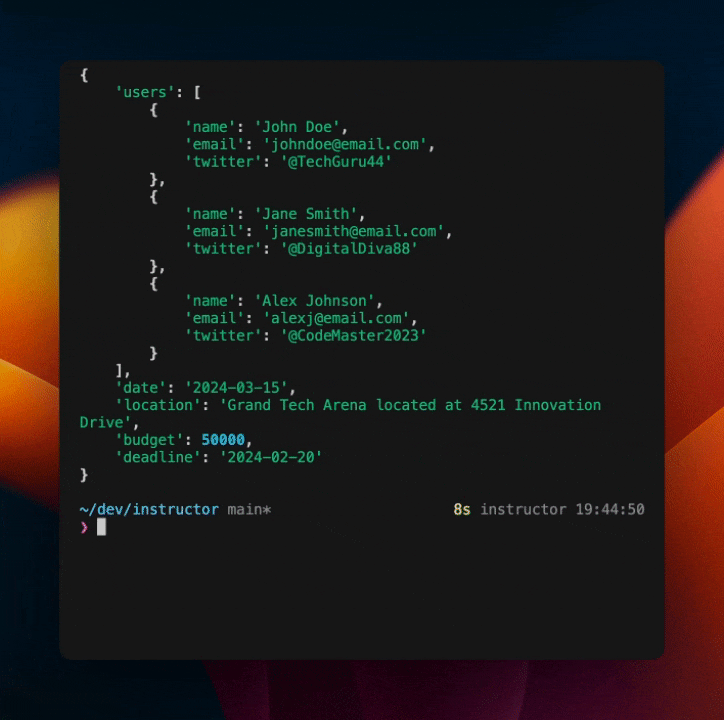
正如你所见,我们已经在模型中内置了一个自我纠正机制。这是一种强大的方法,可以使你的模型更加健壮和不易崩溃,而无需包含大量额外的代码或提示。
可迭代对象和列表¶
我们还可以通过定义一个Iterable[T]类型来在令牌流式传输时生成任务。
让我们看一个实际操作的例子,使用相同的类
from typing import Iterable
Users = Iterable[User]
users = client.chat.completions.create(
model="gpt-4",
temperature=0.1,
stream=True,
response_model=Users,
messages=[
{
"role": "system",
"content": "You are a perfect entity extraction system",
},
{
"role": "user",
"content": (
f"Consider the data below:\n{input}"
"Correctly segment it into entitites"
"Make sure the JSON is correct"
),
},
],
max_tokens=1000,
)
for user in users:
assert isinstance(user, User)
print(user)
#> name="Jason" "age"=10
#> name="John" "age"=10
简单类型¶
我们还支持简单类型,这对于提取数字、字符串和布尔值等简单值非常有用。
验证错误时的自我纠正¶
由于pydantic自身的验证模型,可以轻松地向模型添加验证器以纠正数据。如果我们运行此代码,将会得到一个验证错误,因为名称不是大写的。虽然我们可以包含一个提示来修复此问题,但我们也可以向模型添加一个字段验证器。这将导致两次API调用,以确保在添加验证器之前尽最大努力进行提示。
import instructor
from openai import OpenAI
from pydantic import BaseModel, field_validator
# Apply the patch to the OpenAI client
client = instructor.from_openai(OpenAI())
class UserDetails(BaseModel):
name: str
age: int
@field_validator("name")
@classmethod
def validate_name(cls, v):
if v.upper() != v:
raise ValueError("Name must be in uppercase.")
return v
model = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=UserDetails,
max_retries=2,
messages=[
{"role": "user", "content": "Extract jason is 25 years old"},
],
)
assert model.name == "JASON"