近似最近邻(ANN)索引
ANN(近似最近邻)或向量索引是一种专门设计的数据结构,旨在通过选定的距离度量高效组织和搜索基于相似度的向量数据。通过构建向量索引,可以有效地缩小搜索范围,避免对整个向量空间进行暴力扫描。相比穷举搜索(kNN或平面搜索),向量索引速度更快但准确性稍低。LanceDB提供了许多参数来微调索引大小、查询速度和结果准确性。
基于磁盘的索引
Lance提供了一种基于磁盘的IVF_PQ索引。它首先使用倒排文件索引(IVF)将数据集划分为N个分区,然后应用乘积量化来压缩每个分区中的向量。有关其工作原理的更多信息,请参阅索引概念指南。
创建IVF_PQ索引
Lance默认支持IVF_PQ索引类型。
创建索引是通过create_index方法完成的。
import lancedb
import numpy as np
uri = "data/sample-lancedb"
# Create 5,000 sample vectors
data = [
{"vector": row, "item": f"item {i}"}
for i, row in enumerate(np.random.random((5_000, 32)).astype("float32"))
]
db = lancedb.connect(uri)
# Add the vectors to a table
tbl = db.create_table("my_vectors", data=data)
# Create and train the index - you need to have enough data in the table
# for an effective training step
tbl.create_index(num_partitions=2, num_sub_vectors=4)
创建索引是通过create_index方法完成的。
import lancedb
import numpy as np
from lancedb.index import IvfPq
uri = "data/sample-lancedb"
# Create 5,000 sample vectors
data = [
{"vector": row, "item": f"item {i}"}
for i, row in enumerate(np.random.random((5_000, 32)).astype("float32"))
]
async_db = await lancedb.connect_async(uri)
# Add the vectors to a table
async_tbl = await async_db.create_table("my_vectors_async", data=data)
# Create and train the index - you need to have enough data in the table
# for an effective training step
await async_tbl.create_index(
"vector", config=IvfPq(num_partitions=2, num_sub_vectors=4)
)
创建索引是通过lancedb.Table.createIndex方法完成的。
import * as lancedb from "@lancedb/lancedb";
import type { VectorQuery } from "@lancedb/lancedb";
const db = await lancedb.connect(databaseDir);
const data = Array.from({ length: 5_000 }, (_, i) => ({
vector: Array(128).fill(i),
id: `${i}`,
content: "",
longId: `${i}`,
}));
const table = await db.createTable("my_vectors", data, {
mode: "overwrite",
});
await table.createIndex("vector", {
config: lancedb.Index.ivfPq({
numPartitions: 10,
numSubVectors: 16,
}),
});
创建索引是通过lancedb.Table.createIndex方法完成的。
import * as vectordb from "vectordb";
const db = await vectordb.connect("data/sample-lancedb");
let data = [];
for (let i = 0; i < 10_000; i++) {
data.push({
vector: Array(1536).fill(i),
id: `${i}`,
content: "",
longId: `${i}`,
});
}
const table = await db.createTable("my_vectors", data);
await table.createIndex({
type: "ivf_pq",
column: "vector",
num_partitions: 16,
num_sub_vectors: 48,
});
// For this example, `table` is a lancedb::Table with a column named
// "vector" that is a vector column with dimension 128.
// By default, if the column "vector" appears to be a vector column,
// then an IVF_PQ index with reasonable defaults is created.
table
.create_index(&["vector"], Index::Auto)
.execute()
.await?;
// For advanced cases, it is also possible to specifically request an
// IVF_PQ index and provide custom parameters.
table
.create_index(
&["vector"],
Index::IvfPq(
// Here we specify advanced indexing parameters. In this case
// we are creating an index that my have better recall than the
// default but is also larger and slower.
IvfPqIndexBuilder::default()
// This overrides the default distance type of l2
.distance_type(DistanceType::Cosine)
// With 1000 rows this have been ~31 by default
.num_partitions(50)
// With dimension 128 this would have been 8 by default
.num_sub_vectors(16),
),
)
.execute()
.await?;
IVF_PQ索引参数在crate文档中有更完整的定义。
可以指定以下IVF_PQ参数:
- distance_type: 使用的距离度量方式。默认使用欧几里得距离"
l2"。 我们还支持"cosine"(余弦)和"dot"(点积)距离。 - num_partitions: 索引中的分区数量。默认值为行数的平方根。
注意
在同步Python SDK和Node的vectordb中,默认值为256。这个默认值在异步Python SDK和Node的lancedb中已更改。
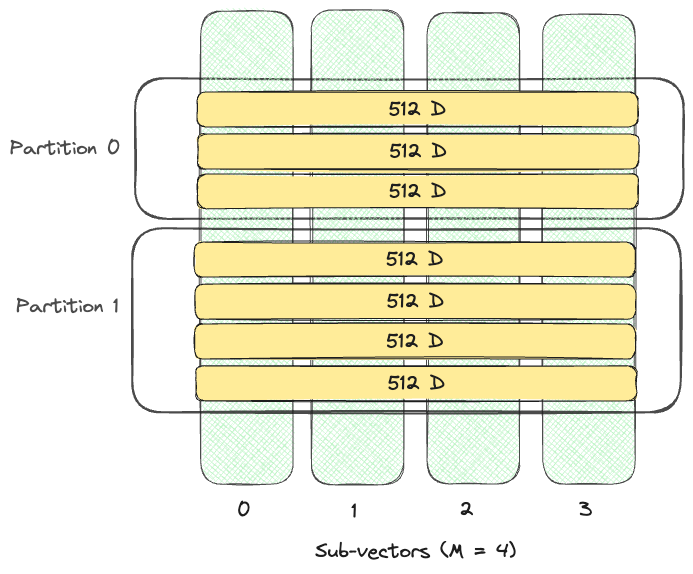
- num_sub_vectors: 在乘积量化(PQ)过程中将创建的子向量数量(M)。
对于D维向量,它将被划分为
M个维度为D/M的子向量,每个子向量将被替换为单个PQ编码。默认值为向量维度除以16。 - num_bits: 用于编码每个子向量的位数。仅支持4和8。位数越高,索引的准确性越高,但搜索速度也越慢。默认值为8。
注意
在同步Python SDK和Node的vectordb中,当前默认值为96。这个默认值在异步Python SDK和Node的lancedb中已更改。
num_partitions=2, num_sub_vectors=4使用GPU构建向量索引
Lance Python SDK 实验性地支持使用GPU创建IVF索引。 使用GPU创建索引需要安装PyTorch>2.0。
您可以通过以下方式指定用于训练IVF分区的GPU设备
- accelerator: 指定为
cuda或mps(在Apple Silicon上)以启用GPU训练。
注意
我们的异步客户端目前还不支持基于GPU的索引。
故障排除:
如果看到AssertionError: Torch not compiled with CUDA enabled错误,您需要安装支持CUDA的PyTorch。
查询ANN索引
查询向量索引是通过search函数完成的。
有几个参数可以用来微调搜索:
- limit (默认值: 10): 返回结果的数量
-
nprobes (默认值: 20): 使用的探测数量。数值越大搜索越精确但速度也越慢。
大多数情况下,将nprobes设置为覆盖数据集的5-15%即可在低延迟下实现高召回率。- 例如,对于一个包含100万向量并划分为256个分区的数据集,
nprobes应设置为约20-40。该值可进行调整,以实现搜索延迟和搜索质量之间的最佳平衡。
- 例如,对于一个包含100万向量并划分为256个分区的数据集,
-
refine_factor (默认值: None): 通过读取额外元素并在内存中重新排序来优化结果。
数值越高搜索越精确但也会更慢。如果发现召回率不理想,可以尝试从refine_factor=10开始调整。- 例如,对于一个包含100万向量并划分为256个分区的数据集,将
refine_factor设置为200会先从所有搜索分区中检索出前4,000个候选(top k * refine_factor)。这些候选结果随后会经过重新排序以确定最终的前20个结果。
- 例如,对于一个包含100万向量并划分为256个分区的数据集,将
注意
只有在存在ANN索引时,nprobes和refine_factor参数才适用。如果在没有ANN索引的表上指定这些参数,它们将被忽略。
let query_vector = [1.0; 128];
// By default the index will find the 10 closest results using default
// search parameters that give a reasonable tradeoff between accuracy
// and search latency
let mut results = table
.vector_search(&query_vector)?
// Note: you should always set the distance_type to match the value used
// to train the index
.distance_type(DistanceType::Cosine)
.execute()
.await?;
while let Some(batch) = results.try_next().await? {
println!("{:?}", batch);
}
// We can also provide custom search parameters. Here we perform a
// slower but more accurate search
let mut results = table
.vector_search(&query_vector)?
.distance_type(DistanceType::Cosine)
// Override the default of 10 to get more rows
.limit(15)
// Override the default of 20 to search more partitions
.nprobes(30)
// Override the default of None to apply a refine step
.refine_factor(1)
.execute()
.await?;
while let Some(batch) = results.try_next().await? {
println!("{:?}", batch);
}
Ok(())
向量搜索选项在crate文档中有更完整的定义。
搜索将返回请求的数据以及每个项目的距离。
筛选(where子句)
您可以使用where子句进一步筛选搜索返回的元素。
投影(select子句)
你可以使用select子句来选择查询返回的列。
常见问题解答
为什么需要手动创建索引?
目前,LanceDB 不会 自动创建ANN索引。 LanceDB针对基于磁盘索引的kNN(穷举搜索)进行了高度优化。对于许多用例来说, 约10万数量级的向量数据集无需创建索引。如果您能接受最高 100毫秒的延迟,跳过索引创建是一个更简单的工作流程,同时能保证100%的召回率。
何时需要创建ANN向量索引?
LanceDB 内置了高度优化的SIMD代码用于计算向量相似度。在我们的基准测试中,计算10万对1K维向量的距离耗时不到20毫秒。我们观察到对于小型数据集(约10万行)或可接受100毫秒延迟的应用场景,通常不需要使用向量索引。
对于大规模或高维向量,创建向量索引可以提升性能。
我的索引有多大,会占用多少内存?
在LanceDB中,所有向量索引都是基于磁盘的,这意味着在响应向量查询时,只会从磁盘加载索引文件中的相关页面并缓存在内存中。此外,每个子向量通常会被编码为1字节的PQ码。
例如,对于一个1024维的数据集,如果我们选择num_sub_vectors=64,每个子向量将包含1024 / 64 = 16个float32数值。
使用乘积量化可以实现约16 * sizeof(float32) / 1 = 64倍的空间压缩。
如何为IVF_PQ索引选择num_partitions和num_sub_vectors参数?
num_partitions 用于决定第一级 IVF 索引使用的分区数量。
分区数量越多,查询时的I/O效率可能更高,准确率也更好,但训练所需时间会大幅增加。
在 SIFT-1M 数据集上,我们的基准测试显示,保持每个分区4K-8K行数能获得较好的延迟/召回率平衡。
num_sub_vectors 指定每个向量上生成的产品量化(PQ)短码数量。该数值应为向量维度的因数。由于PQ是对原始向量的有损压缩,更高的num_sub_vectors通常会导致更小的空间失真,从而获得更好的精度。然而,更高的num_sub_vectors也会导致更重的I/O负担和更多的PQ计算,因此会增加延迟。dimension / num_sub_vectors应为8的倍数以获得最佳SIMD效率。
注意
如果num_sub_vectors设置的值大于向量维度,您将看到类似attempt to divide by zero的错误
如何为IVF_HNSW_*索引选择m和ef_construction参数?
m 决定新节点加入图时与其最近邻节点建立的连接数量。通常,m 的取值范围在5到48之间。较低的 m 值适用于低维数据或召回率要求不高的场景。相反,较高的 m 值有利于处理高维数据或需要高召回率的情况。本质上,较大的 m 会生成连接更紧密的稠密图,但代价是更高的内存消耗。
ef_construction 参数用于平衡构建速度与精度。数值越高精度越好但构建过程越慢,推荐取值范围为150至300。为保证搜索质量,建议最小值不低于100。多数情况下,将该值设为超过500并不会带来额外收益。请注意确保ef_construction的设定值始终大于或等于搜索阶段ef的参数值。