LanceDB
LanceDB是一个面向AI的开源向量数据库,专为存储、管理、查询和检索大规模多模态数据的嵌入向量而设计。LanceDB的核心采用Rust🦀编写,并构建在Lance之上——这是一种专为高性能机器学习工作负载和快速随机访问设计的开源列式数据格式。
数据库及其底层数据格式均从头设计,旨在实现易用性、可扩展性和成本效益。
托管式LanceDB
如果您希望兼顾S3的成本效益与本地性能,同时通过简单的无服务器API实现,请查看LanceDB Cloud。如需私有化部署、超大规模下的高性能方案,或有严格的安全合规要求,欢迎咨询我们的LanceDB Enterprise企业版。了解更多
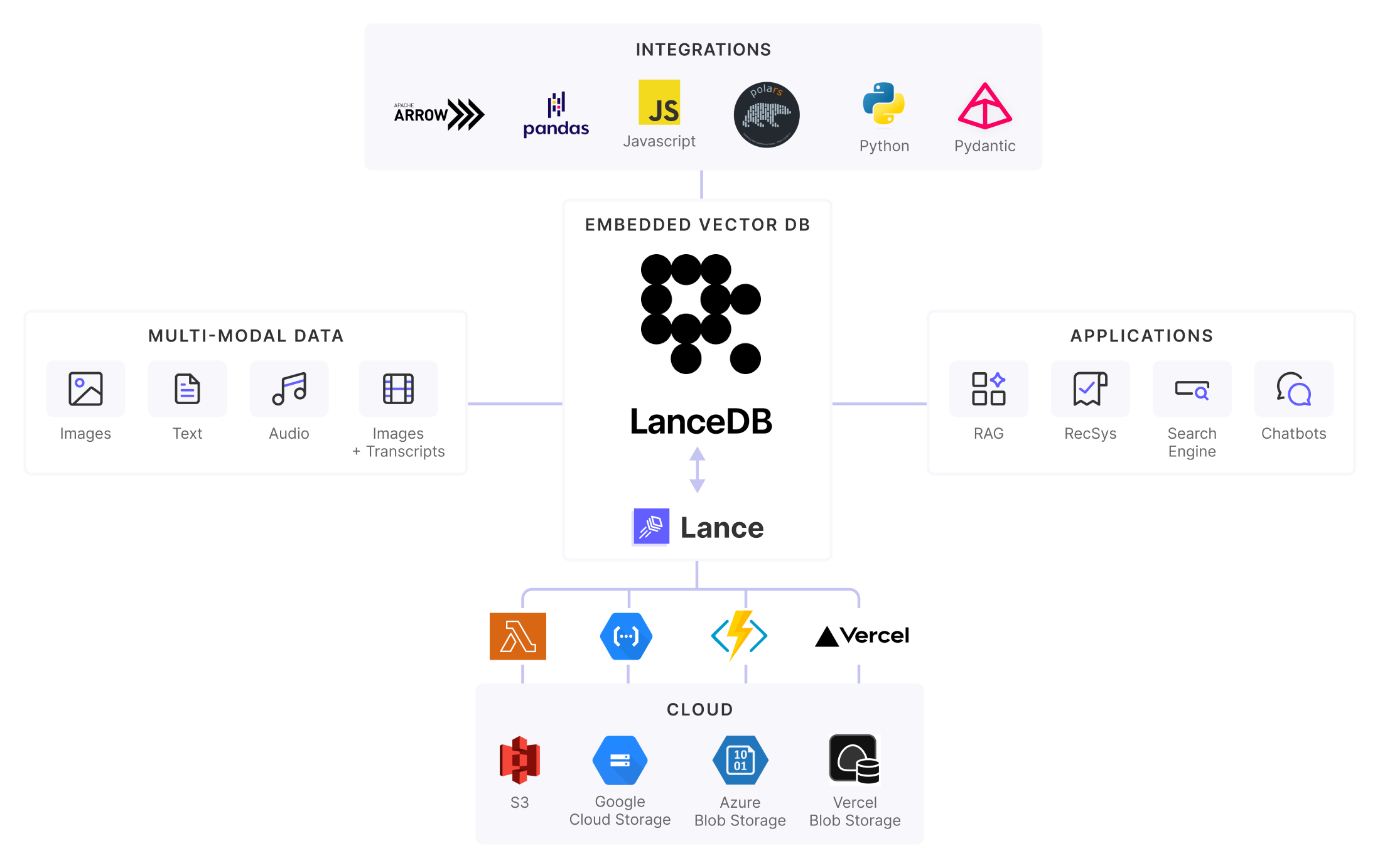
真正的多模态
大多数现有的向量数据库仅存储和查询嵌入向量及其元数据。实际数据存储在其他地方,需要您单独管理它们的存储和版本控制。
LanceDB支持存储实际数据本身,同时保存嵌入向量和元数据。您可以将图像、视频、文本文档、音频文件等以Lance格式持久化存储,该格式通过LanceDB提供自动数据版本控制以及极速检索和过滤功能。
开源与云端解决方案
LanceDB 提供两种版本:开源版和云服务版。
LanceDB OSS 是一个开源的、功能完备的嵌入式向量数据库,可在您自己的基础设施上运行。"嵌入式"意味着它以进程内方式运行,使得为RAG等AI检索工作流自托管变得极其简单。无需服务器,没有麻烦。
LanceDB Cloud 是一款SaaS(软件即服务)解决方案,在云端以无服务器方式运行,实现了存储与计算的明确分离。该方案旨在提供高性价比和高度可扩展性,同时不会造成高昂成本。LanceDB Cloud目前处于内测阶段,即将全面开放,但您可以通过下方注册申请内测版的早期访问权限。
为什么使用LanceDB?
-
嵌入式(开源)与无服务器(云服务) - 无需管理服务器
-
快速生产级向量相似度搜索、全文与混合搜索,以及通过DataFusion实现的SQL查询接口
-
支持Python、Javascript/Typescript和Rust
-
存储、查询和管理多模态数据(文本、图像、视频、点云等),而不仅仅是嵌入向量和元数据
-
与Arrow生态系统的紧密集成,支持在共享内存中实现真正的零拷贝访问,并利用SIMD和GPU加速
-
自动数据版本控制,无需额外基础设施即可管理数据版本
-
基于磁盘的索引和存储,实现大规模扩展而无需高昂成本
-
直接导入您喜爱的数据格式,如pandas DataFrames、Pydantic对象、Polars(即将推出)等
文档指南
以下页面深入探讨了LanceDB的内部原理及其使用方法。
- 快速入门: 开始使用LanceDB并了解向量数据库概念
- 向量搜索概念: 了解向量搜索的基础知识
- Working with tables: 学习如何操作表格及其相关功能
- Indexing: 了解如何创建索引
- 向量搜索: 了解如何进行向量相似性搜索
- 全文搜索(原生): 了解如何执行全文搜索
- 全文搜索(基于tantivy): 了解如何使用Tantivy执行全文搜索
- 管理嵌入向量: 在LanceDB中管理嵌入向量及嵌入函数API
- Ecosystem Integrations: 将LanceDB与数据生态系统中的其他工具集成
- Python API 参考文档: Python 开源版和云服务版API参考
- JavaScript API 参考文档: JavaScript OSS 和云 API 参考
- Rust API Reference: Rust API参考文档