向量搜索
向量搜索可以找到与给定查询向量近似或精确的最近邻。
- 在推荐系统或搜索引擎中,您可以找到与搜索记录相似的记录。
- 在LLM和其他AI应用中, 每个数据点都可以通过现有模型生成的嵌入向量来表示, 随后搜索会返回最相关的特征。
距离度量
距离度量是衡量一对向量之间相似性的指标。 目前,LanceDB支持以下度量方式:
| 指标 | 描述 |
|---|---|
l2 |
Euclidean / l2 distance |
cosine |
Cosine Similarity |
dot |
Dot Production |
hamming |
Hamming Distance |
注意
hamming 度量仅适用于二进制向量。
穷举搜索(k近邻算法)
如果不创建向量索引,LanceDB会彻底扫描整个向量空间,并计算与每个向量的距离以找到精确的最近邻。这实际上就是kNN搜索。
uri = "data/sample-lancedb"
async_db = await lancedb.connect_async(uri)
data = [
{"vector": row, "item": f"item {i}"}
for i, row in enumerate(np.random.random((10_000, 1536)).astype("float32"))
]
async_tbl = await async_db.create_table("vector_search_async", data=data)
(await (await async_tbl.search(np.random.random((1536)))).limit(10).to_list())
默认情况下,将使用l2作为度量类型。如果需要,您可以指定度量类型为cosine或dot。
近似最近邻(ANN)搜索
为了实现可扩展的向量检索并保持可接受的延迟,通常需要构建向量索引。 虽然穷举搜索能保证始终返回100%的召回率,但近似最近邻(ANN)搜索的特性意味着使用索引往往需要在召回率和延迟之间进行权衡。
查看IVF_PQ索引以深入了解IVF_PQ索引在LanceDB中的工作原理。
二进制向量
LanceDB支持二进制向量作为一种数据类型,并能够通过汉明距离搜索二进制向量。这些二进制向量以uint8数组的形式存储(每8位存储为一个字节):
注意
二进制向量的维度必须是8的倍数。一个128维的向量将被存储为一个大小为16的uint8数组。
import lancedb
import numpy as np
import pyarrow as pa
import pytest
db = lancedb.connect("data/binary_lancedb")
schema = pa.schema(
[
pa.field("id", pa.int64()),
# for dim=256, lance stores every 8 bits in a byte
# so the vector field should be a list of 256 / 8 = 32 bytes
pa.field("vector", pa.list_(pa.uint8(), 32)),
]
)
tbl = db.create_table("my_binary_vectors", schema=schema)
data = []
for i in range(1024):
vector = np.random.randint(0, 2, size=256)
# pack the binary vector into bytes to save space
packed_vector = np.packbits(vector)
data.append(
{
"id": i,
"vector": packed_vector,
}
)
tbl.add(data)
query = np.random.randint(0, 2, size=256)
packed_query = np.packbits(query)
tbl.search(packed_query).distance_type("hamming").to_arrow()
import lancedb
import numpy as np
import pyarrow as pa
import pytest
db = await lancedb.connect_async("data/binary_lancedb")
schema = pa.schema(
[
pa.field("id", pa.int64()),
# for dim=256, lance stores every 8 bits in a byte
# so the vector field should be a list of 256 / 8 = 32 bytes
pa.field("vector", pa.list_(pa.uint8(), 32)),
]
)
tbl = await db.create_table("my_binary_vectors", schema=schema)
data = []
for i in range(1024):
vector = np.random.randint(0, 2, size=256)
# pack the binary vector into bytes to save space
packed_vector = np.packbits(vector)
data.append(
{
"id": i,
"vector": packed_vector,
}
)
await tbl.add(data)
query = np.random.randint(0, 2, size=256)
packed_query = np.packbits(query)
await (await tbl.search(packed_query)).distance_type("hamming").to_arrow()
import * as lancedb from "@lancedb/lancedb";
import { Field, FixedSizeList, Int32, Schema, Uint8 } from "apache-arrow";
const schema = new Schema([
new Field("id", new Int32(), true),
new Field("vec", new FixedSizeList(32, new Field("item", new Uint8()))),
]);
const data = lancedb.makeArrowTable(
Array(1_000)
.fill(0)
.map((_, i) => ({
// the 256 bits would be store in 32 bytes,
// if your data is already in this format, you can skip the packBits step
id: i,
vec: lancedb.packBits(Array(256).fill(i % 2)),
})),
{ schema: schema },
);
const tbl = await db.createTable("binary_table", data);
await tbl.createIndex("vec", {
config: lancedb.Index.ivfFlat({
numPartitions: 10,
distanceType: "hamming",
}),
});
const query = Array(32)
.fill(1)
.map(() => Math.floor(Math.random() * 255));
const results = await tbl.query().nearestTo(query).limit(10).toArrow();
// --8<-- [end:search_binary_data
expect(results.numRows).toBe(10);
}
});
});
多向量类型
LanceDB支持多向量类型,当单个项目拥有多个向量时(例如使用ColBert和ColPali)这会非常有用。
您可以在多向量类型的列上建立索引并进行搜索,查询可以是单个向量或多个向量。如果查询是多向量mq,则它与数据集中任何多向量mv之间的相似度(距离)定义为:
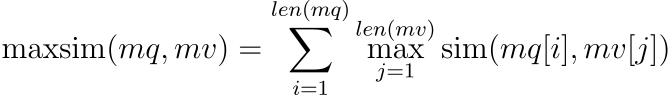
其中 sim 是相似度函数(例如余弦)。
目前,多向量搜索仅支持cosine度量方式。
向量值类型可以是float16、float32或float64。
import lancedb
import numpy as np
import pyarrow as pa
db = lancedb.connect("data/multivector_demo")
schema = pa.schema(
[
pa.field("id", pa.int64()),
# float16, float32, and float64 are supported
pa.field("vector", pa.list_(pa.list_(pa.float32(), 256))),
]
)
data = [
{
"id": i,
"vector": np.random.random(size=(2, 256)).tolist(),
}
for i in range(1024)
]
tbl = db.create_table("my_table", data=data, schema=schema)
# only cosine similarity is supported for multi-vectors
tbl.create_index(metric="cosine")
# query with single vector
query = np.random.random(256).astype(np.float16)
tbl.search(query).to_arrow()
# query with multiple vectors
query = np.random.random(size=(2, 256))
tbl.search(query).to_arrow()
import lancedb
import numpy as np
import pyarrow as pa
db = await lancedb.connect_async("data/multivector_demo")
schema = pa.schema(
[
pa.field("id", pa.int64()),
# float16, float32, and float64 are supported
pa.field("vector", pa.list_(pa.list_(pa.float32(), 256))),
]
)
data = [
{
"id": i,
"vector": np.random.random(size=(2, 256)).tolist(),
}
for i in range(1024)
]
tbl = await db.create_table("my_table", data=data, schema=schema)
# only cosine similarity is supported for multi-vectors
await tbl.create_index(column="vector", config=IvfPq(distance_type="cosine"))
# query with single vector
query = np.random.random(256)
await tbl.query().nearest_to(query).to_arrow()
# query with multiple vectors
query = np.random.random(size=(2, 256))
await tbl.query().nearest_to(query).to_arrow()
按距离范围搜索
您还可以搜索与查询向量在特定距离范围内的向量。当您不仅想找到最近的邻居向量,还想找到那些位于一定距离内的向量时,这非常有用。这可以通过使用distance_range方法来实现。
import lancedb
import numpy as np
db = lancedb.connect("data/distance_range_demo")
data = [
{
"id": i,
"vector": np.random.random(256),
}
for i in range(1024)
]
tbl = db.create_table("my_table", data=data)
query = np.random.random(256)
# Search for the vectors within the range of [0.1, 0.5)
tbl.search(query).distance_range(0.1, 0.5).to_arrow()
# Search for the vectors with the distance less than 0.5
tbl.search(query).distance_range(upper_bound=0.5).to_arrow()
# Search for the vectors with the distance greater or equal to 0.1
tbl.search(query).distance_range(lower_bound=0.1).to_arrow()
import lancedb
import numpy as np
db = await lancedb.connect_async("data/distance_range_demo")
data = [
{
"id": i,
"vector": np.random.random(256),
}
for i in range(1024)
]
tbl = await db.create_table("my_table", data=data)
query = np.random.random(256)
# Search for the vectors within the range of [0.1, 0.5)
await (await tbl.search(query)).distance_range(0.1, 0.5).to_arrow()
# Search for the vectors with the distance less than 0.5
await (await tbl.search(query)).distance_range(upper_bound=0.5).to_arrow()
# Search for the vectors with the distance greater or equal to 0.1
await (await tbl.search(query)).distance_range(lower_bound=0.1).to_arrow()
输出搜索结果
LanceDB 通过 Python 中常用的不同格式返回向量搜索结果。 让我们创建一个具有嵌套模式的 LanceDB 表:
from datetime import datetime
import lancedb
from lancedb.pydantic import Vector, LanceModel
from lancedb.query import BoostQuery, MatchQuery
import numpy as np
import pyarrow as pa
from pydantic import BaseModel
class Metadata(BaseModel):
source: str
timestamp: datetime
class Document(BaseModel):
content: str
meta: Metadata
class LanceSchema(LanceModel):
id: str
vector: Vector(1536)
payload: Document
# Let's add 100 sample rows to our dataset
data = [
LanceSchema(
id=f"id{i}",
vector=np.random.randn(1536),
payload=Document(
content=f"document{i}",
meta=Metadata(source=f"source{i % 10}", timestamp=datetime.now()),
),
)
for i in range(100)
]
# Synchronous client
tbl = db.create_table("documents", data=data)
from datetime import datetime
import lancedb
from lancedb.pydantic import Vector, LanceModel
from lancedb.query import BoostQuery, MatchQuery
import numpy as np
import pyarrow as pa
from pydantic import BaseModel
class Metadata(BaseModel):
source: str
timestamp: datetime
class Document(BaseModel):
content: str
meta: Metadata
class LanceSchema(LanceModel):
id: str
vector: Vector(1536)
payload: Document
# Let's add 100 sample rows to our dataset
data = [
LanceSchema(
id=f"id{i}",
vector=np.random.randn(1536),
payload=Document(
content=f"document{i}",
meta=Metadata(source=f"source{i % 10}", timestamp=datetime.now()),
),
)
for i in range(100)
]
async_tbl = await async_db.create_table("documents_async", data=data)
作为PyArrow表格
使用to_arrow()我们可以将结果以pyarrow表格形式返回。
这个结果表格与LanceDB表具有相同的列,并额外增加了用于向量搜索的_distance列或用于全文搜索的score列。
作为Pandas数据框
你也可以将结果获取为pandas数据框。
虽然其他格式如Arrow/Pydantic/Python字典有处理嵌套模式的天然方式,但pandas只能将嵌套数据存储为Python字典列,这使得支持嵌套引用变得困难。因此为了方便起见,您也可以告诉LanceDB在创建pandas数据框时展平嵌套模式。
如果您的表包含深层嵌套结构,可以通过传入一个正整数来控制要展开的嵌套层级数。
注意
flatten 在我们的异步客户端中尚不支持。
作为Python字典列表
当然,您也可以将结果作为Python字典列表返回。
作为Pydantic模型列表
我们可以使用Pydantic模型添加数据,当然也可以将检索结果作为Pydantic模型返回
注意
to_pydantic() 目前在我们的异步客户端中还不支持。
请注意,在这种情况下,额外的_distance字段会被丢弃,因为它不属于LanceSchema的一部分。