import math
import numpy as np
from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
from neuralforecast.common._modules import DataEmbedding, SeriesDecomp
from neuralforecast.common._base_windows import BaseWindows
from neuralforecast.losses.pytorch import MAE自动转换器
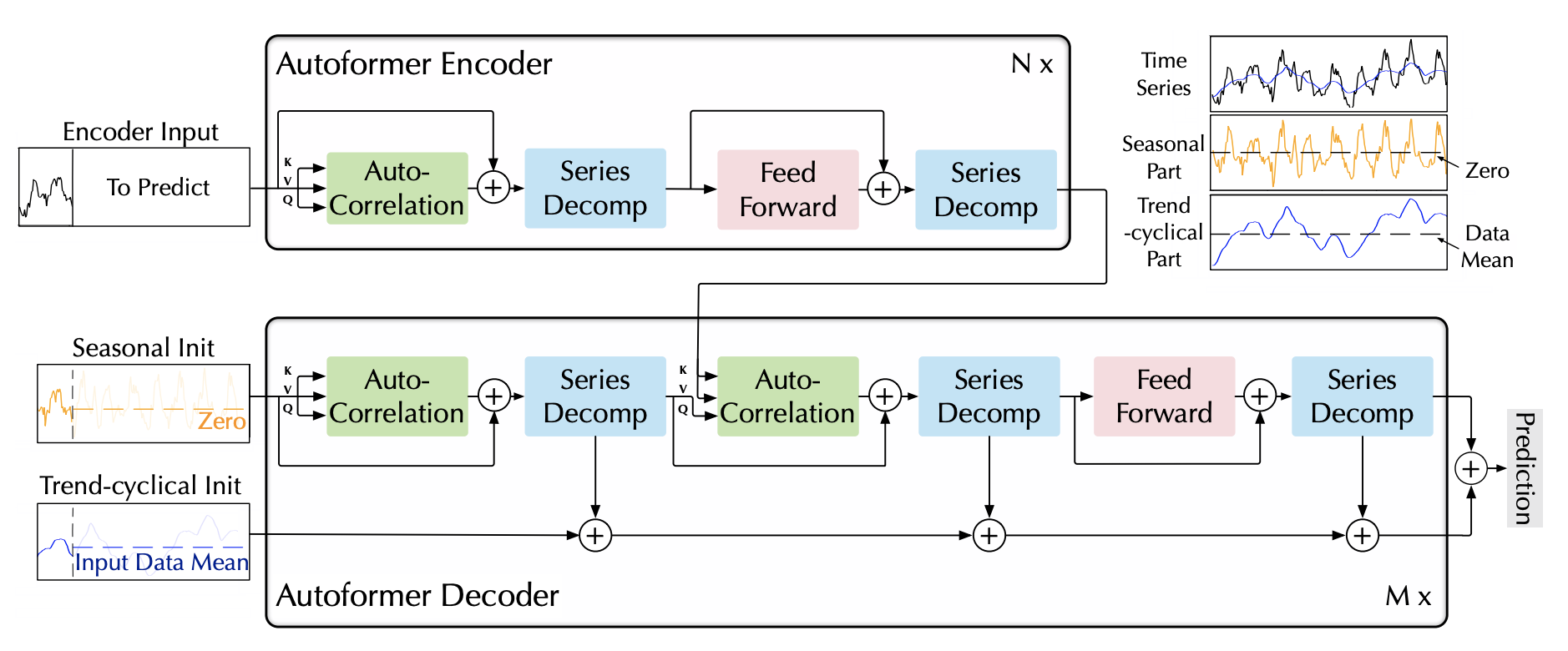
Autoformer模型针对在长期预测中寻找复杂时间模式的可靠依赖关系的挑战。
该架构具有以下几个显著特点: - 基于移动平均滤波器的趋势和季节成分的内置渐进分解。 - 自相关机制,通过计算自相关并根据周期性聚合相似子序列来发现基于周期的依赖关系。 - 由Vaswani等人(2017)提出的经典编码器-解码器,配备多头注意机制。
Autoformer模型利用三组成分的方法来定义其嵌入: - 它采用从卷积网络中获得的编码自回归特征。 - 利用从日历特征中获得的绝对位置嵌入。
参考文献
- 吴海旭, 许杰辉, 王建民, 和 龙铭生. “Autoformer: 带自相关的分解变压器用于长期系列预测”
from fastcore.test import test_eq
from nbdev.showdoc import show_doc1. 辅助函数
class AutoCorrelation(nn.Module):
"""
AutoCorrelation Mechanism with the following two phases:
(1) period-based dependencies discovery
(2) time delay aggregation
This block can replace the self-attention family mechanism seamlessly.
"""
def __init__(self, mask_flag=True, factor=1, scale=None, attention_dropout=0.1, output_attention=False):
super(AutoCorrelation, self).__init__()
self.factor = factor
self.scale = scale
self.mask_flag = mask_flag
self.output_attention = output_attention
self.dropout = nn.Dropout(attention_dropout)
def time_delay_agg_training(self, values, corr):
"""
加速版自相关(批量归一化风格设计)
此版本适用于训练阶段。
"""
head = values.shape[1]
channel = values.shape[2]
length = values.shape[3]
# 找到前k个
top_k = int(self.factor * math.log(length))
mean_value = torch.mean(torch.mean(corr, dim=1), dim=1)
index = torch.topk(torch.mean(mean_value, dim=0), top_k, dim=-1)[1]
weights = torch.stack([mean_value[:, index[i]] for i in range(top_k)], dim=-1)
# 更新相关
tmp_corr = torch.softmax(weights, dim=-1)
# 聚合
tmp_values = values
delays_agg = torch.zeros_like(values, dtype=torch.float, device=values.device)
for i in range(top_k):
pattern = torch.roll(tmp_values, -int(index[i]), -1)
delays_agg = delays_agg + pattern * \
(tmp_corr[:, i].unsqueeze(1).unsqueeze(1).unsqueeze(1).repeat(1, head, channel, length))
return delays_agg
def time_delay_agg_inference(self, values, corr):
"""
加速版自相关(批量归一化风格设计)
此版本专为推理阶段设计。
"""
batch = values.shape[0]
head = values.shape[1]
channel = values.shape[2]
length = values.shape[3]
# 索引初始化
init_index = torch.arange(length, device=values.device).unsqueeze(0).unsqueeze(0).unsqueeze(0).repeat(batch, head, channel, 1)
# 找到前k个
top_k = int(self.factor * math.log(length))
mean_value = torch.mean(torch.mean(corr, dim=1), dim=1)
weights = torch.topk(mean_value, top_k, dim=-1)[0]
delay = torch.topk(mean_value, top_k, dim=-1)[1]
# 更新相关
tmp_corr = torch.softmax(weights, dim=-1)
# 聚合
tmp_values = values.repeat(1, 1, 1, 2)
delays_agg = torch.zeros_like(values, dtype=torch.float, device=values.device)
for i in range(top_k):
tmp_delay = init_index + delay[:, i].unsqueeze(1).unsqueeze(1).unsqueeze(1).repeat(1, head, channel, length)
pattern = torch.gather(tmp_values, dim=-1, index=tmp_delay)
delays_agg = delays_agg + pattern * \
(tmp_corr[:, i].unsqueeze(1).unsqueeze(1).unsqueeze(1).repeat(1, head, channel, length))
return delays_agg
def time_delay_agg_full(self, values, corr):
"""
标准版本的自动相关性
"""
batch = values.shape[0]
head = values.shape[1]
channel = values.shape[2]
length = values.shape[3]
# 索引初始化
init_index = torch.arange(length, device=values.device).unsqueeze(0).unsqueeze(0).unsqueeze(0).repeat(batch, head, channel, 1)
# 找到前k个
top_k = int(self.factor * math.log(length))
weights = torch.topk(corr, top_k, dim=-1)[0]
delay = torch.topk(corr, top_k, dim=-1)[1]
# 更新相关
tmp_corr = torch.softmax(weights, dim=-1)
# 聚合
tmp_values = values.repeat(1, 1, 1, 2)
delays_agg = torch.zeros_like(values, dtype=torch.float, device=values.device)
for i in range(top_k):
tmp_delay = init_index + delay[..., i].unsqueeze(-1)
pattern = torch.gather(tmp_values, dim=-1, index=tmp_delay)
delays_agg = delays_agg + pattern * (tmp_corr[..., i].unsqueeze(-1))
return delays_agg
def forward(self, queries, keys, values, attn_mask):
B, L, H, E = queries.shape
_, S, _, D = values.shape
if L > S:
zeros = torch.zeros_like(queries[:, :(L - S), :], dtype=torch.float, device=queries.device)
values = torch.cat([values, zeros], dim=1)
keys = torch.cat([keys, zeros], dim=1)
else:
values = values[:, :L, :, :]
keys = keys[:, :L, :, :]
# 基于周期的依赖关系
q_fft = torch.fft.rfft(queries.permute(0, 2, 3, 1).contiguous(), dim=-1)
k_fft = torch.fft.rfft(keys.permute(0, 2, 3, 1).contiguous(), dim=-1)
res = q_fft * torch.conj(k_fft)
corr = torch.fft.irfft(res, dim=-1)
# 时间延迟聚合
if self.training:
V = self.time_delay_agg_training(values.permute(0, 2, 3, 1).contiguous(), corr).permute(0, 3, 1, 2)
else:
V = self.time_delay_agg_inference(values.permute(0, 2, 3, 1).contiguous(), corr).permute(0, 3, 1, 2)
if self.output_attention:
return (V.contiguous(), corr.permute(0, 3, 1, 2))
else:
return (V.contiguous(), None)
class AutoCorrelationLayer(nn.Module):
"""
自相关层
"""
def __init__(self, correlation, hidden_size, n_head, d_keys=None,
d_values=None):
super(AutoCorrelationLayer, self).__init__()
d_keys = d_keys or (hidden_size // n_head)
d_values = d_values or (hidden_size // n_head)
self.inner_correlation = correlation
self.query_projection = nn.Linear(hidden_size, d_keys * n_head)
self.key_projection = nn.Linear(hidden_size, d_keys * n_head)
self.value_projection = nn.Linear(hidden_size, d_values * n_head)
self.out_projection = nn.Linear(d_values * n_head, hidden_size)
self.n_head = n_head
def forward(self, queries, keys, values, attn_mask):
B, L, _ = queries.shape
_, S, _ = keys.shape
H = self.n_head
queries = self.query_projection(queries).view(B, L, H, -1)
keys = self.key_projection(keys).view(B, S, H, -1)
values = self.value_projection(values).view(B, S, H, -1)
out, attn = self.inner_correlation(
queries,
keys,
values,
attn_mask
)
out = out.view(B, L, -1)
return self.out_projection(out), attn
class LayerNorm(nn.Module):
"""
专门为季节性部分设计的层归一化
"""
def __init__(self, channels):
super(LayerNorm, self).__init__()
self.layernorm = nn.LayerNorm(channels)
def forward(self, x):
x_hat = self.layernorm(x)
bias = torch.mean(x_hat, dim=1).unsqueeze(1).repeat(1, x.shape[1], 1)
return x_hat - bias
class EncoderLayer(nn.Module):
"""
自动变压器编码器 layer with the progressive decomposition architecture
"""
def __init__(self, attention, hidden_size, conv_hidden_size=None, MovingAvg=25, dropout=0.1, activation="relu"):
super(EncoderLayer, self).__init__()
conv_hidden_size = conv_hidden_size or 4 * hidden_size
self.attention = attention
self.conv1 = nn.Conv1d(in_channels=hidden_size, out_channels=conv_hidden_size, kernel_size=1, bias=False)
self.conv2 = nn.Conv1d(in_channels=conv_hidden_size, out_channels=hidden_size, kernel_size=1, bias=False)
self.decomp1 = SeriesDecomp(MovingAvg)
self.decomp2 = SeriesDecomp(MovingAvg)
self.dropout = nn.Dropout(dropout)
self.activation = F.relu if activation == "relu" else F.gelu
def forward(self, x, attn_mask=None):
new_x, attn = self.attention(
x, x, x,
attn_mask=attn_mask
)
x = x + self.dropout(new_x)
x, _ = self.decomp1(x)
y = x
y = self.dropout(self.activation(self.conv1(y.transpose(-1, 1))))
y = self.dropout(self.conv2(y).transpose(-1, 1))
res, _ = self.decomp2(x + y)
return res, attn
class Encoder(nn.Module):
"""
自动变压器编码器
"""
def __init__(self, attn_layers, conv_layers=None, norm_layer=None):
super(Encoder, self).__init__()
self.attn_layers = nn.ModuleList(attn_layers)
self.conv_layers = nn.ModuleList(conv_layers) if conv_layers is not None else None
self.norm = norm_layer
def forward(self, x, attn_mask=None):
attns = []
if self.conv_layers is not None:
for attn_layer, conv_layer in zip(self.attn_layers, self.conv_layers):
x, attn = attn_layer(x, attn_mask=attn_mask)
x = conv_layer(x)
attns.append(attn)
x, attn = self.attn_layers[-1](x)
attns.append(attn)
else:
for attn_layer in self.attn_layers:
x, attn = attn_layer(x, attn_mask=attn_mask)
attns.append(attn)
if self.norm is not None:
x = self.norm(x)
return x, attns
class DecoderLayer(nn.Module):
"""
具有渐进分解架构的Autoformer解码器层
"""
def __init__(self, self_attention, cross_attention, hidden_size, c_out, conv_hidden_size=None,
MovingAvg=25, dropout=0.1, activation="relu"):
super(DecoderLayer, self).__init__()
conv_hidden_size = conv_hidden_size or 4 * hidden_size
self.self_attention = self_attention
self.cross_attention = cross_attention
self.conv1 = nn.Conv1d(in_channels=hidden_size, out_channels=conv_hidden_size, kernel_size=1, bias=False)
self.conv2 = nn.Conv1d(in_channels=conv_hidden_size, out_channels=hidden_size, kernel_size=1, bias=False)
self.decomp1 = SeriesDecomp(MovingAvg)
self.decomp2 = SeriesDecomp(MovingAvg)
self.decomp3 = SeriesDecomp(MovingAvg)
self.dropout = nn.Dropout(dropout)
self.projection = nn.Conv1d(in_channels=hidden_size, out_channels=c_out, kernel_size=3, stride=1, padding=1,
padding_mode='circular', bias=False)
self.activation = F.relu if activation == "relu" else F.gelu
def forward(self, x, cross, x_mask=None, cross_mask=None):
x = x + self.dropout(self.self_attention(
x, x, x,
attn_mask=x_mask
)[0])
x, trend1 = self.decomp1(x)
x = x + self.dropout(self.cross_attention(
x, cross, cross,
attn_mask=cross_mask
)[0])
x, trend2 = self.decomp2(x)
y = x
y = self.dropout(self.activation(self.conv1(y.transpose(-1, 1))))
y = self.dropout(self.conv2(y).transpose(-1, 1))
x, trend3 = self.decomp3(x + y)
residual_trend = trend1 + trend2 + trend3
residual_trend = self.projection(residual_trend.permute(0, 2, 1)).transpose(1, 2)
return x, residual_trend
class Decoder(nn.Module):
"""
Autoformer解码器
"""
def __init__(self, layers, norm_layer=None, projection=None):
super(Decoder, self).__init__()
self.layers = nn.ModuleList(layers)
self.norm = norm_layer
self.projection = projection
def forward(self, x, cross, x_mask=None, cross_mask=None, trend=None):
for layer in self.layers:
x, residual_trend = layer(x, cross, x_mask=x_mask, cross_mask=cross_mask)
trend = trend + residual_trend
if self.norm is not None:
x = self.norm(x)
if self.projection is not None:
x = self.projection(x)
return x, trend2. 自动变换器
class Autoformer(BaseWindows):
""" Autoformer
The Autoformer model tackles the challenge of finding reliable dependencies on intricate temporal patterns of long-horizon forecasting.
The architecture has the following distinctive features:
- In-built progressive decomposition in trend and seasonal compontents based on a moving average filter.
- Auto-Correlation mechanism that discovers the period-based dependencies by
calculating the autocorrelation and aggregating similar sub-series based on the periodicity.
- Classic encoder-decoder proposed by Vaswani et al. (2017) with a multi-head attention mechanism.
The Autoformer model utilizes a three-component approach to define its embedding:
- It employs encoded autoregressive features obtained from a convolution network.
- Absolute positional embeddings obtained from calendar features are utilized.
*Parameters:*<br>
`h`: int, forecast horizon.<br>
`input_size`: int, maximum sequence length for truncated train backpropagation. Default -1 uses all history.<br>
`futr_exog_list`: str list, future exogenous columns.<br>
`hist_exog_list`: str list, historic exogenous columns.<br>
`stat_exog_list`: str list, static exogenous columns.<br>
`exclude_insample_y`: bool=False, the model skips the autoregressive features y[t-input_size:t] if True.<br>
`decoder_input_size_multiplier`: float = 0.5, .<br>
`hidden_size`: int=128, units of embeddings and encoders.<br>
`n_head`: int=4, controls number of multi-head's attention.<br>
`dropout`: float (0, 1), dropout throughout Autoformer architecture.<br>
`factor`: int=3, Probsparse attention factor.<br>
`conv_hidden_size`: int=32, channels of the convolutional encoder.<br>
`activation`: str=`GELU`, activation from ['ReLU', 'Softplus', 'Tanh', 'SELU', 'LeakyReLU', 'PReLU', 'Sigmoid', 'GELU'].<br>
`encoder_layers`: int=2, number of layers for the TCN encoder.<br>
`decoder_layers`: int=1, number of layers for the MLP decoder.<br>
`distil`: bool = True, wether the Autoformer decoder uses bottlenecks.<br>
`loss`: PyTorch module, instantiated train loss class from [losses collection](https://nixtla.github.io/neuralforecast/losses.pytorch.html).<br>
`max_steps`: int=1000, maximum number of training steps.<br>
`learning_rate`: float=1e-3, Learning rate between (0, 1).<br>
`num_lr_decays`: int=-1, Number of learning rate decays, evenly distributed across max_steps.<br>
`early_stop_patience_steps`: int=-1, Number of validation iterations before early stopping.<br>
`val_check_steps`: int=100, Number of training steps between every validation loss check.<br>
`batch_size`: int=32, number of different series in each batch.<br>
`valid_batch_size`: int=None, number of different series in each validation and test batch, if None uses batch_size.<br>
`windows_batch_size`: int=1024, number of windows to sample in each training batch, default uses all.<br>
`inference_windows_batch_size`: int=1024, number of windows to sample in each inference batch.<br>
`start_padding_enabled`: bool=False, if True, the model will pad the time series with zeros at the beginning, by input size.<br>
`scaler_type`: str='robust', type of scaler for temporal inputs normalization see [temporal scalers](https://nixtla.github.io/neuralforecast/common.scalers.html).<br>
`random_seed`: int=1, random_seed for pytorch initializer and numpy generators.<br>
`num_workers_loader`: int=os.cpu_count(), workers to be used by `TimeSeriesDataLoader`.<br>
`drop_last_loader`: bool=False, if True `TimeSeriesDataLoader` drops last non-full batch.<br>
`alias`: str, optional, Custom name of the model.<br>
`optimizer`: Subclass of 'torch.optim.Optimizer', optional, user specified optimizer instead of the default choice (Adam).<br>
`optimizer_kwargs`: dict, optional, list of parameters used by the user specified `optimizer`.<br>
`lr_scheduler`: Subclass of 'torch.optim.lr_scheduler.LRScheduler', optional, user specified lr_scheduler instead of the default choice (StepLR).<br>
`lr_scheduler_kwargs`: dict, optional, list of parameters used by the user specified `lr_scheduler`.<br>
`**trainer_kwargs`: int, keyword trainer arguments inherited from [PyTorch Lighning's trainer](https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.trainer.trainer.Trainer.html?highlight=trainer).<br>
*References*<br>
- [Wu, Haixu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. "Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting"](https://proceedings.neurips.cc/paper/2021/hash/bcc0d400288793e8bdcd7c19a8ac0c2b-Abstract.html)<br>
"""
# 类属性
SAMPLING_TYPE = 'windows'
EXOGENOUS_FUTR = True
EXOGENOUS_HIST = False
EXOGENOUS_STAT = False
def __init__(self,
h: int,
input_size: int,
stat_exog_list = None,
hist_exog_list = None,
futr_exog_list = None,
exclude_insample_y = False,
decoder_input_size_multiplier: float = 0.5,
hidden_size: int = 128,
dropout: float = 0.05,
factor: int = 3,
n_head: int = 4,
conv_hidden_size: int = 32,
activation: str = 'gelu',
encoder_layers: int = 2,
decoder_layers: int = 1,
MovingAvg_window: int = 25,
loss = MAE(),
valid_loss = None,
max_steps: int = 5000,
learning_rate: float = 1e-4,
num_lr_decays: int = -1,
early_stop_patience_steps: int =-1,
val_check_steps: int = 100,
batch_size: int = 32,
valid_batch_size: Optional[int] = None,
windows_batch_size = 1024,
inference_windows_batch_size = 1024,
start_padding_enabled = False,
step_size: int = 1,
scaler_type: str = 'identity',
random_seed: int = 1,
num_workers_loader: int = 0,
drop_last_loader: bool = False,
optimizer = None,
optimizer_kwargs = None,
lr_scheduler = None,
lr_scheduler_kwargs = None,
**trainer_kwargs):
super(Autoformer, self).__init__(h=h,
input_size=input_size,
hist_exog_list=hist_exog_list,
stat_exog_list=stat_exog_list,
futr_exog_list = futr_exog_list,
exclude_insample_y = exclude_insample_y,
loss=loss,
valid_loss=valid_loss,
max_steps=max_steps,
learning_rate=learning_rate,
num_lr_decays=num_lr_decays,
early_stop_patience_steps=early_stop_patience_steps,
val_check_steps=val_check_steps,
batch_size=batch_size,
windows_batch_size=windows_batch_size,
valid_batch_size=valid_batch_size,
inference_windows_batch_size=inference_windows_batch_size,
start_padding_enabled = start_padding_enabled,
step_size=step_size,
scaler_type=scaler_type,
num_workers_loader=num_workers_loader,
drop_last_loader=drop_last_loader,
random_seed=random_seed,
optimizer=optimizer,
optimizer_kwargs=optimizer_kwargs,
lr_scheduler=lr_scheduler,
lr_scheduler_kwargs=lr_scheduler_kwargs,
**trainer_kwargs)
# 建筑
self.label_len = int(np.ceil(input_size * decoder_input_size_multiplier))
if (self.label_len >= input_size) or (self.label_len <= 0):
raise Exception(f'Check decoder_input_size_multiplier={decoder_input_size_multiplier}, range (0,1)')
if activation not in ['relu', 'gelu']:
raise Exception(f'Check activation={activation}')
self.c_out = self.loss.outputsize_multiplier
self.output_attention = False
self.enc_in = 1
self.dec_in = 1
# 分解
self.decomp = SeriesDecomp(MovingAvg_window)
# 嵌入
self.enc_embedding = DataEmbedding(c_in=self.enc_in,
exog_input_size=self.futr_exog_size,
hidden_size=hidden_size,
pos_embedding=False,
dropout=dropout)
self.dec_embedding = DataEmbedding(self.dec_in,
exog_input_size=self.futr_exog_size,
hidden_size=hidden_size,
pos_embedding=False,
dropout=dropout)
# 编码器
self.encoder = Encoder(
[
EncoderLayer(
AutoCorrelationLayer(
AutoCorrelation(False, factor,
attention_dropout=dropout,
output_attention=self.output_attention),
hidden_size, n_head),
hidden_size=hidden_size,
conv_hidden_size=conv_hidden_size,
MovingAvg=MovingAvg_window,
dropout=dropout,
activation=activation
) for l in range(encoder_layers)
],
norm_layer=LayerNorm(hidden_size)
)
# 解码器
self.decoder = Decoder(
[
DecoderLayer(
AutoCorrelationLayer(
AutoCorrelation(True, factor, attention_dropout=dropout, output_attention=False),
hidden_size, n_head),
AutoCorrelationLayer(
AutoCorrelation(False, factor, attention_dropout=dropout, output_attention=False),
hidden_size, n_head),
hidden_size=hidden_size,
c_out=self.c_out,
conv_hidden_size=conv_hidden_size,
MovingAvg=MovingAvg_window,
dropout=dropout,
activation=activation,
)
for l in range(decoder_layers)
],
norm_layer=LayerNorm(hidden_size),
projection=nn.Linear(hidden_size, self.c_out, bias=True)
)
def forward(self, windows_batch):
# 解析Windows批处理文件
insample_y = windows_batch['insample_y']
#insample_mask = windows_batch['insample_mask']
#hist_exog = windows_batch['hist_exog']
#stat_exog = windows_batch['stat_exog']
futr_exog = windows_batch['futr_exog']
# 解析输入
insample_y = insample_y.unsqueeze(-1) # [Ws,L,1]
if self.futr_exog_size > 0:
x_mark_enc = futr_exog[:,:self.input_size,:]
x_mark_dec = futr_exog[:,-(self.label_len+self.h):,:]
else:
x_mark_enc = None
x_mark_dec = None
x_dec = torch.zeros(size=(len(insample_y),self.h,1), device=insample_y.device)
x_dec = torch.cat([insample_y[:,-self.label_len:,:], x_dec], dim=1)
# 十二月omp init
mean = torch.mean(insample_y, dim=1).unsqueeze(1).repeat(1, self.h, 1)
zeros = torch.zeros([x_dec.shape[0], self.h, x_dec.shape[2]], device=insample_y.device)
seasonal_init, trend_init = self.decomp(insample_y)
# 十二月oder input
trend_init = torch.cat([trend_init[:, -self.label_len:, :], mean], dim=1)
seasonal_init = torch.cat([seasonal_init[:, -self.label_len:, :], zeros], dim=1)
# 编码
enc_out = self.enc_embedding(insample_y, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
# 十二月
dec_out = self.dec_embedding(seasonal_init, x_mark_dec)
seasonal_part, trend_part = self.decoder(dec_out, enc_out, x_mask=None, cross_mask=None,
trend=trend_init)
# 最终
dec_out = trend_part + seasonal_part
forecast = self.loss.domain_map(dec_out[:, -self.h:])
return forecastshow_doc(Autoformer)show_doc(Autoformer.fit, name='Autoformer.fit')show_doc(Autoformer.predict, name='Autoformer.predict')使用示例
在当今全球化的世界中,跨文化交流变得越来越重要。随着国际贸易和旅游业的蓬勃发展,人们有机会接触到各种不同的文化背景。这种多样性不仅丰富了我们的视野,还促进了相互理解和尊重。然而,跨文化交流也带来了挑战,如语言障碍、文化误解和价值观冲突。为了有效地进行跨文化交流,我们需要培养开放的心态,学习不同文化的习俗和礼仪,并尊重他人的观点和信仰。通过这种方式,我们可以建立更加和谐和包容的社会。
import pandas as pd
import matplotlib.pyplot as plt
from neuralforecast import NeuralForecast
from neuralforecast.models import Autoformer
from neuralforecast.utils import AirPassengersPanel, AirPassengersStatic, augment_calendar_df
AirPassengersPanel, calendar_cols = augment_calendar_df(df=AirPassengersPanel, freq='M')
Y_train_df = AirPassengersPanel[AirPassengersPanel.ds<AirPassengersPanel['ds'].values[-12]] # 132次列车
Y_test_df = AirPassengersPanel[AirPassengersPanel.ds>=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True) # 12项测试
model = Autoformer(h=12,
input_size=24,
hidden_size = 16,
conv_hidden_size = 32,
n_head=2,
loss=MAE(),
futr_exog_list=calendar_cols,
scaler_type='robust',
learning_rate=1e-3,
max_steps=300,
val_check_steps=50,
early_stop_patience_steps=2)
nf = NeuralForecast(
models=[model],
freq='M'
)
nf.fit(df=Y_train_df, static_df=AirPassengersStatic, val_size=12)
forecasts = nf.predict(futr_df=Y_test_df)
Y_hat_df = forecasts.reset_index(drop=False).drop(columns=['unique_id','ds'])
plot_df = pd.concat([Y_test_df, Y_hat_df], axis=1)
plot_df = pd.concat([Y_train_df, plot_df])
if model.loss.is_distribution_output:
plot_df = plot_df[plot_df.unique_id=='Airline1'].drop('unique_id', axis=1)
plt.plot(plot_df['ds'], plot_df['y'], c='black', label='True')
plt.plot(plot_df['ds'], plot_df['Autoformer-median'], c='blue', label='median')
plt.fill_between(x=plot_df['ds'][-12:],
y1=plot_df['Autoformer-lo-90'][-12:].values,
y2=plot_df['Autoformer-hi-90'][-12:].values,
alpha=0.4, label='level 90')
plt.grid()
plt.legend()
plt.plot()
else:
plot_df = plot_df[plot_df.unique_id=='Airline1'].drop('unique_id', axis=1)
plt.plot(plot_df['ds'], plot_df['y'], c='black', label='True')
plt.plot(plot_df['ds'], plot_df['Autoformer'], c='blue', label='Forecast')
plt.legend()
plt.grid()Give us a ⭐ on Github