转换器¶
在生产环境中使用ONNX意味着模型的预测功能可以通过ONNX操作符实现。必须选择一个运行时,该运行时在模型部署的平台上可用。检查差异,最后测量延迟。如果存在一个转换库支持该框架的所有部分,模型转换的第一步可能会很容易。如果不是这种情况,则必须在ONNX中实现缺失的部分。这可能会非常耗时。
什么是转换库?¶
sklearn-onnx 将 scikit-learn 模型 转换为 ONNX。它使用上面介绍的 API 重写模型的预测函数, 无论它是什么,使用 ONNX 运算符。它确保预测结果与使用 原始模型计算的预期预测结果相等或至少非常接近。
机器学习库通常有它们自己的设计。 这就是为什么每个库都有一个特定的转换库。 许多这样的库都列在这里: 转换为ONNX格式。 以下是一个简短的列表:
sklearn-onnx: 将模型从scikit-learn转换而来,
tensorflow-onnx: 将模型从tensorflow转换而来,
onnxmltools: 将模型从lightgbm, xgboost, pyspark, libsvm转换
torch.onnx: 将模型从pytorch转换。
所有这些库面临的主要挑战是保持节奏。 每当ONNX或它们支持的库有新版本发布时,它们都必须进行更新。这意味着每年有三到五次新版本发布。
转换库之间不兼容。 tensorflow-onnx 专门用于tensorflow,且仅适用于tensorflow。 同样,sklearn-onnx专门用于scikit-learn。
一个挑战是定制化。在机器学习模型中支持定制部分是很困难的。他们必须为这部分编写特定的转换器。某种程度上,这就像实现了两次预测函数。有一个简单的例子:深度学习框架有自己的原语,以确保相同的代码可以在不同的环境中执行。只要自定义层或子部分使用的是pytorch或tensorflow的部分,就不需要做太多工作。对于scikit-learn来说,情况就不同了。这个包没有自己的加法或乘法,它依赖于numpy或scipy。用户必须使用ONNX原语实现其转换器或预测器,无论它是否是用numpy实现的。
替代方案¶
实现ONNX导出功能的一种替代方案是利用标准协议,例如Array API标准,该标准标准化了一组常见的数组操作。它使得像NumPy、JAX、PyTorch、CuPy等库之间的代码重用成为可能。ndonnx允许使用ONNX后端执行,并为符合Array API标准的代码提供即时ONNX导出。这减少了对专用转换器库代码的需求,因为用于实现库的大部分代码可以在ONNX转换中重复使用。对于希望在构建ONNX图时获得类似NumPy体验的转换器作者来说,它还提供了一个方便的原始工具。
操作集¶
ONNX 发布的包带有版本号,如
major.minor.fix。每次次要更新意味着操作符列表
不同或签名已更改。它还与一个操作集相关联,版本
1.10 是操作集 15,1.11 将是操作集 16。
每个 ONNX 图都应定义其遵循的操作集。更改此
版本而不更新操作符可能会使图无效。
如果未指定操作集,ONNX 将认为该图
适用于最新的操作集。
新的操作集通常引入新的操作符。相同的推理函数可以以不同的方式实现,通常以更高效的方式。然而,模型运行的运行时可能不支持最新的操作集,或者至少在安装的版本中不支持。这就是为什么每个转换库都提供了为特定操作集创建ONNX图的可能性,通常称为target_opset。ONNX语言描述了简单和复杂的操作符。更改操作集类似于升级库。onnx和onnx运行时必须支持向后兼容性。
其他API¶
前面章节中的示例显示,onnx API 非常冗长。除非是一个小的图,否则通过阅读代码很难获得整个图的概览。几乎每个转换库都实现了不同的 API 来创建图,通常比 onnx 包的 API 更简单、更不冗长。所有 API 都自动添加初始化器,隐藏每个中间结果的名称创建,处理不同 opset 的不同版本。
一个带有方法 add_node 的类 Graph¶
tensorflow-onnx 实现了一个类图。
当ONNX没有类似的函数时,它会用ONNX操作符重写tensorflow函数(参见 Erf。
sklearn-onnx 定义了两个不同的 API。第一个在该示例中引入的 实现一个转换器 遵循了与 tensorflow-onnx 类似的设计。以下行是从线性分类器的转换器中提取的。
# initializer
coef = scope.get_unique_variable_name('coef')
model_coef = np.array(
classifier_attrs['coefficients'], dtype=np.float64)
model_coef = model_coef.reshape((number_of_classes, -1)).T
container.add_initializer(
coef, proto_dtype, model_coef.shape, model_coef.ravel().tolist())
intercept = scope.get_unique_variable_name('intercept')
model_intercept = np.array(
classifier_attrs['intercepts'], dtype=np.float64)
model_intercept = model_intercept.reshape((number_of_classes, -1)).T
container.add_initializer(
intercept, proto_dtype, model_intercept.shape,
model_intercept.ravel().tolist())
# add nodes
multiplied = scope.get_unique_variable_name('multiplied')
container.add_node(
'MatMul', [operator.inputs[0].full_name, coef], multiplied,
name=scope.get_unique_operator_name('MatMul'))
# [...]
argmax_output_name = scope.get_unique_variable_name('label')
container.add_node('ArgMax', raw_score_name, argmax_output_name,
name=scope.get_unique_operator_name('ArgMax'),
axis=1)
操作符作为函数¶
在实现一个新的转换器中展示的第二个API更加紧凑,并将每个ONNX操作符定义为可组合的函数。对于KMeans,语法看起来像这样,更简洁且更易于阅读。
rs = OnnxReduceSumSquare(
input_name, axes=[1], keepdims=1, op_version=opv)
gemm_out = OnnxMatMul(
input_name, (C.T * (-2)).astype(dtype), op_version=opv)
z = OnnxAdd(rs, gemm_out, op_version=opv)
y2 = OnnxAdd(C2, z, op_version=opv)
ll = OnnxArgMin(y2, axis=1, keepdims=0, output_names=out[:1],
op_version=opv)
y2s = OnnxSqrt(y2, output_names=out[1:], op_version=opv)
从经验中学到的技巧¶
差异¶
ONNX 是强类型的,并且针对深度学习中常见的 float32 类型进行了优化。标准机器学习库中同时使用 float32 和 float64。numpy 通常会转换为最通用的类型 float64。当预测函数是连续的时候,这没有显著影响。当不是连续的时候,必须使用正确的类型。示例 切换到浮点数时的问题 提供了更多关于该主题的见解。
并行化改变了计算的顺序。这通常并不重要,但它可能解释一些奇怪的差异。1 + 1e17 - 1e17 = 0 但 1e17 - 1e17 + 1 = 1。高数量级的情况很少见,但当模型使用矩阵的逆时,这种情况并不罕见。
IsolationForest 技巧¶
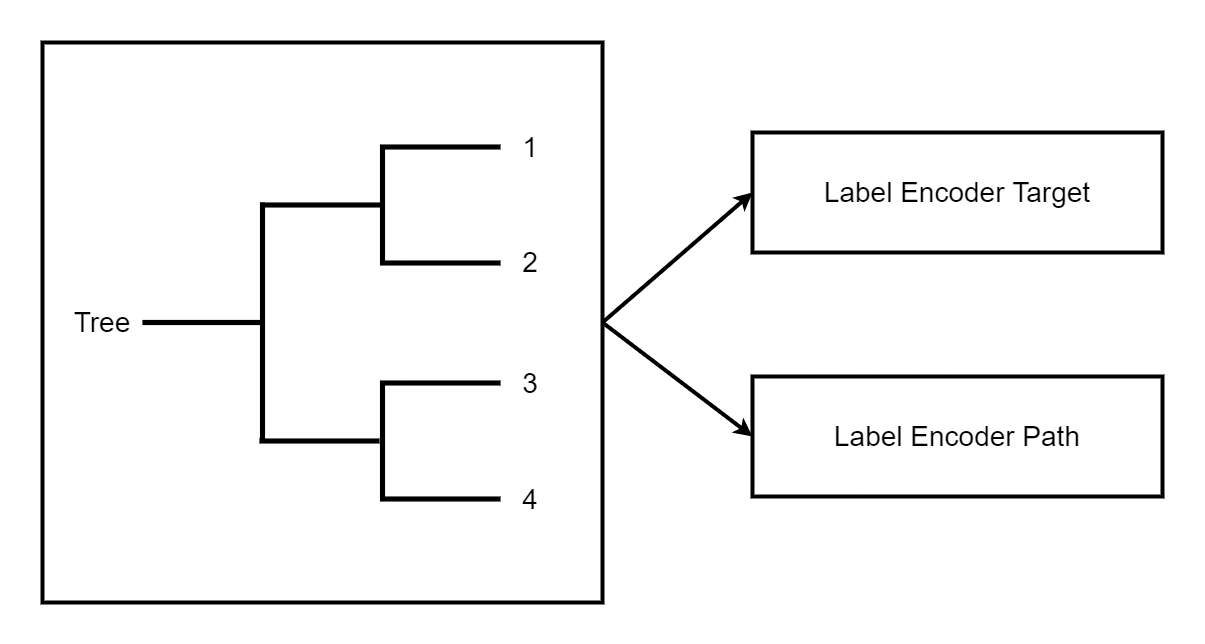
ONNX 仅实现了 TreeEnsembleRegressor,但它没有提供检索决策路径或图形统计信息的可能性。技巧是使用一个森林来预测叶子索引,并将这个叶子索引与所需信息映射一次或多次。
离散化¶
查找特征落在哪个区间。使用numpy很容易做到,但在ONNX中高效实现则不那么容易。最快的方法是使用TreeEnsembleRegressor,一种二分搜索,它输出区间索引。这就是这个示例所实现的:WOE转换器。
贡献¶
onnx repository 必须被fork并克隆。
构建¶
Windows 构建需要 conda。以下步骤可能不是最新的。 文件夹 onnx/.github/workflows 包含最新的说明。
Windows
使用Anaconda构建更容易。首先:创建一个环境。 这只需要做一次。
conda create --yes --quiet --name py3.9 python=3.9
conda install -n py3.9 -y -c conda-forge numpy libprotobuf=3.16.0
然后构建包:
git submodule update --init --recursive
set ONNX_BUILD_TESTS=1
set ONNX_ML=$(onnx_ml)
set CMAKE_ARGS=-DONNX_USE_PROTOBUF_SHARED_LIBS=ON -DONNX_USE_LITE_PROTO=ON -DONNX_WERROR=ON
python -m build --wheel
现在可以安装该包了。
Linux
克隆仓库后,可以运行以下指令:
python -m build --wheel
构建Markdown文档¶
必须先构建包(参见上一节)。
set ONNX_BUILD_TESTS=1
set ONNX_ML=$(onnx_ml)
set CMAKE_ARGS=-DONNX_USE_PROTOBUF_SHARED_LIBS=ON -DONNX_USE_LITE_PROTO=ON -DONNX_WERROR=ON
python onnx\gen_proto.py -l
python onnx\gen_proto.py -l --ml
pip install -e .
python onnx\backend\test\cmd_tools.py generate-data
python onnx\backend\test\stat_coverage.py
python onnx\defs\gen_doc.py
set ONNX_ML=0
python onnx\defs\gen_doc.py
set ONNX_ML=1
更新现有操作符¶
所有操作符都定义在文件夹
onnx/onnx/defs中。
每个子文件夹中有两个文件,一个叫做defs.cc,另一个叫做old.cc。
defs.cc: 包含每个操作符的最新定义old.cc: 包含之前opset中已弃用的操作符版本
更新操作符意味着将定义从defs.cc复制到old.cc,并更新defs.cc中的现有定义。
必须修改一个遵循模式onnx/defs/operator_sets*.h的文件。这些头文件注册了现有操作符的列表。
文件 onnx/defs/schema.h 包含最新的操作集版本。如果一个操作集被升级,它也必须被更新。
文件 onnx/version_converter/convert.h 包含将节点从一个操作集转换到下一个操作集时要应用的规则。 此文件也可能会更新。
必须编译包并再次生成文档,以自动更新markdown文档,并且必须将其包含在PR中。
然后必须更新单元测试。
总结
修改文件
defs.cc,old.cc,onnx/defs/operator_sets*.h,onnx/defs/schema.h可选:修改文件
onnx/version_converter/convert.h构建onnx。
构建文档。
更新单元测试。
PR 应包括修改后的文件和修改后的 markdown 文档,
通常是以下文件的一部分
docs/docs/Changelog-ml.md, docs/Changelog.md,
docs/Operators-ml.md, docs/Operators.md,
docs/TestCoverage-ml.md, docs/TestCoverage.md.