本页面为开发者提供构建特定应用GPT Action的说明与指南。在继续之前,请确保您已熟悉以下信息:
此特定GPT操作概述了如何连接到Google BigQuery——谷歌云的分析数据仓库。该操作接收用户问题,扫描相关表格以收集数据模式,然后编写SQL查询来回答用户问题。
注意:这些指令返回的是一个可执行的SQL语句,而非结果本身。目前需要通过中间件才能返回CSV文件——我们将很快发布相关示例的操作说明
价值与示例商业应用场景
价值: 用户现在可以利用ChatGPT的自然语言能力直接连接BigQuery的数据仓库。
示例用例:
- 数据科学家可以连接到表格并使用ChatGPT的数据分析功能运行数据分析
- 公民数据用户可以对其交易数据提出基本问题
- 用户可以更清晰地查看其数据及潜在异常
应用信息
应用密钥链接
在开始之前,请查看应用程序中的这些链接:
应用前提条件
在开始之前,请确保您已在应用程序环境中完成以下步骤:
- 设置一个GCP项目
- 在该GCP项目中设置一个BQ数据集
- 确保通过ChatGPT验证进入BigQuery的用户拥有访问该BQ数据集的权限
ChatGPT 步骤
自定义GPT指令
创建自定义GPT后,请将以下文本复制到指令面板中。有问题吗?查看入门示例详细了解此步骤的操作方法。
**Context**: You are an expert at writing BigQuery SQL queries. A user is going to ask you a question.
**Instructions**:
1. No matter the user's question, start by running `runQuery` operation using this query: "SELECT column_name, table_name, data_type, description FROM `{project}.{dataset}.INFORMATION_SCHEMA.COLUMN_FIELD_PATHS`"
-- Assume project = "<insert your default project here>", dataset = "<insert your default dataset here>", unless the user provides different values
-- Remember to include useLegacySql:false in the json output
2. Convert the user's question into a SQL statement that leverages the step above and run the `runQuery` operation on that SQL statement to confirm the query works. Add a limit of 100 rows
3. Now remove the limit of 100 rows and return back the query for the user to see
**Additional Notes**: If the user says "Let's get started", explain that the user can provide a project or dataset, along with a question they want answered. If the user has no ideas, suggest that we have a sample flights dataset they can query - ask if they want you to query thatOpenAPI 规范
创建自定义GPT后,在操作面板中复制以下文本。有问题吗?查看入门示例了解此步骤的详细操作方式。
openapi: 3.1.0
info:
title: BigQuery API
description: API for querying a BigQuery table.
version: 1.0.0
servers:
- url: https://bigquery.googleapis.com/bigquery/v2
description: Google BigQuery API server
paths:
/projects/{projectId}/queries:
post:
operationId: runQuery
summary: Executes a query on a specified BigQuery table.
description: Submits a query to BigQuery and returns the results.
x-openai-isConsequential: false
parameters:
- name: projectId
in: path
required: true
description: The ID of the Google Cloud project.
schema:
type: string
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
query:
type: string
description: The SQL query string.
useLegacySql:
type: boolean
description: Whether to use legacy SQL.
default: false
responses:
'200':
description: Successful query execution.
content:
application/json:
schema:
type: object
properties:
kind:
type: string
example: "bigquery#queryResponse"
schema:
type: object
description: The schema of the results.
jobReference:
type: object
properties:
projectId:
type: string
jobId:
type: string
rows:
type: array
items:
type: object
properties:
f:
type: array
items:
type: object
properties:
v:
type: string
totalRows:
type: string
description: Total number of rows in the query result.
pageToken:
type: string
description: Token for pagination of query results.
'400':
description: Bad request. The request was invalid.
'401':
description: Unauthorized. Authentication is required.
'403':
description: Forbidden. The request is not allowed.
'404':
description: Not found. The specified resource was not found.
'500':
description: Internal server error. An error occurred while processing the request.认证说明
以下是设置与这个第三方应用程序进行身份验证的说明。有问题吗?查看入门示例以更详细地了解此步骤的工作原理。
预操作步骤
在ChatGPT中设置身份验证之前,请先在应用程序中执行以下步骤。
- 前往Google云控制台
- 导航至 API 和服务 > 凭据
- 创建新的OAuth凭据(或使用现有凭据)
- 找到您的OAuth客户端ID和客户端密钥,并安全存储这两个值(见下方截图)
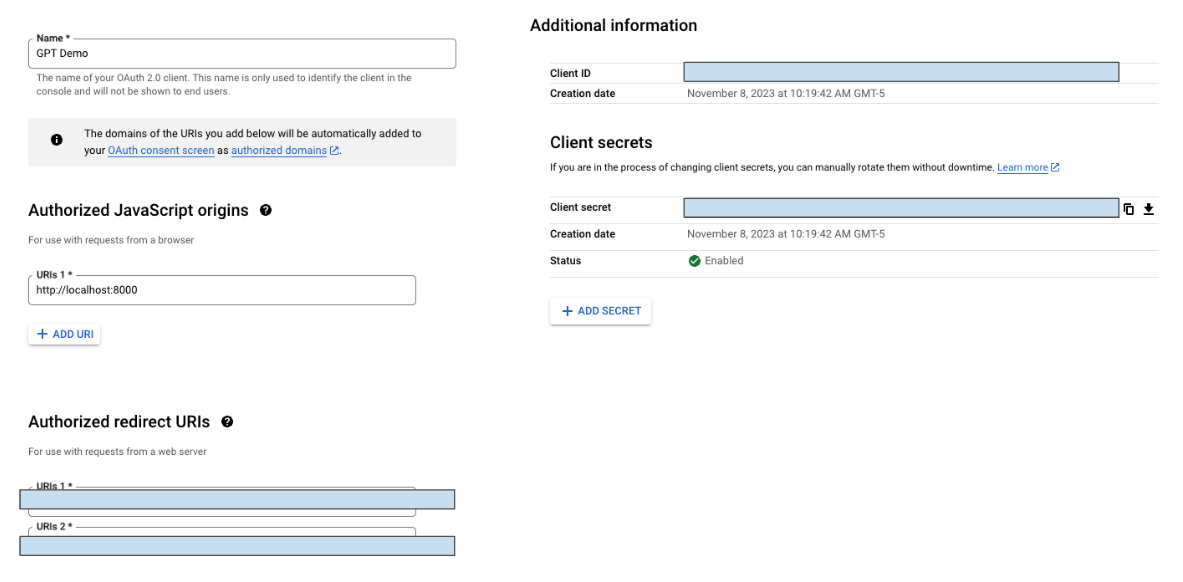
在ChatGPT中
在ChatGPT中,点击"认证"并选择"OAuth"。输入以下信息。
- 客户端ID: 使用上述步骤中的客户端ID
- 客户端密钥: 使用上述步骤中的客户端密钥
- 授权URL: https://accounts.google.com/o/oauth2/auth
- 令牌URL: https://oauth2.googleapis.com/token
- 范围: https://www.googleapis.com/auth/bigquery
- Token: 默认 (POST)
后续操作步骤
在ChatGPT中设置好身份验证后,按照应用程序中的以下步骤完成Action的最终设置。
- 从GPT Action复制回调URL
- 在“Authorized redirect URIs”(见上方截图)中,添加您的回调URL
常见问题与故障排除
- 回调URL错误: 如果您在ChatGPT中遇到回调URL错误,请仔细查看上面的截图。您需要直接将回调URL添加到GCP中,才能使操作正确认证
- Schema调用了错误的项目或数据集: 如果ChatGPT调用了错误的项目或数据集,建议更新您的指令,使其更明确地指出(a)应该调用哪个项目/数据集,或者(b)要求在运行查询前用户必须提供这些确切细节
是否有您希望我们优先考虑的集成方案?我们的集成是否存在错误?请在GitHub上提交PR或问题,我们会尽快查看。