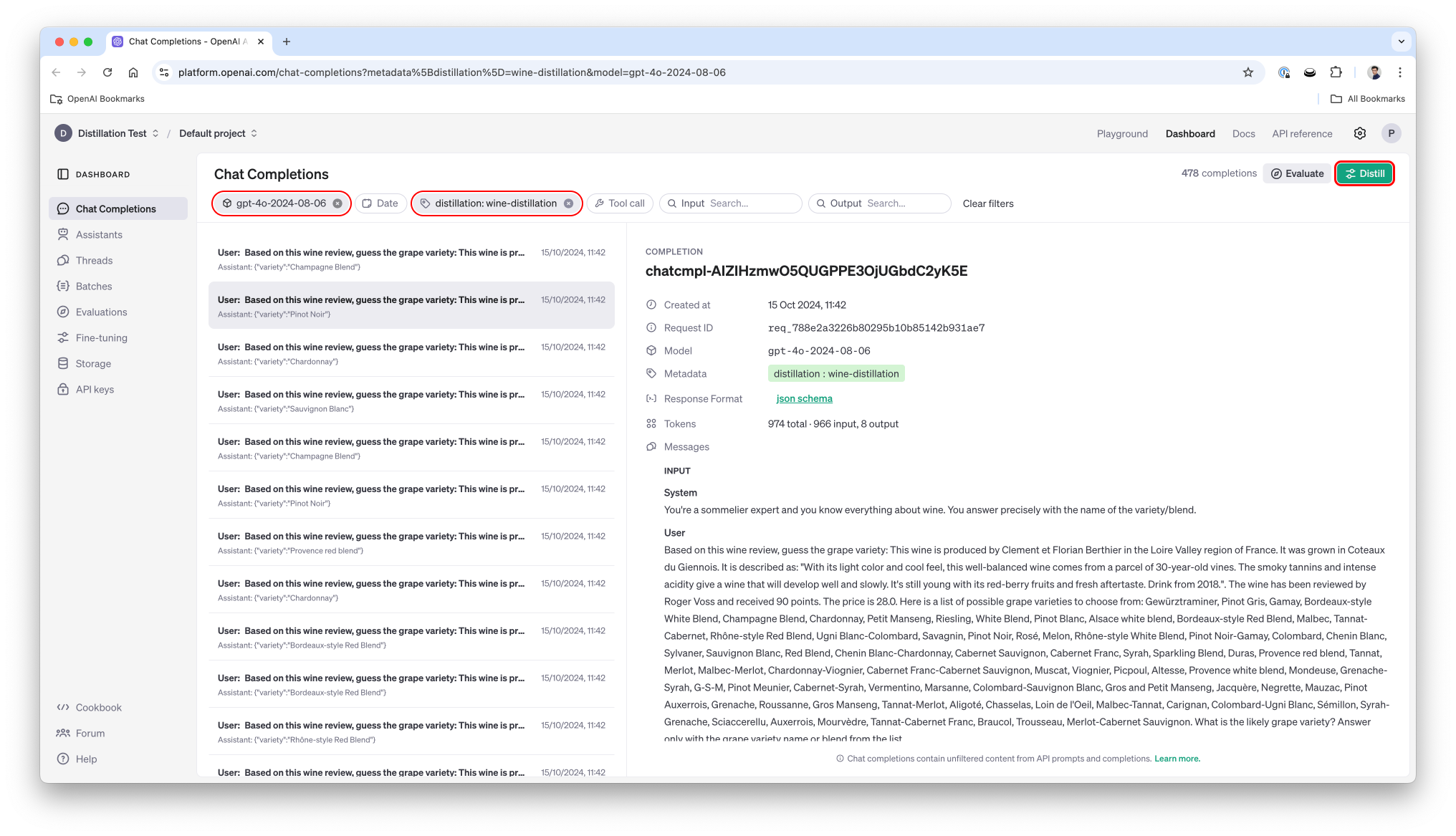
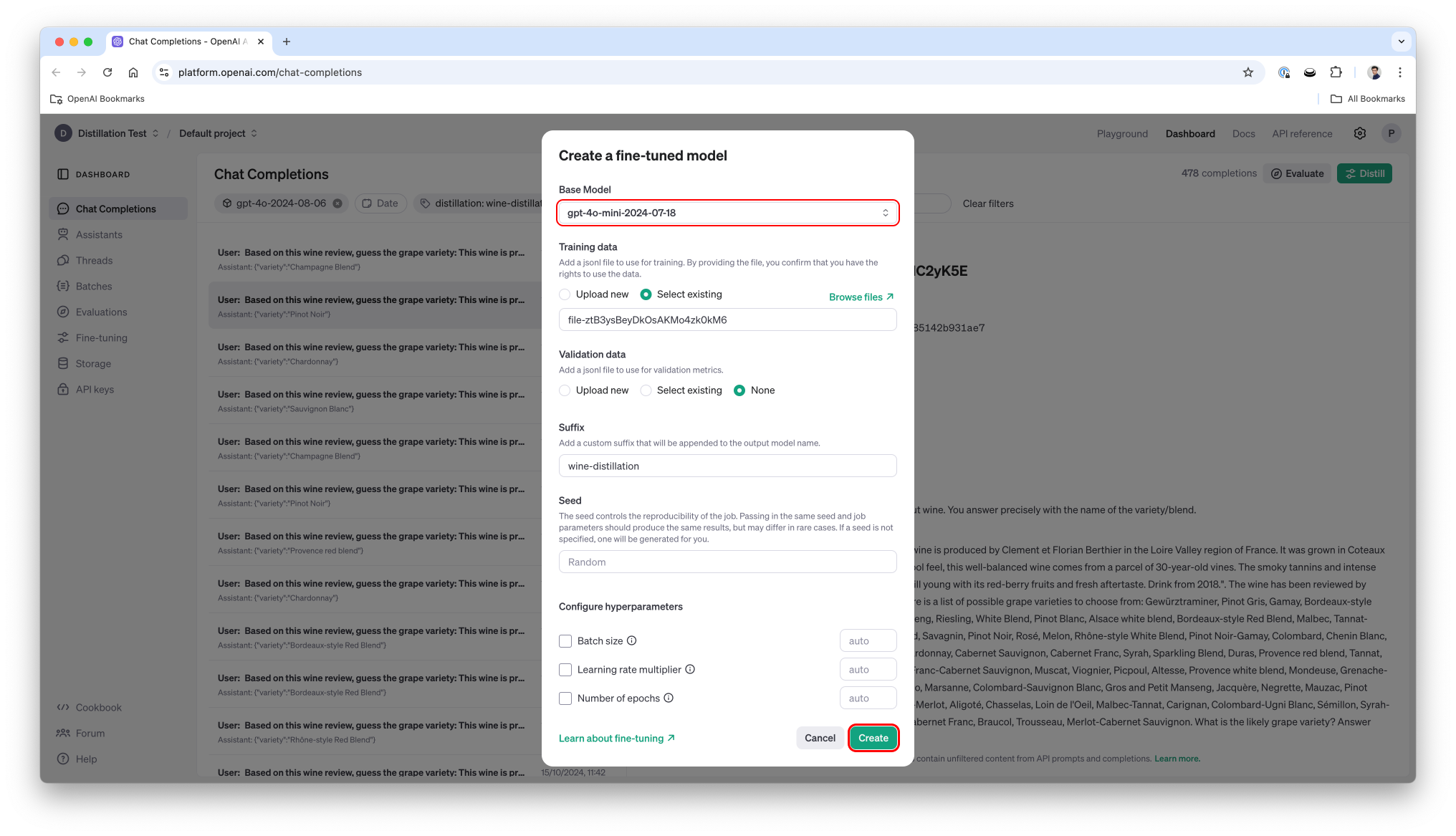
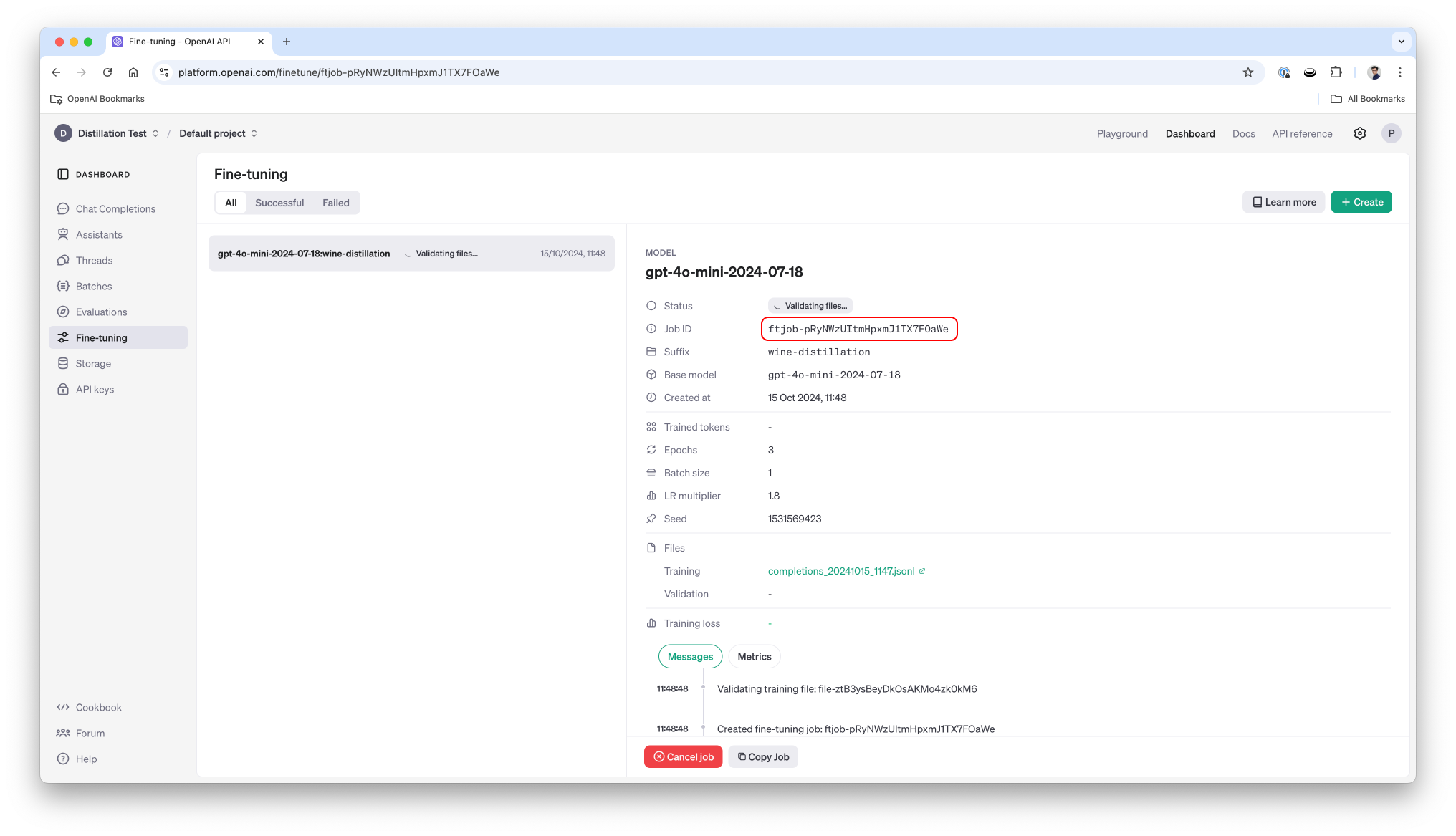
'\n Based on this wine review, guess the grape variety:\n This wine is produced by Trimbach in the Alsace region of France.\n It was grown in Alsace. It is described as: "This dry and restrained wine offers spice in profusion. Balanced with acidity and a firm texture, it\'s very much for food.".\n The wine has been reviewed by Roger Voss and received 87 points.\n The price is 24.0.\n\n Here is a list of possible grape varieties to choose from: Gewürztraminer, Pinot Gris, Gamay, Bordeaux-style White Blend, Champagne Blend, Chardonnay, Petit Manseng, Riesling, White Blend, Pinot Blanc, Alsace white blend, Bordeaux-style Red Blend, Malbec, Tannat-Cabernet, Rhône-style Red Blend, Ugni Blanc-Colombard, Savagnin, Pinot Noir, Rosé, Melon, Rhône-style White Blend, Pinot Noir-Gamay, Colombard, Chenin Blanc, Sylvaner, Sauvignon Blanc, Red Blend, Chenin Blanc-Chardonnay, Cabernet Sauvignon, Cabernet Franc, Syrah, Sparkling Blend, Duras, Provence red blend, Tannat, Merlot, Malbec-Merlot, Chardonnay-Viognier, Cabernet Franc-Cabernet Sauvignon, Muscat, Viognier, Picpoul, Altesse, Provence white blend, Mondeuse, Grenache-Syrah, G-S-M, Pinot Meunier, Cabernet-Syrah, Vermentino, Marsanne, Colombard-Sauvignon Blanc, Gros and Petit Manseng, Jacquère, Negrette, Mauzac, Pinot Auxerrois, Grenache, Roussanne, Gros Manseng, Tannat-Merlot, Aligoté, Chasselas, Loin de l\'Oeil, Malbec-Tannat, Carignan, Colombard-Ugni Blanc, Sémillon, Syrah-Grenache, Sciaccerellu, Auxerrois, Mourvèdre, Tannat-Cabernet Franc, Braucol, Trousseau, Merlot-Cabernet Sauvignon.\n \n What is the likely grape variety? Answer only with the grape variety name or blend from the list.\n '