在浩瀚信息中寻找相关内容有时就像大海捞针,但别灰心,GPTs其实可以帮我们完成大部分工作。本指南探讨了一种利用多种AI技术增强现有搜索系统的方法,帮助我们过滤噪音信息。
GPT检索信息的两种方式为:
- 模拟人类浏览行为: GPT触发搜索,评估结果,并在必要时修改搜索查询。它还可以跟进特定的搜索结果,形成类似人类用户的思维链。
- 基于嵌入的检索: 为你的内容和用户查询计算嵌入向量,然后通过余弦相似度度量检索出最相关的内容。这项技术被谷歌等搜索引擎广泛使用。
These approaches are both promising, but each has their shortcomings: the first one can be slow due to its iterative nature and the second one requires embedding your entire knowledge base in advance, continuously embedding new content and maintaining a vector database.
通过结合这些方法,并从重新排序技术中汲取灵感,我们找到了一种折中方案。这种方法可以在任何现有搜索系统之上实现,例如Slack搜索API,或是包含私有数据的内部ElasticSearch实例。其工作原理如下:
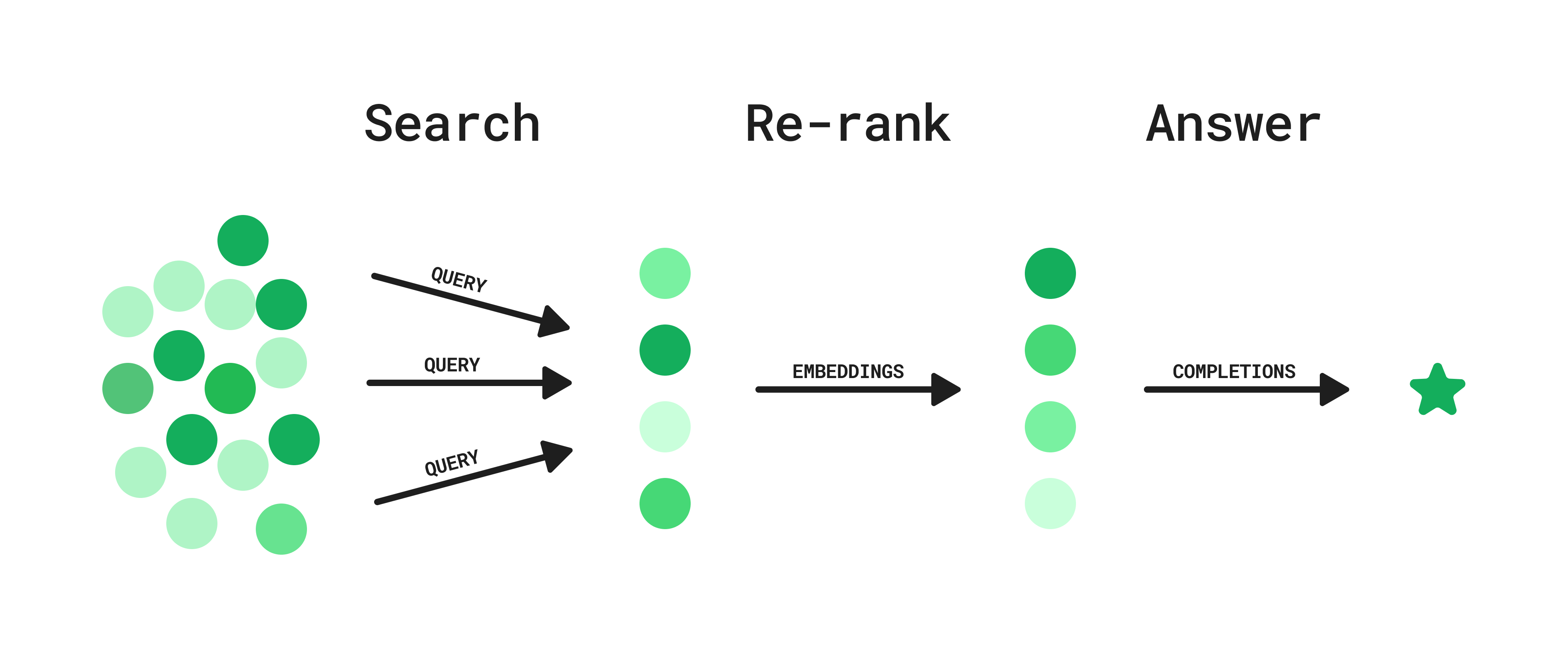
步骤1:搜索
- 用户提出一个问题。
- GPT生成一系列潜在的查询。
- 搜索查询是并行执行的。
步骤2:重新排序
- 每个结果的嵌入向量用于计算与用户问题生成的假设理想答案之间的语义相似度。
- 结果根据此相似度指标进行排序和筛选。
步骤3:回答
- 根据搜索结果,模型会生成用户问题的答案,包括参考文献和链接。
这种混合方法提供了相对较低的延迟,并且可以集成到任何现有的搜索端点中,无需维护向量数据库。让我们深入了解它!我们将以News API为例进行搜索。
设置
除了你的OPENAI_API_KEY外,你还需要在环境中包含一个NEWS_API_KEY。你可以在此获取API密钥。