概述
通过将Responses API与OpenAI最新的推理模型相结合,您可以在应用中解锁更高的智能水平、更低的成本以及更高效的token使用。该API还支持访问推理摘要、托管工具使用等功能,并且设计上能够适应未来的增强功能,以实现更大的灵活性和性能提升。
通过将Responses API与OpenAI最新的推理模型相结合,您可以在应用中解锁更高的智能水平、更低的成本以及更高效的token使用。该API还支持访问推理摘要、托管工具使用等功能,并且设计上能够适应未来的增强功能,以实现更大的灵活性和性能提升。
我们最近发布了两款最先进的推理模型o3和o4-mini,它们擅长将推理能力与智能体工具使用相结合。许多人不知道的是,通过充分利用我们(相对)新的Responses API可以提升它们的性能。本指南展示了如何充分发挥这些模型的潜力,并探讨了推理和函数调用背后的工作原理。通过让模型访问之前的推理项,我们可以确保它以最高智能和最低成本运行。
我们通过单独的cookbook和API reference介绍了Responses API。主要亮点:Responses API与Completions API类似,但进行了改进并增加了功能。我们还为Responses推出了加密内容,这使得那些无法以有状态方式使用API的用户能获得更大帮助!
在深入了解Responses API如何提供帮助之前,让我们快速回顾一下推理模型的工作原理。像o3和o4-mini这样的模型会逐步分解问题,生成编码其推理过程的内部思维链。出于安全考虑,这些推理标记仅以摘要形式向用户展示。
在多轮对话中,每轮交互后推理标记会被丢弃,而每一步的输入和输出标记会传递到下一轮
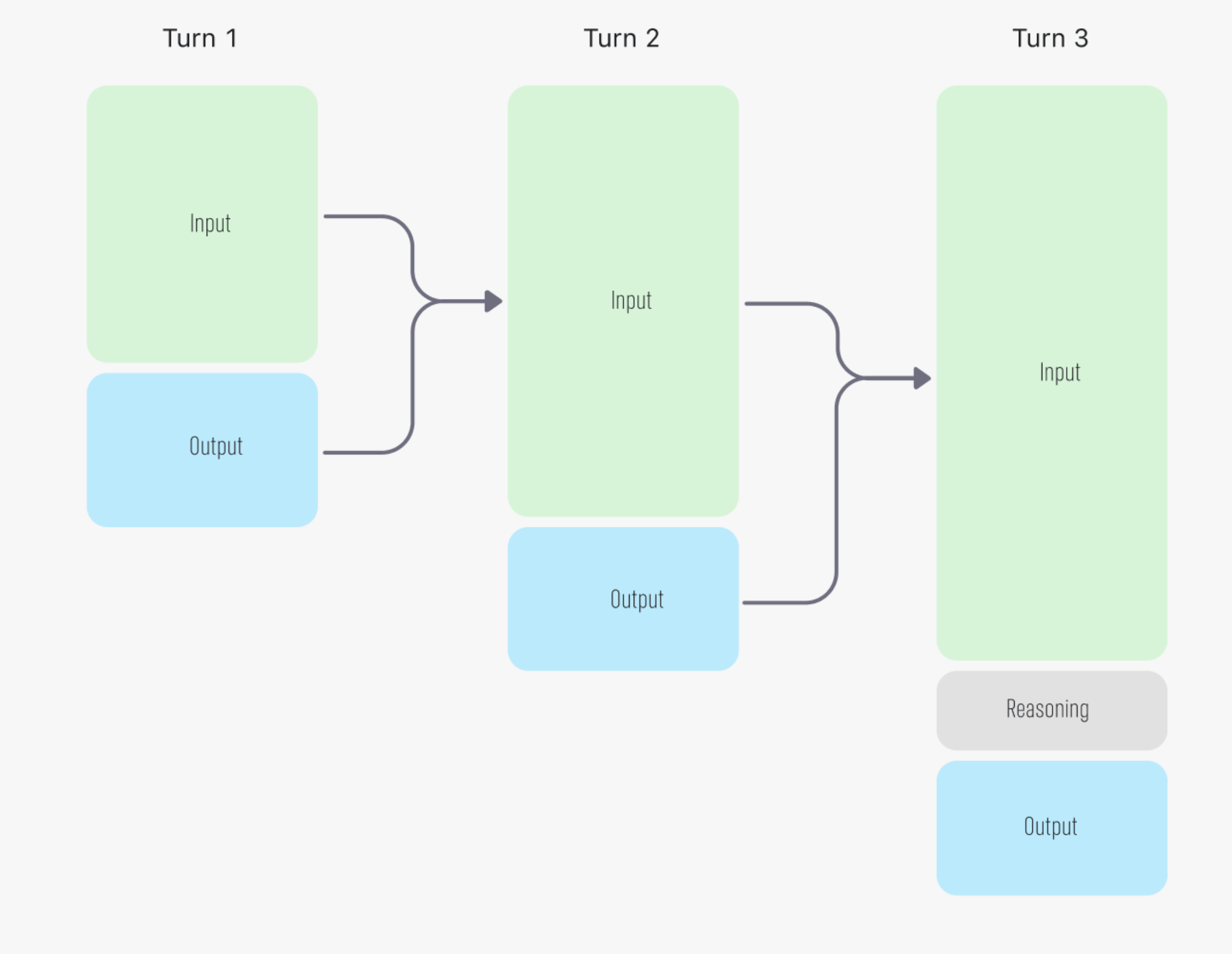 图表引用自我们的文档
图表引用自我们的文档
让我们检查返回的响应对象:
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))response = client.responses.create(
model="o4-mini",
input="tell me a joke",
)
import json
print(json.dumps(response.model_dump(), indent=2))
{
"id": "resp_6820f382ee1c8191bc096bee70894d040ac5ba57aafcbac7",
"created_at": 1746989954.0,
"error": null,
"incomplete_details": null,
"instructions": null,
"metadata": {},
"model": "o4-mini-2025-04-16",
"object": "response",
"output": [
{
"id": "rs_6820f383d7c08191846711c5df8233bc0ac5ba57aafcbac7",
"summary": [],
"type": "reasoning",
"status": null
},
{
"id": "msg_6820f3854688819187769ff582b170a60ac5ba57aafcbac7",
"content": [
{
"annotations": [],
"text": "Why don\u2019t scientists trust atoms? \nBecause they make up everything!",
"type": "output_text"
}
],
"role": "assistant",
"status": "completed",
"type": "message"
}
],
"parallel_tool_calls": true,
"temperature": 1.0,
"tool_choice": "auto",
"tools": [],
"top_p": 1.0,
"max_output_tokens": null,
"previous_response_id": null,
"reasoning": {
"effort": "medium",
"generate_summary": null,
"summary": null
},
"status": "completed",
"text": {
"format": {
"type": "text"
}
},
"truncation": "disabled",
"usage": {
"input_tokens": 10,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens": 148,
"output_tokens_details": {
"reasoning_tokens": 128
},
"total_tokens": 158
},
"user": null,
"service_tier": "default",
"store": true
}
从响应对象的JSON转储中可以看到,除了output_text外,模型还会生成一个推理项。该项代表模型的内部推理令牌,并以ID形式暴露——例如这里的rs_6820f383d7c08191846711c5df8233bc0ac5ba57aafcbac7。由于Responses API是有状态的,这些推理令牌会持续存在:只需在后续消息中包含它们的ID,就能让未来的响应访问相同的推理项。如果在多轮对话中使用previous_response_id,模型将自动获得所有先前生成的推理项的访问权限。
您还可以查看模型生成了多少推理令牌。例如,输入10个令牌时,响应包含148个输出令牌——其中128个是未显示在最终助手消息中的推理令牌。
等等——之前的示意图不是显示前几轮的推理会被丢弃吗?那为什么还要在后续轮次中传回这些信息呢?
好问题!在典型的多轮对话中,您不需要包含推理项或标记——模型经过训练可以在没有它们的情况下产生最佳输出。但是,当涉及工具使用时情况会有所不同。如果某轮对话包含函数调用(可能需要在API之外进行额外往返),您确实需要通过previous_response_id或显式地将推理项添加到input中来包含推理项。让我们通过一个快速函数调用示例看看这是如何工作的。
import requests
def get_weather(latitude, longitude):
response = requests.get(f"https://api.open-meteo.com/v1/forecast?latitude={latitude}&longitude={longitude}¤t=temperature_2m,wind_speed_10m&hourly=temperature_2m,relative_humidity_2m,wind_speed_10m")
data = response.json()
return data['current']['temperature_2m']
tools = [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"}
},
"required": ["latitude", "longitude"],
"additionalProperties": False
},
"strict": True
}]
context = [{"role": "user", "content": "What's the weather like in Paris today?"}]
response = client.responses.create(
model="o4-mini",
input=context,
tools=tools,
)
response.output[ResponseReasoningItem(id='rs_68210c71a95c81919cc44afadb9d220400c77cc15fd2f785', summary=[], type='reasoning', status=None),
ResponseFunctionToolCall(arguments='{"latitude":48.8566,"longitude":2.3522}', call_id='call_9ylqPOZUyFEwhxvBwgpNDqPT', name='get_weather', type='function_call', id='fc_68210c78357c8191977197499d5de6ca00c77cc15fd2f785', status='completed')]经过一番推理后,o4-mini模型确定需要更多信息并调用函数来获取。我们可以调用该函数并将其输出返回给模型。关键的是,为了最大化模型的智能,我们应该通过简单地将所有输出重新加入下一轮上下文来保留推理项。
context += response.output # Add the response to the context (including the reasoning item)
tool_call = response.output[1]
args = json.loads(tool_call.arguments)
# calling the function
result = get_weather(args["latitude"], args["longitude"])
context.append({
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": str(result)
})
# we are calling the api again with the added function call output. Note that while this is another API call, we consider this as a single turn in the conversation.
response_2 = client.responses.create(
model="o4-mini",
input=context,
tools=tools,
)
print(response_2.output_text)The current temperature in Paris is 16.3°C. If you’d like more details—like humidity, wind speed, or a brief description of the sky—just let me know!
虽然这个简单的示例可能无法清晰地展示其优势——因为无论是否包含推理项,模型的表现都可能不错——但我们自己的测试发现情况并非如此。在像SWE-bench这样更严格的基准测试中,包含推理项使得相同提示和设置下的性能提升了约3%。
如上所示,推理模型会生成推理令牌和完成令牌,API对它们的处理方式不同。这种区别会影响缓存的工作机制,并对性能和延迟产生影响。下图展示了这些概念:
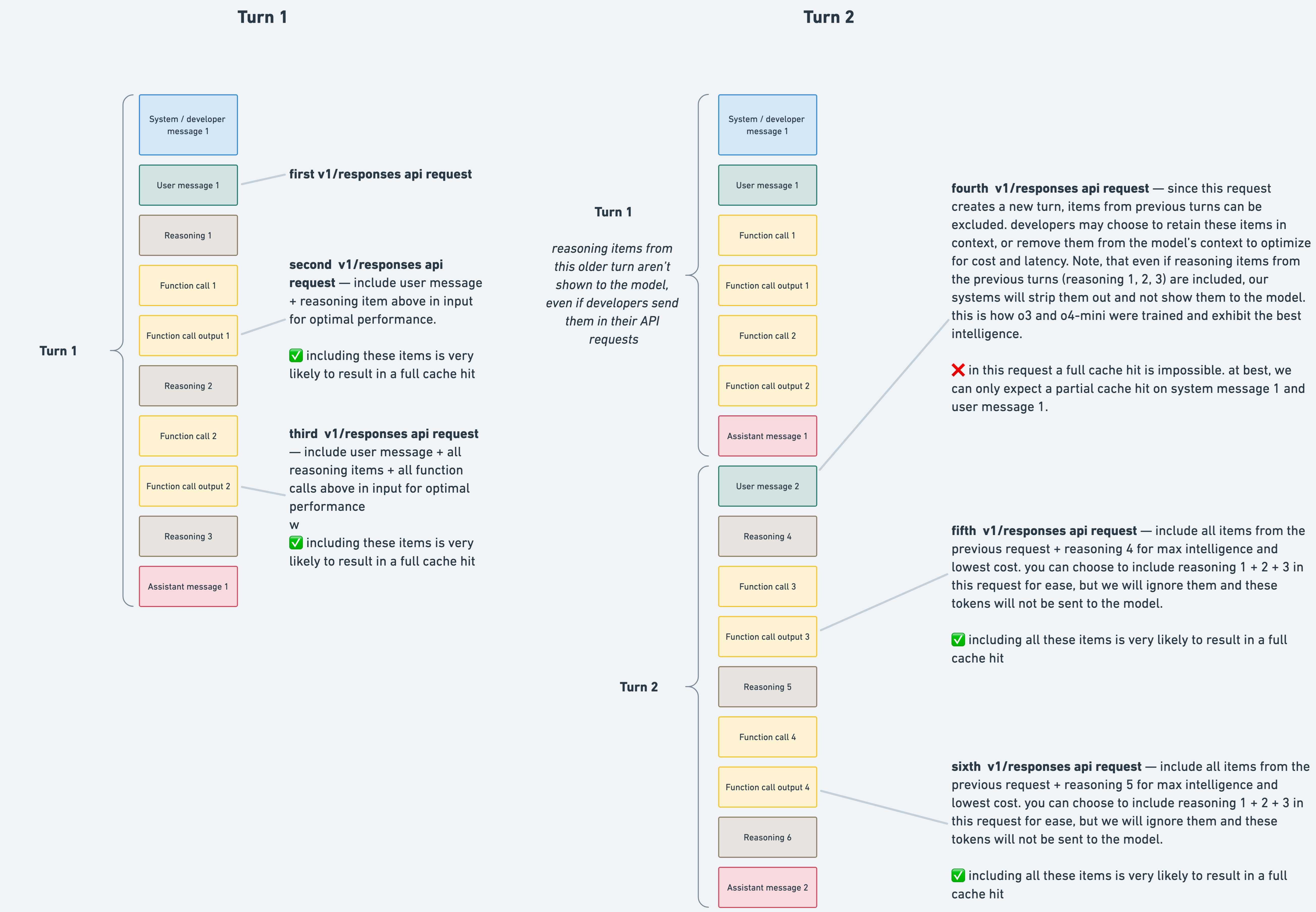
在第2轮中,第1轮的任何推理项都会被忽略并移除,因为模型不会复用之前轮次的推理项。因此,图中第四个API调用无法实现完全缓存命中,因为这些推理项在提示中缺失。不过包含它们并无害处——API会直接丢弃与当前轮次无关的推理项。请注意缓存仅影响超过1024个标记的提示。在我们的测试中,从Completions API切换到Responses API将缓存利用率从40%提升至80%。更高的缓存利用率可降低成本(例如o4-mini的缓存输入标记比未缓存标记便宜75%)并改善延迟。
某些组织——例如那些有零数据保留(ZDR)要求的机构——由于合规性或数据保留政策,无法以有状态方式使用响应API。为支持这些情况,OpenAI提供加密推理项,使您能在保持工作流无状态的同时,仍能受益于推理项。
使用加密推理项:
["reasoning.encrypted_content"]添加到include字段。对于ZDR组织,OpenAI会自动强制执行store=false。当请求包含encrypted_content时,内容会在内存中解密(绝不会写入磁盘),用于生成下一个响应后即被安全丢弃。所有新生成的分析令牌会立即加密并返回给您,确保中间状态永远不会被持久化。
以下是一个快速代码更新,展示其工作原理:
context = [{"role": "user", "content": "What's the weather like in Paris today?"}]
response = client.responses.create(
model="o3",
input=context,
tools=tools,
store=False, #store=false, just like how ZDR is enforced
include=["reasoning.encrypted_content"] # Encrypted chain of thought is passed back in the response
)# take a look at the encrypted reasoning item
print(response.output[0]) ResponseReasoningItem(id='rs_6821243503d481919e1b385c2a154d5103d2cbc5a14f3696', summary=[], type='reasoning', status=None, encrypted_content='gAAAAABoISQ24OyVRYbkYfukdJoqdzWT-3uiErKInHDC-lgAaXeky44N77j7aibc2elHISjAvX7OmUwMU1r7NgaiHSVWL5BtWgXVBp4BMFkWZpXpZY7ff5pdPFnW3VieuF2cSo8Ay7tJ4aThGUnXkNM5QJqk6_u5jwd-W9cTHjucw9ATGfGqD2qHrXyj6NEW9RmpWHV2SK41d5TpUYdN0xSuIUP98HBVZ2VGgD4MIocUm6Lx0xhRl9KUx19f7w4Sn7SCpKUQ0zwXze8UsQOVvv1HQxk_yDosbIg1SylEj38H-DNLil6yUFlWI4vGWcPn1bALXphTR2EwYVR52nD1rCFEORUd7prS99i18MUMSAhghIVv9OrpbjmfxJh8bSQaHu1ZDTMWcfC58H3i8KnogmI7V_h2TKAiLTgSQIkYRHnV3hz1XwaUqYAIhBvP6c5UxX-j_tpYpB_XCpD886L0XyJxCmfr9cwitipOhHr8zfLVwMI4ULu-P3ftw7QckIVzf71HFLNixrQlkdgTn-zM6aQl5BZcJgwwn3ylJ5ji4DQTS1H3AiTrFsEt4kyiBcE2d7tYA_m3G8L-e4-TuTDdJZtLaz-q8J12onFaKknGSyU6px8Ki4IPqnWIJw8SaFMJ5fSUYJO__myhp7lbbQwuOZHIQuvKutM-QUuR0cHus_HtfWtZZksqvVCVNBYViBxD2_KvKJvR-nN62zZ8sNiydIclt1yJfIMkiRErfRTzv92hQaUtdqz80UiW7FBcN2Lnzt8awXCz1pnGyWy_hNQe8C7W35zRxJDwFdb-f3VpanJT0tNmU5bfEWSXcIVmiMZL1clwzVNryf9Gk482LaWPwhVYrhv2MkhKMPKdeAZWVhZbgm0eTT8a4DgbwcYRGhoXMGxrXWzOdvAY536DkrI_0xsJk8-Szb5Y2EH0xPxN4-CdB_fMPP60TPEQTOP1Qc64cJcQ9p2JE5Jfz59bubF_QGajC9-FtHkD6Q5pT-6CbhuD6xrFJMgxQPcggSDaWL_4260fZCdf6nzMlwPRD3wrfsxs6rFyd8pLC-2SOh9Iv297xAjes8xcnyqvMKSuCkjARr11gJCe0EXnx87NWt2rfW8ODUU0qFYbjFx8Rj9WJtnvQBNyqp7t5LLLf12S8pyyeKTv0ePqC3xDuWdFKmELDUZjarkkCyMHoO12EbXa6YCpY_MpA01c2vV5plrcouVPSwRK0ahbPs0mQnQnDAkfi2XVS0Bzgk2GpNONGf7KWkzD7uTgDtg9UbWI0v_-f-iiBM2kKDz_dIb1opZfaxZEloyiQ2MnWQj2MRefL7WM_0c3IyTAccICN-diGn2f1im82uL9maELcbYn')
设置include=["reasoning.encrypted_content"]后,我们现在可以看到推理项中传回的encrypted_content字段。这个加密内容代表模型的推理状态,完全保存在客户端,OpenAI不保留任何数据。然后我们可以像之前处理推理项一样将其传回。
context += response.output # Add the response to the context (including the encrypted chain of thought)
tool_call = response.output[1]
args = json.loads(tool_call.arguments)
result = 20 #mocking the result of the function call
context.append({
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": str(result)
})
response_2 = client.responses.create(
model="o3",
input=context,
tools=tools,
store=False,
include=["reasoning.encrypted_content"]
)
print(response_2.output_text)It’s currently about 20 °C in Paris.
只需简单修改include字段,我们现在就可以传回加密的推理项,并利用它来提升模型在智能性、成本和延迟方面的表现。
现在您应该已经掌握了充分利用我们最新推理模型所需的所有知识!
Responses API 另一个实用功能是支持推理摘要。虽然我们不公开原始的思维链标记,但用户可以访问其摘要。
# Make a hard call to o3 with reasoning summary included
response = client.responses.create(
model="o3",
input="What are the main differences between photosynthesis and cellular respiration?",
reasoning={"summary": "auto"},
)
# Extract the first reasoning summary text from the response object
first_reasoning_item = response.output[0] # Should be a ResponseReasoningItem
first_summary_text = first_reasoning_item.summary[0].text if first_reasoning_item.summary else None
print("First reasoning summary text:\n", first_summary_text)
First reasoning summary text: **Analyzing biological processes** I think the user is looking for a clear explanation of the differences between certain processes. I should create a side-by-side comparison that lists out key elements like the formulas, energy flow, locations, reactants, products, organisms involved, electron carriers, and whether the processes are anabolic or catabolic. This structured approach will help in delivering a comprehensive answer. It’s crucial to cover all aspects to ensure the user understands the distinctions clearly.
推理摘要文本让用户能够一窥模型的思考过程。例如,在涉及多个函数调用的对话中,用户无需等待最终的助手消息,就能看到调用了哪些函数以及每次调用的推理依据。这为您的应用程序用户体验增添了透明度和互动性。
通过利用OpenAI Responses API和最新的推理模型,您可以在应用中解锁更高的智能水平、更强的透明度以及更优的效率。无论是使用推理摘要、为合规性加密推理项,还是针对成本和延迟进行优化,这些工具都能帮助您构建更强大、更具交互性的人工智能体验。
祝您构建愉快!