模型介绍
流式 DeepSpeech2
实现的 Deepspeech2 在线模型架构基于 Deepspeech2 model 并做了一些改动。模型主要由 2D 卷积下采样层和堆叠的单向 RNN 层组成。
为了清晰地说明模型实现,详细描述了三个部分。
数据准备
编码器
解码器
此外,训练过程和测试过程也进行了介绍。
模型的架构如图1所示。
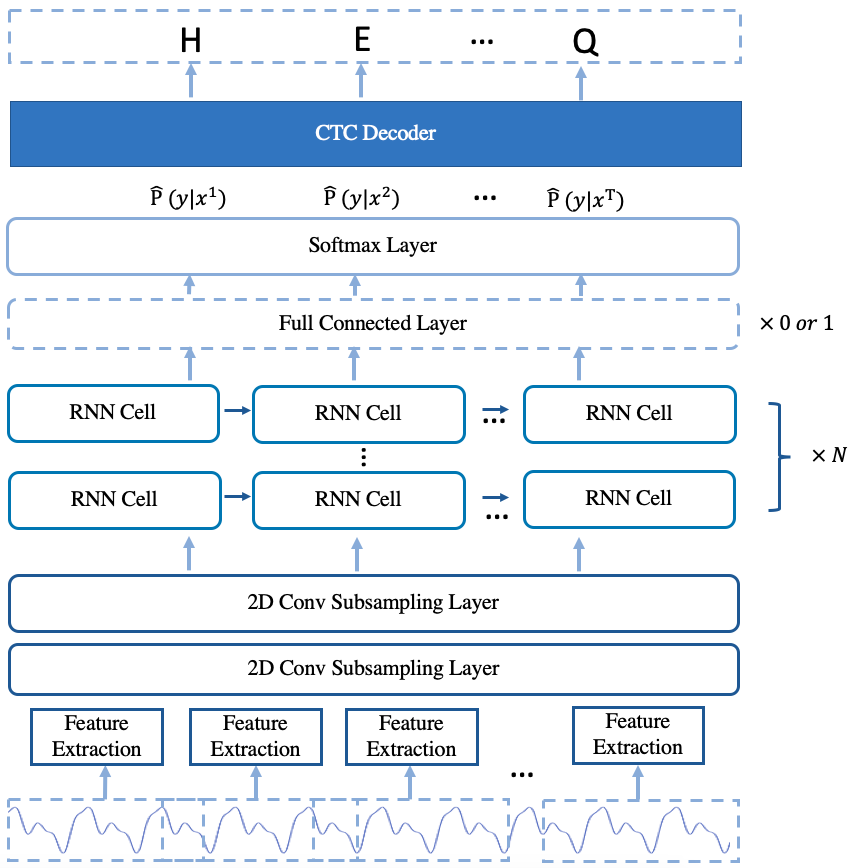
图1 deepspeech2 在线模型的架构
数据准备
词汇
对于英语数据,词汇字典由26个英文字母组成,包括" ' "、空格、
# The code to build vocabulary
cd examples/aishell/s0
python3 ../../../utils/build_vocab.py \
--unit_type="char" \
--count_threshold=0 \
--vocab_path="data/vocab.txt" \
--manifest_paths "data/manifest.train.raw" "data/manifest.dev.raw"
# vocabulary for aishell dataset (Mandarin)
vi examples/aishell/s0/data/vocab.txt
# vocabulary for librispeech dataset (English)
vi examples/librispeech/s0/data/vocab.txt
CMVN
对于CMVN,选择部分或全部训练集来计算特征的均值和标准差。
# The code to compute the feature mean and std
cd examples/aishell/s0
python3 ../../../utils/compute_mean_std.py \
--manifest_path="data/manifest.train.raw" \
--spectrum_type="linear" \
--delta_delta=false \
--stride_ms=10.0 \
--window_ms=20.0 \
--sample_rate=16000 \
--use_dB_normalization=True \
--num_samples=2000 \
--num_workers=10 \
--output_path="data/mean_std.json"
特征提取
对于特征提取,实施了三种方法,分别是线性(不使用滤波器组的FFT)、滤波器组和MFCC。 目前,发布的deepspeech2在线模型使用线性特征提取方法。
The code for feature extraction
vi paddlespeech/s2t/frontend/featurizer/audio_featurizer.py
编码器
编码器由两个2D卷积下采样层和几个堆叠的单向rnn层组成。2D卷积下采样层从原始音频特征中提取特征表示,同时减少音频特征的长度。经过卷积下采样层后,特征表示被输入到堆叠的rnn层中。对于堆叠的rnn层,可以使用LSTM单元和GRU单元。在堆叠的rnn层后添加一个全连接(fc)层是可选的。如果堆叠的rnn层数量少于5,建议在堆叠的rnn层后添加一个fc层。
编码器的代码在:
vi paddlespeech/s2t/models/ds2_online/deepspeech2.py
解码器
要获取每个帧的字符可能性,编码器输出的每个帧的特征表示被输入到一个被实现为密集层的投影层中以进行特征投影。投影层的输出维度与词汇大小相同。在投影层之后,使用softmax函数将帧级特征表示转换为字符的可能性。在进行模型推断时,每个帧的字符可能性被输入到CTC解码器以获得最终的语音识别结果。
解码器的代码在:
# The code of constructing the decoder in model
vi paddlespeech/s2t/models/ds2_online/deepspeech2.py
# The code of CTC Decoder
vi paddlespeech/s2t/modules/ctc.py
训练过程
使用下面的命令,您可以训练deepspeech2在线模型。
cd examples/aishell/s0
bash run.sh --stage 0 --stop_stage 2 --model_type online --conf_path conf/deepspeech2_online.yaml
详细命令如下:
# The code for training in the run.sh
set -e
source path.sh
gpus=2,3,5,7
stage=0
stop_stage=5
conf_path=conf/deepspeech2_online.yaml # conf/deepspeech2.yaml | conf/deepspeech2_online.yaml
avg_num=1
model_type=online # online | offline
source ${MAIN_ROOT}/utils/parse_options.sh || exit 1;
avg_ckpt=avg_${avg_num}
ckpt=$(basename ${conf_path} | awk -F'.' '{print $1}')
echo "checkpoint name ${ckpt}"
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
# prepare data
bash ./local/data.sh || exit -1
fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `exp` dir
CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${ckpt} ${model_type}
fi
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
# avg n best model
avg.sh exp/${ckpt}/checkpoints ${avg_num}
fi
通过使用上述命令,可以开始训练过程。"run.sh"中有5个阶段,前3个阶段用于训练过程。阶段0用于数据准备,在此阶段数据集将被下载,并在"./data/"中生成数据集的清单文件、词汇字典和CMVN文件。阶段1用于训练模型,日志文件和模型检查点保存于"exp/deepspeech2_online/"。阶段2用于通过基于验证损失的top-k模型参数平均生成最终模型以进行预测。
测试过程
使用下面的命令,您可以测试 deepspeech2 在线模型。
bash run.sh --stage 3 --stop_stage 5 --model_type online --conf_path conf/deepspeech2_online.yaml
详细命令如下:
conf_path=conf/deepspeech2_online.yaml
avg_num=1
model_type=online
avg_ckpt=avg_${avg_num}
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# test ckpt avg_n
CUDA_VISIBLE_DEVICES=2 ./local/test.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} ${model_type}|| exit -1
fi
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
# export ckpt avg_n
CUDA_VISIBLE_DEVICES=5 ./local/export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt} exp/${ckpt}/checkpoints/${avg_ckpt}.jit ${model_type}
fi
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
# test export ckpt avg_n
CUDA_VISIBLE_DEVICES=0 ./local/test_export.sh ${conf_path} exp/${ckpt}/checkpoints/${avg_ckpt}.jit ${model_type}|| exit -1
fi
在训练过程后,我们使用阶段3、4、5进行测试过程。阶段3用于测试在阶段2生成的模型,并提供测试集的CER指数。阶段4用于通过使用“paddle.jit”库将模型从动态图转换为静态图。阶段5用于在静态图中测试模型。
非流式 DeepSpeech2
deepspeech2离线模型类似于deepspeech2在线模型。它们之间的主要区别在于,离线模型使用堆叠的双向RNN层,而在线模型使用单向RNN层,并且不使用全连接层。对于离线模型中的堆叠双向RNN层,提供了可以使用的RNN单元和GRU单元。
模型的结构如图2所示。
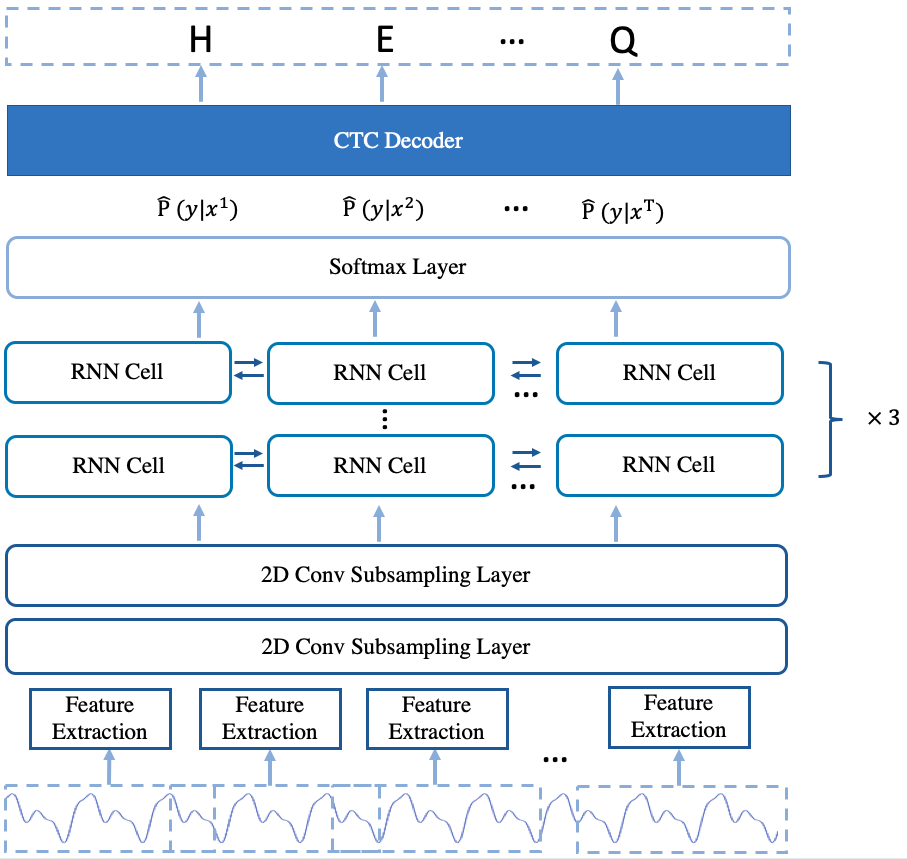
图2 deepspeech2 离线模型的架构
对于数据准备和解码器,deepspeech2 离线模型与 deepspeech2 在线模型相同。
deepspeech2 离线模型的编码器和解码器代码在:
vi paddlespeech/s2t/models/ds2/deepspeech2.py
deepspeech2离线模型的训练过程和测试过程与deepspeech2在线模型非常相似。 只需注意一些变化。
训练和测试时,必须设置"model_type"和"conf_path"。
# Training offline
cd examples/aishell/s0
bash run.sh --stage 0 --stop_stage 2 --model_type offline --conf_path conf/deepspeech2.yaml
# Testing offline
cd examples/aishell/s0
bash run.sh --stage 3 --stop_stage 5 --model_type offline --conf_path conf/deepspeech2.yaml